 Roy Longbottom's Raspberry Pi, Pi 2 and Pi 3 Benchmarks
Roy Longbottom's Raspberry Pi, Pi 2 and Pi 3 Benchmarks
NewI have now run my 32 bit and 64 bit Raspberry Pi benchmarks and stress tests on the model 3B+. Full details and results are available in Raspberry Pi 3B+ 32 bit and 64 bit Benchmarks and stress tests.htm The tests demonstrate 3B+/3B performance improvements (not always), the new thermal characteristics and higher speed LAN and WiFi data transfers.ContentsGeneralRoy Longbottom’s PC Benchmark Collection comprises numerous FREE benchmarks and reliability testing programs, for processors, caches, memory, buses, disks, flash drives, graphics, local area networks and Internet. Original ones run via DOS and later versions under all varieties of Windows. Most have also been converted to run under Linux on PCs. and many to run via Android on tablets and phones. Some of the Linux variety C/C++ source code was changed slightly to compile for execution on the Raspberry Pi. After reading that compilation time on the Raspberry Pi was painfully slow, the programs were compiled on a Linux Ubuntu 12.04 based PC via Rasbian Toolchain using instructions downloaded from www.xappsoftware.com. This allows programs to be compiled from a Terminal window. Using this, the C/C++ code can be firstly compiled to run on the Linux driven PC, then transferred to the Raspberry Pi via LAN or a USB flash drive. In order to execute after transferring, a change to Properties, Permissions is needed to make executable. One complication is that setting the path to the cross compiler did not work as suggested by xappsoftware. Below are examples of commands used for the two executable files - note the path for gcc:
cc whets.c cpuidc.c -lm -O3 -o whetstoneIL
~/toolchain/raspbian-toolchain-gcc-4.7.2-linux32/bin/arm-linux-gnueabihf-gcc whets.c
cpuidc.c -lm -O3 -march=armv6 -mfloat-abi=hard -mfpu=vfp -o whetstonePiA6
Command to execute - ./whetstonePiA6
The last three parameters (-march to -mfpu) made no difference to performance, but others are likely to be needed to take advantage of later ARM floating point functions.
Note, the first four benchmark programs were compiled later on the Raspberry Pi itself. Both the above cc and gcc (with no Toolchain path) commands were used for compilation. These and the PC based files all produced the same numeric results and mainly the same performance. Compilation time was acceptable at between 8 and 36 seconds.
The benchmarks and source codes can be downloaded in Raspberry_Pi_Benchmarks.zip. This includes the executables compiled, as above, to run on Intel CPUs via Linux and the versions compiled on the Raspberry Pi. To download the benchmarks, click on the Raspberry_Pi_Benchmarks.zip link, select Save to download to Home (assume /home/pi). Open File Manager and right click on zip file and select Extract here. To enable execution of the programs, a security setting is required. Double click on Raspberry_Pi_Benchmarks folder to open, right click on each executable (dhrystonePiA6, linpackPiA6, linpackPiSP, liverloopsPiA6, memspeedPiA6, whetstonePiA6), select Properties, Permissions, tick Make the file executable. The new program titles mainly end in PiA7. To run, open LX Terminal, type cd Raspberry_Pi_Benchmarks to enter the directory, type ls to ensure the path is correct and to list files, then execute for example using ./dhrystonePiA6. Information will be displayed as the benchmarks are running and results will be saved in log files, example Dhry.txt.
Raspberry Pi SystemFor those who do not know, the Raspberry Pi has a 3.5 x 2.5 inch motherboard, in this case, containing a 700 MHz ARM 1176JZF v6 single core CPU and 512 MB RAM. External connectors include two full size USB sockets with others for a full size HDMI plug, a micro USB socket for power, an RJ45 Ethernet port and a slot for an SD card, used as the main drive. The operating system is Raspbian, based on Linux Debian, in ths case Wheezy-Raspbian. This can be obtained pre-loaded on an SD card or downloaded from raspberrypi.org and copied to an SD card to produce a bootable drive. I used Image Writer for Microsoft Windows for this purpose. In my case, booting time, from connecting power to desktop display, is 30 seconds. Using a simple command (see below) produces a menu where CPU speed can be selected up to 1 GHz, also increasing memory bus speed. Raspberry Pi 2 Model B has a 900 MHz quad core Broadcom BCM2836 ARM V7 CPU with 1 GB RAM and can be overclocked to 1 GHz, using the configuration menu. L1 data cache size is 32 KB and L2 cache 512 KB, shared by all cores. Existing benchmarks were run on the new computer along with additional programs, produced by a newer compiler, to see if additional hardware features were used. The additional benchmarks were produced using gcc 4.8, where a typical compile command is: gcc whets.c cpuidc.c -lm -O3 -mcpu=cortex-a7 -mfpu=neon-vfpv4 -mfloat-abi=hard -o newA7 Raspberry Pi 3 Model B includes a quad core Broadcom BCM2837 system-on-chip running at 1200 MHz, each core having a 32 KB L1 cache. There is a shared 512 KB L2 cache and 1 GB RAM. The CPU is an ARM Cortex-A53, capable of 64 bit working, but presently only supports 32 bit operation. Benchmark results are now included. Performance of a Cortex-A53 based Android tablet is available, for the same benchmarks, at both 32 bit and 64 bit working. These results are included below, to identify potential differences at 64 bits.
64 Bit OpenSUSE and Gentoo For Raspberry Pi 3Up until late 2016, readily available operating systems have been 32 bit versions. The first reference I have seen, for a 64 bit variety, was for OpenSUSE for Raspberry Pi 3.. There are different distros available, one for SUSE Linux Enterprise Server (SLES). A number of free OpenSUSE downloads are for both Leap 42.2 and Tumbleweed versions. Registration is required for SLES, with free use for at least a year. All downloads are raw.xz compressed files. Converting the xz files to successfully bootable SD cards can be difficult. I had to extract the raw files on a PC using Linux Ubuntu and copy them to the card via Windows, using Win32 Disk Imager. I managed to produce working systems for Leap 42.2 but not Tumbleweed. I installed GCC-6. That produced what appeared to be good 64 bit code (from disassembly), but performance was variable. This was due to a default “on demand” boot setting that produced variable CPU MHz. In order to understand the implications of this, I compiled and ran some MP tests, details of which are in SUSE RPi3 Stress Tests.htm. Some benchmarks were also compiled by gcc 4.8, using 64 bit SLES, to explore performance differences between 32 bit and 64 bit working. The benchmarks and source codes are being included in
Rpi3-64-Bit-Benchmarks.tar.gz.
The source codes include the compile and link commands used, an example being below.
Linux Gentoo - Details of a bootable 64-bit Gentoo image for the Raspberry Pi 3 became available in February 2017. Details and downloads are available from Rpi3-64-Bit-Benchmarks.tar.gz. The bootable SD card was created as for OpenSUSE above. The OpenSUSE produced benchmarks are being run via Gentoo and, where appropriate, results included below. This time, although “on demand” CPU MHz was used, benchmarks consistently ran at full speed, with lower MHz only being shown when the CPU was idle.
Standards/Configuration DetailsAll the benchmarks are run from Terminal commands and provide continuous displays of current activity. This was included in original versions of the benchmarks when CPUs were really slow. They all produce a summary of results in a .txt based log file and this includes system information, where the following example is for my particular system. Note that this includes the meaningless BogoMIPS measurement that does not change when the processor is overclocked. Raspberry Pi 2 has additional features such as neon, vfpv3 and vfpv4. SUSE and Gentoo for Raspberry Pi 3 - CPU architecture: 8 identifies 64 bit working. The programs provide keyboard input at the end to include comments in the log, such as "overclocked at 1000 MHz". The source code has expected numeric answers, selected for particular hardware. These are checked for correctness and errors reported in the log. Running on a variation of the hardware could produce false error reports for floating point calculations. Also shown below is the command to select the menu with the overclocking option and commands to obtain CPU MHz and these do not change when the CPU is overclocked.
Whetstone Benchmark - whetstonePiA6, whetstonePiA7, whetstonePi64See Comparisons BelowThe Whetstone Benchmark was the first general purpose benchmark that set industry standards of performance, particularly for minicomputers, and introduced in 1972. The benchmark produced speed ratings in terms of Thousands of Whetstone Instructions Per Second (KWIPS). In 1978, self timing versions (by yours truly) produced speed ratings, for each of the eight test procedures, in MOPS (Millions of Operations Per Second) or MFLOPS (Millions of Floating Point Operations Per Second), with an overall rating in MWIPS, mainly dependent on floating point speed. Unlike some other floating point benchmarks, the new PiA7 compilation produces identical numeric results to those below. Besides the logged results, other information, shown below, is displayed on the Terminal, particularly for calibrating to run for a total of about 10 seconds. The time for each test identifies what determines the overall MWIPS rating. It now depends on those with mathematical functions but was N6 floating point originally.
Whetstone Benchmark ComparisonsResults below are for the Raspberry Pi running at 700 MHz and overclocked at 1000 MHz. For comparison purposes, also shown are speeds obtained on various Android based ARM CPUs and Intel processors running under Linux, compiled as above. The latter are similar to those from my earlier Linux benchmarks. Results on many more systems are in Whetstone Results.htm with speeds of ancient computers in Whetstone Benchmark History and Results. Raspberry Pi 2, with default settings, is just over twice as fast as the original, on average, or 57% faster at 1000 MHz. Performance via gcc 4.8 can be slightly slower than the earlier benchmarks. The programming code used is not really suitable to produce performance gains through advanced instructions. This benchmark is particularly sensitive to optimisation in compiling the COS and EXP function tests that can determine the overall MWIPS rating. The other main influence is the third MFLOPS measurement. On all fronts, the Raspberry Pi 3 performance is around 1.33 times that of a non-overclocked Raspberry Pi 2, similar to the CPU MHz ratio. Except for the function tests, other results from the Cortex-A53 based tablet are similar to the Raspberry Pi 3, adjusted for CPU MHz, and that also applies to 32 bit versus 64 bit operation. Much of the similarity is due to execution loops containing few simple instructions. Raspberry Pi 3 SUSE and Gentoo 64 Bits - other than COS and EXP type function tests, speeds were similar to 32 bit version and the Android 64 bit app. With SUSE on-demand CPU frequency, overall MWIPS ratings were 20% to 40% slower.
SUSE and Gentoo MWIPS ratings slightly different, again due to those volatile function test results, with others essentially the same,
as would be expected with the simple processing arrangements. As indicated for the IF test, the compiler detected that it was not necessary to repeat the calculations, but this would make no real difference to MWIPS.
Dhrystone 2 Benchmark - dhrystonePiA6, dhrystonePiA7, dhrystonePi64See Comparisons BelowThe Dhrystone "C" benchmark provides a measure of integer performance (no floating point instructions). It became the key standard benchmark from 1984, with the growth of Unix systems. The first version was produced by Reinhold P. Weicker in ADA and translated to "C" by Rick Richardson. Two versions are available - Dhrystone versions 1.1 and 2.1. The second version, used here, was produced to avoid over-optimisation problems encountered with version 1, but some is still possible. Speed was originally measured in Dhrystones per second. This was later changed to VAX MIPS by dividing Dhrystones per second by 1757, the DEC VAX 11/780 result, the latter being regarded as the first 1 MIPS minicomputer. This again runs for 10 seconds after calibration. In this case, logged results are nanoseconds one Dhrystone run, Dhrystones per Second and VAX MIPS rating plus details of detected errors or “Numeric results were correct?
Below is the execution command and details of displayed information, excluding standard system information.
Dhrystone 2 Benchmark ComparisonsBelow is a similar combination of results as for the Whetstone Benchmark. For results on other systems see Dhrystone Results.htm. Unlike with Whetstones, using floating point calculations, the Raspberry Pi CPU speed is close to ARM Cortex-A9 processors, on a per MHz basis, but executing integer functions. The Raspberry Pi 2 is faster than the first version, performance ratios being shown below. The new gcc 4.8 compilation provides slightly higher speed ratings.The Raspberry Pi 3 averages 45% faster than the Pi 2 on these compilations, compared with a 33% faster CPU MHz. These results are similar to those from the Cortex-A53 based tablet at 64 bits, where optimisation may not have been as good as possible at 32 bits. Raspberry Pi 3 SUSE and Gentoo 64 Bits - Speeds were more than 40% faster than 32 bit system results, and up to 2.95 VAX MIPS (DMIPS) per MHz. Variations between the two 64 bit tests are quite normal.
Considering the worse Android 64 bit performance suggests that the later compiler might be responsible.
Linpack Benchmark 32b - linpackPiA6, linpackPiSP, linpackPiA7, linpackPiA7SP
See Comparisons Below
|
|
|
pi@raspberrypi ~/benchmarks $ ./linpackPiA6
##########################################
Unrolled Double Precision Linpack Benchmark - Linux Version in °C/C++'
Optimisation Opt 3 32 Bit
norm resid resid machep x[0]-1 x[n-1]-1
1.7 7.41628980e-14 2.22044605e-16 -1.49880108e-14 -1.89848137e-14
Times are reported for matrices of order 100
1 pass times for array with leading dimension of 201
dgefa dgesl total Mflops unit ratio
0.00000 0.00000 0.00000 0.00 0.0000 0.0000
Calculating matgen overhead
10 times 0.01 seconds
100 times 0.15 seconds
200 times 0.28 seconds
400 times 0.58 seconds
800 times 1.13 seconds
Overhead for 1 matgen 0.00141 seconds
Calculating matgen/dgefa passes for 1 seconds
10 times 0.17 seconds
20 times 0.35 seconds
40 times 0.69 seconds
80 times 1.38 seconds
Passes used 57
Times for array with leading dimension of 201
dgefa dgesl total Mflops unit ratio
0.01578 0.00053 0.01631 42.11 0.0475 0.2912
0.01596 0.00053 0.01648 41.66 0.0480 0.2943
0.01578 0.00053 0.01631 42.11 0.0475 0.2912
0.01596 0.00053 0.01648 41.66 0.0480 0.2943
0.01578 0.00070 0.01648 41.66 0.0480 0.2943
Average 41.84
Calculating matgen2 overhead
Overhead for 1 matgen 0.00144 seconds
Times for array with leading dimension of 200
dgefa dgesl total Mflops unit ratio
0.01523 0.00053 0.01576 43.58 0.0459 0.2813
0.01540 0.00053 0.01593 43.10 0.0464 0.2845
0.01540 0.00053 0.01593 43.10 0.0464 0.2845
0.01523 0.00070 0.01593 43.10 0.0464 0.2845
0.01523 0.00070 0.01593 43.10 0.0464 0.2845
Average 43.20
Unrolled Double Precision 41.84 Mflops
Type additional information to include in linpack.txt - Press Enter
|
Linpack Benchmark Comparisons
The first Raspberry Pi results do not look too good but they would on a cost/performance basis. Also, the MFLOPS ratings should be compared with Linpack Results on PCs and older mainframes, supercomputers, Unix boxes and minicomputers with Netlib Linpack Results. The Linpack benchmark depends on data in L2 cache and this might lead to variations in running time. Other versions might specify larger array sizes (like 1000 x 1000) that can depend on slower memory.
The Raspberry Pi 2 is faster than the first version, performance ratios being shown below. In this case, the new code from from gcc 4.8 is faster than the original, but only for the double precision benchmark, due to the more efficient instructions shown below. The benchmark has also been compiled to use ARM NEON Single Instruction Multiple Data (SIMD) functions (linpackPiNEONi, linpackPiNEON64), speed being included in the results table. Further details are in a later section.
Based on MFLOPS/MHz, the Raspberry Pi 3 can be slower than the RPi 2, but is quite a bit faster on the NEON version. The Cortex-A53 based tablet 32 bit performance is similar to the RPi 3, but 64 bit working is much faster.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - The measurements for these and the Android 64 bit version, were essentially the same. Speed improvements, over the 32 bit version, were around 1.9 times DP and 2.5 times SP. NEON speeds were not much different, where the intrinsic functions are translated into different variations of vector instructions.
MFLOPS GAIN
System MHz DP SP NEON SP DP SP Against
Raspberry Pi 700 42 58 N/A
Raspberry Pi 1000 68 88 N/A
RPi 2 v7-A7 900 120 156 N/A 2.86 2.69 RPi 700
RPi 2 v7-A7 1000 134 175 N/A 1.97 1.99 RPi 1000
RPi 3 v8-A53 1200 176 190 N/A 1.47 1.22 RPi 2 900
gcc 4.8
RPi 2 v7-A7 900 154 156 300 1.28 1.00 RPi 2 900
RPi 2 v7-A7 1000 169 176 334 1.26 1.01 RPi 2 1000
RPi 3 v8-A53 1200 180 194 486 1.17 1.24 RPi 2 900
gcc-6
64 Bit Working
OpenSuse
RPi 3 v8-A53 1200 348 494 530 1.93 2.55 RPI 3 32b
Gentoo
RPi 3 v8-A53 1200 343 482 521 1.90 2.48 RPI 3 32b
Android
ARM 926EJ 800 6 10 N/A
ARM v7-A9 800 101 129 256
ARM v7-A9 1300 151 201 377
ARM v7-A15 1700 459 803 1335
gcc 4.8
ARM v7-A9 1300 159 200
ARM v7-A15 1700 795 977
ARM v8-A53 1300 178 187 423
64 Bit Version
ARM v8-A53 1300 348 493 521
Linux using CC
Intel Atom 1666 211
Core 2 2400 1631
Linux using older GCC
Intel Atom 1666 196
Core 2 2400 1288
Core i7 3900 2534
|
Livermore Loops Benchmark - liverloopsPiA6, liverloopsPiA7, liverloopsPi64
See Comparisons BelowThis original main benchmark for supercomputers was first introduced in 1970, initially comprising 14 kernels of numerical application, written in Fortran. This was increased to 24 kernels in the 1980s. Performance measurements are in terms of Millions of Floating Point Operations Per Second or MFLOPS. The kernels are executed three times with different double precision data array sizes. Following are overall MFLOPS results for various systems, geometric mean being the official average performance. [Reference - F.H. McMahon, The Livermore Fortran Kernels: A Computer Test Of The Numerical Performance Range, Lawrence Livermore National Laboratory, Livermore, California, UCRL-53745, December 1986]
---------------- MFLOPS ---------------
CPU MHz Maximum Average Geomean Harmean Minimum Measured in
CDC 6600 10 1.1 0.5 0.5 0.4 0.2 1970 *
CDC 7600 36.4 7.3 4.2 3.9 2.5 1.4 1974 *
Cray 1A 80 83.5 25.8 14.4 7.9 2.7 1980 *
Cray 1S 80 82.1 22.2 11.9 6.5 1.0 1985
CDC Cyber 205 50 146.9 36.4 14.6 5.0 0.6 1982 *
Cray 2 244 146.4 36.7 14.2 5.8 1.7 1985
Cray XMP1 105 187.8 61.3 31.5 15.6 3.6 1986
* Fewer than 24 Kernels
Below is the run command, then displayed calibration phase, final results and details for the 24 loops using the largest data sizes. Calibration arranges for each loop to run for around one second. The Checksums OK column is an indication of accuracy, compared with a specification and probably based on results from CDC 6600 and 7600. These hardware/compiler dependent numeric answers are checked as in the Linpack benchmark. Results included in the log file are Minimum, Maximum, Averages and 24 weighted average MFLOPS speeds.
As with the Linpack benchmark, liverloopsPiA7, the gcc 4.8 compilation, produced different numeric answers to the earlier version, this time for 22 out of the 24 kernels. All were only slightly different and are shown below, for part 3 of 3. The benchmark produced a run time error from the initial gcc 4.8 compilation. This was due to the way in which shared array space is allocated and was also apparent with earlier Android compilations. So, the same code changes were made and the revised source code is included in
Raspberry_Pi_Benchmarks.zip.
|
|
pi@raspberrypi ~/benchmarks $ ./liverloopsPiA6
##########################################
L.L.N.L. °C' KERNELS: MFLOPS P.C. VERSION 4.0
Optimisation Opt 3 32 Bit
Calculating outer loop overhead
1000 times 0.00 seconds
10000 times 0.00 seconds
100000 times 0.00 seconds
1000000 times 0.06 seconds
2000000 times 0.11 seconds
4000000 times 0.23 seconds
Overhead for each loop 5.7500e-08 seconds
Calibrating part 3 of 3
Loop count 32 0.00 seconds
Loop count 128 0.01 seconds
Loop count 512 0.04 seconds
Loops 200 x 8 x Passes
Kernel Floating Pt ops
No Passes E No Total Secs. MFLOPS Span Checksums OK
------------ -- ------------- ----- ------- ---- ---------------------- --
1 28 x 11 5 6.652800e+07 0.97 68.29 27 3.855104502494961e+01 16
2 46 x 18 4 5.829120e+07 0.93 62.65 15 3.953296986903059e+01 16
3 37 x 36 2 1.150848e+08 0.85 135.70 27 2.699309089320672e-01 16
4 38 x 36 2 6.566400e+07 0.88 75.04 27 5.999250595473891e-01 16
5 40 x 12 2 3.993600e+07 1.08 36.99 27 3.182615248447483e+00 16
6 21 x 34 2 5.483520e+07 1.26 43.52 8 1.120309393467088e+00 15
7 20 x 14 16 1.505280e+08 1.03 146.64 21 2.845720217644024e+01 16
8 9 x 10 36 1.347840e+08 1.08 124.52 14 2.960543667875005e+03 15
9 26 x 11 17 1.166880e+08 1.27 92.17 15 2.623968460874250e+03 16
10 25 x 10 9 5.400000e+07 1.16 46.59 15 1.651291227698265e+03 16
11 46 x 18 1 3.444480e+07 1.10 31.30 27 6.551161335845770e+02 16
12 48 x 14 1 2.795520e+07 1.13 24.66 26 1.943435981130448e-06 16
13 31 x 9 7 2.499840e+07 1.19 21.07 8 3.847124199949431e+10 15
14 8 x 11 11 4.181760e+07 1.08 38.63 27 2.923540598672009e+06 15
15 1 x 17 33 6.283200e+07 0.98 64.21 15 1.108997288134785e+03 16
16 14 x 34 10 8.377600e+07 1.41 59.41 15 5.152160000000000e+05 16
17 26 x 17 9 9.547200e+07 1.13 84.27 15 2.947368618589361e+01 16
18 2 x 11 44 1.006720e+08 1.16 86.92 14 9.700646212337041e+02 16
19 28 x 23 6 9.273600e+07 1.30 71.56 15 1.268230698051003e+01 15
20 7 x 9 26 6.814080e+07 1.19 57.04 26 5.987713249475302e+02 16
21 1 x 2 2 8.000000e+07 1.51 52.99 20 5.009945671204667e+07 16
22 8 x 8 17 2.611200e+07 1.16 22.42 15 6.109968728263972e+00 16
23 7 x 11 11 8.808800e+07 0.98 89.56 14 4.850340602749970e+02 16
24 23 x 35 1 3.348800e+07 1.17 28.56 27 1.300000000000000e+01 16
Maximum Rate 146.64
Average Rate 65.20
Geometric Mean 56.66
Harmonic Mean 48.85
Minimum Rate 21.07
Do Span 19
Overall
Part 1 weight 1
Part 2 weight 2
Part 3 weight 1
Maximum Rate 148.29
Average Rate 64.41
Geometric Mean 54.74
Harmonic Mean 46.40
Minimum Rate 16.62
Do Span 167
Type additional information to include in linpack.txt - Press Enter
gcc 4.8 and gcc-6 Different Results
Later at 64 bits - Checks for was results
1 was 3.855104502494985e+01 expected 3.855104502494961e+01
2 was 3.953296986903406e+01 expected 3.953296986903059e+01
3 was 2.699309089321338e-01 expected 2.699309089320672e-01
4 was 5.999250595474085e-01 expected 5.999250595473891e-01
5 was 3.182615248448323e+00 expected 3.182615248447483e+00
6 was 1.120309393467610e+00 expected 1.120309393467088e+00
7 was 2.845720217644064e+01 expected 2.845720217644024e+01
8 was 2.960543667877653e+03 expected 2.960543667875005e+03
9 was 2.623968460874436e+03 expected 2.623968460874250e+03
10 was 1.651291227698388e+03 expected 1.651291227698265e+03
11 was 6.551161335846584e+02 expected 6.551161335845770e+02
12 was 1.943435982643127e-06 expected 1.943435981130448e-06
13 was 3.847124173932926e+10 expected 3.847124199949431e+10
14 was 2.923540598700724e+06 expected 2.923540598672009e+06
15 was 1.108997288135077e+03 expected 1.108997288134785e+03
17 was 2.947368618590736e+01 expected 2.947368618589361e+01
18 was 9.700646212341634e+02 expected 9.700646212337041e+02
19 was 1.268230698051755e+01 expected 1.268230698051003e+01
20 was 5.987713249471707e+02 expected 5.987713249475302e+02
21 was 5.009945671206671e+07 expected 5.009945671204667e+07
22 was 6.109968728264851e+00 expected 6.109968728263972e+00
23 was 4.850340602751729e+02 expected 4.850340602749970e+02
|
Livermore Loops Benchmark Comparisons
For Cray 1 comparison purposes, it is more appropriate to use Cray 1S results, as these are from running all 24 kernels. Geometric mean for this system is 11.9 MFLOPS. In 1978, the Cray 1 supercomputer cost $7 Million, weighed 10,500 pounds and had a 115 kilowatt power supply. It was, by far, the fastest computer in the world. The Raspberry Pi costs around $70 (CPU board, case, power supply, SD card), weighs a few ounces, uses a 5 watt power supply and is more than 4.5 times faster than the Cray 1.
Average performance gains of the Raspberry Pi 2 are not as high as those for the Linpack benchmark, but the best test loop, at 900 MHz, is 4.25 times faster than the original Pi at 700 MHz. Highest average of 138 MFLOPS is 11.6 times faster than a Cray 1.
The Raspberry Pi 3 average speed shown is 46% faster than RPi 2, compared with 33% faster MHz, also a little faster than the Android tablet with the Cortex-A53. Then the latter’s 64 bit compilation indicates an average improvement of 46%, with a wide variation in MFLOPS from individual tests.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - In this case, the SUSE based test results all appeared to be sightly faster than those for Gentoo, but the range was between 92% and 99%. Average Android 64 bit speed was 10% slower but some results were faster, probably due to different compiler, in handling the relatively large code. Compared to 32 bit speeds, the 64 bit scores were between 1.02 and 2.88 times faster. The official geometric mean rating was 1.34 times faster. On the same basis, the RPi3 can be rated as the equivalent of 21 times the Cray 1 supercomputer.
See also
Livermore Loops Results on PCs.
Compare
System MHz Maximum Average Geomean Harmean Minimum Geomean Against
Raspberry Pi # 700 148.3 64.4 54.7 46.4 16.6
Raspberry Pi # 1000 216.8 94.8 80.8 68.7 29.3
RPi 2 v7-A7 900 248.0 126.1 114.9 103.9 41.5 2.10 RPi 700
RPi 2 v7-A7 1000 273.5 139.7 127.3 115.2 46.5 1.58 RPi 1000
gcc 4.8
RPi 2 v7-A7 * 900 223.8 136.9 125.6 113.0 42.3 1.09 RPi 2# 900
RPi 2 v7-A7 1000 244.9 150.7 138.2 124.4 46.7 1.09 RPi 2# 1000
RPi 3 v8-A53 ^ 1200 435.5 206.9 183.6 159.8 55.6 1.46 RPi 2* 900
gcc 4.8
RPi 3 v8-A53 > 1200 398.4 210.6 185.9 160.2 56.5 1.01 RPi 3^ 1200
gcc-6
64 Bit Working
OpenSuse gcc-6
RPi 3 v8-A53 > 1200 649.0 278.8 249.4 221.6 95.0 1.34 RPi 3 32 bit
Gentoo
RPi 3 v8-A53 > 1200 627.3 275.7 246.8 219.2 90.6 1.34 RPi 3 32 bit
Android
ARM 926EJ 800 9.9 5.6 5.4 5.2 2.4
ARM v7-A9 800 253.2 129.3 115.3 101.6 46.7
ARM v7-A9 1200 391.9 202.1 181.3 160.9 68.1
ARM v7-A15 1700 1252.8 476.0 375.8 288.8 90.8
ARM v8-A53 $ 1300 393.4 188.3 158.3 124.6 27.1 0.85 RPi 3> 1200
64 Bit Version
ARM v8-A53 1300 772.2 265.9 232.5 206.3 97.8 1.47 RPi 3$ 1300
Atom Z3745 1866 1031.2 480.0 429.8 378.6 154.7
Linux using CC
Intel Atom 1666 480.3 217.6 189.9 162.2 59.7
Core 2 2400 2264.7 1039.3 822.9 606.4 161.6
Linux using older GCC
Intel Atom 1666 465.2 212.2 185.1 157.4 49.7
Core 2 2400 2384.9 1038.1 805.8 582.1 161.0
Core i7 4820K 3900 5551.3 2196.8 1712.4 1286.6 415.3
|
Memory Speed Benchmark - memspeedPiA6, memspeedPiA7, memSpdPi64
See Comparisons BelowMemSpeed benchmark measures data reading speeds in MegaBytes per second carrying out calculations on arrays of cache and RAM data, normally sized 2 x 4 KB to 2 x 4 MB. Calculations are as shown in the results?headings. For the first two double precision tests, speed in Million Floating Point Operations Per Second (MFLOPS) can be calculated by dividing MB/second by 8 and 16. For single precision divide by 4 and 8. A disassembly showed that Millions of [Assembler] Instructions Per Second (MIPS), for the first two integer tests, can be calculated by multiplying MB/second by 0.78 and 0.59. For the three copy tests, MIPS are MB/second times 0.344 for double precision and 0.688 for the other two. These calculations are shown below. Note that the changes in speeds, as data size increases, indicates the size of caches. As different instructions counts are produced with later NEON compilations, MOPS are shown for the first integer test.
The two executables are for Raspberry Pi and memspeedIL for Intel/Linux. Particularly for the latter, the default maximum of 8 MB might be too small to demonstrate RAM speed. For either, a run time parameter is provided to use more memory. These are for up to 128, 256, 512 or 1024 - examples memspeedPiA6 MB 256 and memspeedIL MB 1024.
Raspberry Pi CPU 700 MHz, Core 400 MHz, SDRAM 400 MHz
Memory Reading Speed Test 32 Bit Version 4 by Roy Longbottom
Start of test Mon May 20 10:25:17 2013
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 538 640 930 602 731 1094 1230 465 465 L1
16 568 602 787 602 731 1023 1000 426 507
32 292 256 310 276 262 330 1066 426 547 L2
64 276 238 276 262 238 292 341 269 284
128 189 170 193 182 170 200 222 196 204
256 140 129 142 136 129 144 138 119 124 RAM
512 138 127 138 134 127 144 131 111 119
1024 136 127 138 134 127 144 124 111 119
2048 136 127 138 132 128 144 128 111 121
4096 136 128 138 134 126 144 128 111 119
8192 138 127 138 136 127 144 126 111 119
End of test Mon May 20 10:26:06 2013
Max MFLOPS 71 160 38 91
Max MIPS 725 645 423 320 320
Max MOPS 233
|
Memory Speed Comparison
The first results below are for the Raspberry Pi at the maximum overclocked settings. The overheads on repetitively running the tests cause variations in speeds of the lower data sizes but average overclocked speed gain, using L1 cache, is 1.41 times, compared with 1.43 times CPU MHz. Average RAM speed gains are 1.53 times, similar to expectations. A surprise is for L2 cache based data, where the average gain is 1.72 times and some speeds appear to be faster than using L1 cache.
Comparing 900 MHz Raspberry Pi 2 results, from gcc 4.8 (PiA7), with the original system, at 700 MHz, indicates average performance gains of 3.3, 5.3 and 3.8 times for L1 cache, L2 cache and RAM based data, increased from the old PiA6 version at 2.4, 4.5 and 3.5 times. The first calculations are the same as those that determine Linpack benchmark speeds, in this case gcc 4.8 single precision speeds are again slower than using the original benchmarks (Pia7 vfma.f32 instructions and Pia6 fmacs). The PiA7 integer calculations provide the highest performance gains, from cached data, the test loop containing 2 vector loads to quad word registers (vld1.32), 2 vector adds (vadd.i32) and one vector store ( vst1.32), compared with 8 loads, 8 adds and 4 stores in PiA6.
Results for a version compiled to use NEON instructions, providing some of the fastest speeds, are included below. For more details see MemSpeed NEON.
Later results are for the same code compiled for Android devices, less the copy tests, where the later ARM systems are considerably faster. In this case, The Pi performs relatively well on single precision floating point. For other results see Android Benchmarks.htm.
The other results are using the Intel/Linux version, where speeds are generally much faster. An exception is L1 cache speed using single precision floating point, where the Pi is faster than the Atom on a MFLOPS/MHz basis. For older PC speeds that are slower than the Raspberry Pi see MemSpd2k results.htm.
Compared to default speed Raspberry Pi 2 results, RPi 3 L1 cache performance is not much faster than the 1.33 times clock MHz ratio, but L2 results are more than twice as fast, where RPi 3 L2 and L1 cache speeds are similar. Average RPi 3 RAM MB/second measurements indicate an average improvement of 2.5 times, where memory clock speed is double.
The Cortex-A53 based Android tablet 64 bit performance is generally much faster than from the 32 bit compilation, but the 32 bit compiler is not as effective as that used for the Raspberry Pi. Best 64 bit gains are when using 64 bit double precision numbers, where cache based speed can be twice that from the RPi 3.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - Results below include benchmarks compiled with gcc 4.8 and gcc 6, run via SUSE and the latter using Gentoo. These are followed by comparisons of L1 cache, L2 cache and RAM speeds. The first is for SUSE/Gentoo that are essentially the same. Next comparisons are for gcc 6/gcc 4.8 then gcc 6/32 bit A7. The former indicates gains on DP calculations using caches, and the latter on all L1 cache speeds and L2 cache speeds, other than for some integer tests, Both are more efficient running the last data copying procedures. For the first DP tests, gcc 4.8 and gcc 6 both use 64 bit fused multiply and add vector instructions, gcc 4.8 being slower due to using additional and different load instructions - see Assembly Code.
Compile options to use NEON instructions for
MemSpeed NEON
are not available at 64 bit working.
Raspberry Pi CPU 1000 MHz, Core 500 MHz, SDRAM 600 MHz, 6 volts
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 602 640 1185 930 1163 1662 1422 511 761 L1
16 787 930 1292 853 1023 1523 1777 537 761
32 487 426 487 465 426 568 1939 820 1142 L2
64 465 393 465 426 393 511 592 457 508
128 330 310 341 320 301 365 341 301 341
256 208 200 213 204 200 217 196 170 189 RAM
512 204 200 213 200 200 213 196 176 182
1024 213 200 208 200 200 217 196 170 182
2048 204 196 213 204 200 217 196 170 182
4096 204 200 213 200 200 217 196 170 182
8192 204 200 213 200 200 218 204 169 182
Max MFLOPS 98 232 58 145
Max MIPS 1007 980 667 563 785
Max MOPS 323
############################## RPi 2 ##################################
Raspberry Pi 2 CPU 900 MHz, Core 250 MHz, SDRAM 450 MHz
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
PiA6
8 731 1280 1142 2133 1454 1422 2666 1523 1641 L1
16 1066 1333 1292 1969 1406 1523 2666 1523 1641
32 1023 1293 1094 1828 1333 1406 2051 1428 1428
64 930 1016 1067 1662 1185 1230 1230 1333 1333 L2
128 853 1016 1023 1524 1186 1186 1163 1454 1333
256 853 1068 930 1423 1186 1186 1143 1455 1455
512 602 853 787 1168 853 930 1144 1027 1066
1024 365 512 393 465 538 426 984 511 465 RAM
2048 310 445 310 353 465 330 853 496 496
4096 301 445 301 341 445 330 834 546 511
8192 307 446 317 351 446 338 945 580 580
Max MFLOPS 133 333
Max MOPS 323
PiA7
8 929 832 2047 2044 1366 2862 2035 2690 2845
16 1398 1197 2050 2049 1368 2868 2044 2861 2861
32 1264 1094 1768 1773 1227 2272 1700 2159 2160
64 1195 1042 1634 1635 1161 1997 1450 1479 1488
128 1133 991 1512 1526 1095 1792 1154 1121 1124
256 961 981 1500 1506 1089 1787 1132 1078 1064
512 629 669 895 878 717 979 1146 786 788
1024 400 396 470 458 413 496 943 642 644
2048 326 313 357 354 328 374 958 678 678
4096 322 311 354 351 326 372 954 721 718
8192 325 311 355 353 327 372 952 732 733
Max MFLOPS 175 299
Max MOPS 512
########################### RPi 2 OC ##################################
Raspberry Pi 2 CPU 1000 MHz, Core 500 MHz, SDRAM 500 MHz, over_voltage=2
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
PiA6
8 682 853 1306 2327 1523 1777 2909 1777 1777
16 1185 1406 1306 2327 1523 1777 2666 1777 1777
32 1185 1333 1333 1969 1523 1523 2279 1641 1641
64 1023 1293 1094 1778 1333 1306 1882 1599 1428
128 1023 1186 1094 1641 1230 1333 1641 1524 1539
256 930 1142 1016 1642 1333 1333 1778 1429 1524
512 682 930 787 1094 930 930 1642 1068 984
1024 465 602 487 568 639 538 1168 618 618
2048 379 538 409 465 538 409 914 597 597
4096 379 538 379 445 538 409 904 658 682
8192 378 546 393 446 546 427 819 750 760
Max MFLOPS 148 351
Max MOPS 333
PiA7
8 918 928 2261 2258 1509 3162 2248 3142 3143
16 1547 1322 2265 2264 1511 3168 2258 3160 3160
32 1536 1314 2251 2245 1501 3146 2247 3141 3130
64 1296 1135 1773 1776 1263 2134 1795 1789 1797
128 1226 1098 1679 1676 1213 1996 1822 1483 1486
256 1013 985 1442 1446 1083 1672 1549 1311 1304
512 568 553 694 682 579 742 1371 989 993
1024 473 465 550 548 485 591 1279 913 916
2048 413 400 459 456 415 484 943 688 688
4096 410 398 455 446 411 480 871 620 620
8192 411 399 457 454 412 482 847 601 600
Max MFLOPS 193 330 142 189
Max MOPS 566
########################### RPi 2 NEON #################################
Raspberry Pi 2 CPU 900 MHz, Core 250 MHz, SDRAM 450 MHz
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 918 1778 2031 2029 2369 2838 2020 2825 2823
16 1388 1781 2034 2034 2374 2847 2029 2840 2828
32 1380 1768 2021 2020 2357 2811 2024 2832 2831
64 1169 1435 1595 1597 1785 1924 1573 1392 1391
128 1124 1366 1509 1513 1688 1794 1608 990 986
256 875 1163 1270 1269 1391 1460 1163 892 900
512 675 886 953 941 1022 1074 1081 776 785
1024 363 401 409 399 419 428 904 596 596
2048 318 338 341 343 355 362 751 539 541
4096 316 333 339 339 351 359 720 501 503
8192 317 334 340 340 352 361 709 483 484
Max MFLOPS 174 445 127 297
Max MOPS 509
######################## RPi 2 NEON OC ################################
Raspberry Pi 2 CPU 1000 MHz, Core 500 MHz, SDRAM 500 MHz, over_voltage=2
Memory Reading Speed Test NEON 32 Bit Version 1 by Roy Longbottom
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
NEON
8 1542 1963 2257 2253 2633 3143 1672 2143 3078
16 1542 1978 2248 2258 2638 3163 2247 3111 3116
32 1402 1744 1961 1965 2221 2481 1958 2532 2534
64 1303 1596 1770 1778 1988 2146 1700 1756 1756
128 1242 1508 1665 1667 1862 1977 1599 1458 1467
256 976 1276 1376 1395 1532 1483 1610 1313 1315
512 756 966 1031 1020 1111 1156 1643 1099 1107
1024 476 544 569 554 584 606 1376 953 956
2048 401 432 447 444 458 471 1268 968 967
4096 401 429 443 436 455 466 1239 1043 1039
8192 404 434 448 446 460 472 1001 777 779
Max MFLOPS 193 493 141 330
Max MOPS 562
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
PiA6
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 1523 1777 1828 2461 1969 2327 3657 2285 2461 L1
16 1662 1777 1828 2285 2133 2327 3846 2285 2461
32 1662 1777 1939 2461 1969 2327 3657 2461 2381
64 1524 1641 1778 2133 1969 1969 3657 2279 2285 L2
128 1524 1778 1828 2328 1829 2133 3657 2279 2279
256 1525 1779 1828 2327 1828 2001 3657 2280 2286
512 1456 1642 1779 2133 1832 1969 3413 2287 2135
1024 930 1094 1094 1236 1186 1186 1232 1144 1070 RAM
2048 930 992 1023 1102 1102 853 1066 914 921
4096 930 1023 1092 1102 1102 1102 834 837 834
8192 893 983 1071 1111 1160 1071 976 945 877
Max MFLOPS 208 444
Max MOPS 485
PiA7
8 1619 1812 3448 2375 2237 3793 2698 3121 3147
16 1621 1814 3459 2379 2240 3793 2710 3136 3162
32 1577 1743 3243 2277 2132 3138 2702 3123 3131
64 1537 1690 3126 2196 2047 3362 2566 2890 2917
128 1570 1714 3257 2243 2076 3502 2624 2993 3027
256 1573 1720 3285 2261 2084 3522 2652 3071 2930
512 1453 1598 2785 2055 1906 2081 2430 2783 2815
1024 918 1097 1327 1204 1185 1355 1606 1261 1263
2048 891 1032 1224 1133 1113 1191 882 811 817
4096 885 1023 1223 1127 1104 1201 787 756 755
8192 876 1019 1225 1118 954 1203 876 871 873
Max MFLOPS 203 454 149 280
Max MOPS 865
########################### RPi 3 NEON #################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Memory Reading Speed Test NEON 32 Bit Version 1 by Roy Longbottom
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 1627 2387 3467 2387 3181 3812 2713 3164 3149
16 1621 2377 3457 2377 3169 3805 2713 3164 3165
32 1577 2273 3238 2280 2985 3535 2647 3103 3105
64 1526 2150 3018 2157 2793 3256 2568 2921 2921
128 1554 2217 3190 2216 2925 3436 2631 3028 3029
256 1561 2228 3225 2221 2948 3471 2654 3077 3077
512 1434 2010 2742 1978 2534 2313 2468 2840 2840
1024 950 1227 1324 1182 1306 1339 1581 1298 1298
2048 935 1136 1215 1128 1212 1214 915 880 885
4096 913 1121 1180 1131 1213 1212 825 844 842
8192 926 1134 1212 1126 936 1199 792 774 790
Max MFLOPS 203 594 149 396
Max MOPS 864
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 4224 2547 3813 5433 3469 4237 4717 3793 3794 L1
16 4211 2546 3820 5423 3469 4236 4759 3815 3815
32 3380 2287 3225 4132 3003 3526 4603 3752 3752
64 3290 2266 3179 3994 2966 3451 4539 3724 3723 L2
128 3386 2321 3301 4039 3076 3567 4359 3589 3590
256 3342 2346 3359 4096 3132 3643 4355 3593 3593
512 2961 2070 2824 3371 2640 3025 3599 3087 3082
1024 757 1268 1344 1331 1341 1369 1487 1479 1419 RAM
2048 756 959 1227 1193 1226 1254 1134 1237 1212
4096 699 952 1230 1226 1226 1248 1063 1173 1165
8192 754 1169 1203 1206 1207 1210 1036 1045 1033
Max MFLOPS 528 637 340 433
Max MOPS 955
############################## RPi 3 Gentoo #############################
8 4158 2503 3749 5341 3411 4164 4639 3729 3730 L1
16 4014 2506 3758 5359 3416 4174 4675 3751 3750
32 3925 2483 3722 5307 3384 4125 4665 3712 3712
64 3253 2301 3271 4121 3043 3581 4342 3544 3535 L2
128 3196 2360 3394 4190 3165 3719 4221 3487 3484
256 3125 2385 3437 4225 3201 3767 4215 3501 3504
512 672 2079 2937 3551 2725 3223 3858 3249 3255
1024 618 1189 1266 1265 1255 1274 1156 1433 1355 RAM
2048 607 1133 1183 1162 1178 1194 978 1027 1026
4096 619 1135 1185 1170 1175 1200 995 1060 1048
8192 554 1140 1189 1171 1178 1206 1009 1081 1081
Max MFLOPS 520 627 335 427
Max MOPS 940
############################# RPi 3 SUSE ##############################
Compiled for 64 bit ARM v8a+fp+sim
8 2726 2544 3468 4013 3468 4233 4206 3791 3788 L1
16 2728 2552 3477 4026 3478 4247 4232 3814 3814
32 2557 2392 3190 3611 3191 3812 4248 3819 3822
64 2416 2248 2961 3246 2961 3478 4037 3725 3728 L2
128 2452 2276 3038 3283 3025 3530 3908 3567 3566
256 2414 2313 3093 3350 3088 3600 3940 3594 3594
512 2156 2027 2603 2779 2583 2989 3473 3255 3075
1024 707 954 1315 1330 1314 1330 1597 1591 1538 RAM
2048 704 955 1146 1148 1134 1156 1038 1039 1037
4096 697 983 1136 1135 1109 1142 843 907 898
8192 694 1106 1140 1135 1141 1136 877 957 940
Max MFLOPS 341 636 251 435
Max MOPS 869
######################## 64 Bit Comparison #############################
x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
L1 16KB
SUSE/Gentoo 1.05 1.02 1.02 1.01 1.02 1.01 1.02 1.02 1.02
SUSE/gcc 4.8 1.54 1.00 1.10 1.35 1.00 1.00 1.12 1.00 1.00
SUSE/32 bit 2.60 1.40 1.10 2.28 1.55 1.12 1.76 1.22 1.21
L2 256 KB
SUSE/Gentoo 1.07 0.98 0.98 0.97 0.98 0.97 1.03 1.03 1.03
SUSE/gcc 4.8 1.38 1.01 1.09 1.22 1.01 1.01 1.11 1.00 1.00
SUSE/32 bit 2.12 1.36 1.02 1.81 1.50 1.03 1.64 1.17 1.23
RAM 4 MB
SUSE/Gentoo 1.13 0.84 1.04 1.05 1.04 1.04 1.07 1.11 1.11
SUSE/gcc 4.8 1.00 0.97 1.08 1.08 1.11 1.09 1.26 1.29 1.30
SUSE/32 bit 0.79 0.93 1.01 1.09 1.11 1.04 1.35 1.55 1.54
######################## Other Cortex A53 ##############################
Tab 2 A8-50, 1.3 GHz quad core 64 bit ARM Cortex-A53
ARM/Intel MemSpeed Benchmark 1.2 05-Aug-2015 17.16
Compiled for 32 bit ARM v7a
Reading Speed in MBytes/Second
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m]
KBytes Dble Sngl Int Dble Sngl Int
16 1940 971 1693 2470 1278 2084 L1
32 1879 955 1676 2378 1255 1967
64 1801 938 1615 2254 1218 1912 L2
128 1706 941 1620 2279 1224 1872
256 1818 935 1570 2291 1155 1875
512 1633 884 1451 2008 1132 1704
1024 1276 781 1181 1454 938 1324 RAM
4096 1335 808 1260 1533 1010 1386
16384 1342 813 1270 1487 1013 1419
65536 1346 809 1274 1546 1031 1252
Max MFLOPS 242 243 154 160
Max MOPS 419
ARM/Intel MemSpeed Benchmark 1.2 05-Aug-2015 17.29
Compiled for 64 bit ARM v8a
16 4092 2198 3951 5293 3611 4408
32 3753 2496 3630 4651 3300 3992
64 3407 2388 3368 3715 3023 3677
128 3496 2462 3521 4137 3139 3844
256 3535 2481 3573 4199 3322 3911
512 3054 2248 3126 3556 2548 3372
1024 1714 1704 2029 2069 1854 2099
4096 1832 1595 1841 1914 1780 1897
16384 1844 1601 1850 1925 1798 1891
65536 1859 1608 1837 1921 1795 1812
Max MFLOPS 512 624 331 451
Max MOPS 988
############################# Other ####################################
Android MemSpeed Benchmark 17-Oct-2012 20.19
ARM Cortex-A9 1300 MHz, 1 GB DDR3 RAM
Reading Speed in MBytes/Second
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m]
KBytes Dble Sngl Int Dble Sngl Int
16 1735 888 2456 2726 1364 2818 L1
32 1448 760 1474 1700 1039 1648
64 1318 719 1290 1468 952 1385 L2
128 1279 715 1289 1443 944 1336
256 1268 714 1279 1435 943 1313
512 1158 691 1204 1321 892 1228
1024 729 553 735 772 632 742
4096 445 392 425 442 421 439 RAM
16384 435 390 428 435 412 431
65536 445 404 393 450 432 449
Intel Atom 1666 MHz memspeedIL
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 1720 853 2150 2203 1086 3686 1379 1851 1785 L1
16 1612 825 2051 2150 1075 2962 1599 1777 1612
32 1517 825 1785 2019 1041 2666 1290 1388 1379 L2
64 1470 825 1785 2051 1041 2580 1379 1333 1646
128 1724 948 2272 2580 1358 3463 1612 1785 1785
256 1725 948 2299 2499 1403 3572 1613 1731 1785
512 1624 914 2151 2349 1315 3228 1533 1670 1668
1024 1590 882 1990 2155 1296 2515 1251 1292 1292 RAM
2048 1590 882 1998 2095 1263 2235 1081 1117 1076
4096 1553 914 1951 2111 1279 2180 1076 1084 1055
8192 1592 910 1985 2113 1279 2171 1092 1085 1119
Core 2 2400 MHz, Dual channel DDR2 RAM, memspeedIL
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
8 17427 6736 6249 12498 6450 6399 12498 6348 6348 L1
16 13839 6450 6249 12498 6450 6450 12985 6348 6249
32 16664 6249 6450 13134 6399 6450 12498 6348 6143
64 10751 4999 5262 7528 4999 5332 5119 3555 3555 L2
128 7831 4999 5332 7313 4999 5333 5119 3703 3703
256 11494 4999 5332 7691 4999 5333 5208 3555 3656
512 11347 5160 5333 7313 4999 5264 5209 3555 3656
1024 9142 5160 5333 7699 5160 5332 5211 3707 3656
2048 10239 5007 5341 7528 4949 5341 5119 3555 3451
4096 7110 4790 5023 6920 4790 5023 4013 3135 3236
8192 3949 3686 3813 4031 3794 3794 2047 2015 1974 RAM
|
Bus Speed Benchmark - busspeedPiA6, busspeedPiA7, busSpdPi64
See Comparisons BelowThis benchmark is designed to identify reading data in bursts over buses. The program starts by reading a word (4 bytes) with an address increment of 32 words (128 bytes) before reading another word. The increment is reduced by half on successive tests, until all data is read.
Maximum MB/second data transfer speed is calculated as bus clock MHz x 2 for Double Data Rate (DDR) x bus width (at this time 4 bytes ARM, 8 bytes Intel) x number of memory channels. However, some of these specifications can be misleading and maximum speed options might not be provided on a particular platform. Where the maximum is not provided, there can be confusion as to whether specified MHz is raw bus clock speed or included DDR consideration.
One thing is quite clear, and that is multiple threads or programs are required to demonstrate highest obtainable throughput and this should be less than maximum specified speed due to start up (CAS latency) and other overheads. In order to minimise CPU time influence, estimates of maximum MB/second can be calculates from burst speeds (as shown below for 16 word address increments), and these should normally be greater than the Read All results. In the original benchmark, all threads started reading from word one, but this could lead to unreasonable fast speeds when shared L2 or L3 caches were provided. Results below are for a revised benchmark with staggered starting addresses, for example 4 threads at 3 MB intervals using 12 MB RAM.
Multithreaded benchmark results are provided below to help to identify why the single core BusSpeed benchmark speeds might be different from expectation. For comparison purposes, results are included for Android MP Benchmarks besides Raspberry Pi MP-BusSpeed.
Bus
Inc16 Inc8 Inc4 Inc2 Read Clock DDR Width Max
Words Words Words Words All MHz x2 Bytes MB/sec
Old Atom 262 541 1048 1973 3262 400 800 x8 6400
Atom 1.86 GHz
Z3745 275 611 1183 2328 3922 533 1066 x16# 17056
2 Threads 435 787 1671 3323 6507
4 Threads 455 884 1754 3490 6971 Max est 16 x 455 7280
Nexus 7 1.2 GHz
Cortex-A9 51 81 126 172 330 666 1333 x4 5333
2 Threads 67 107 196 335 620
4 Threads 68 108 215 426 835 Max est 16 x 68 1088
Kindle HDX 7 2.15 GHz
Snapdragon 800 406 516 899 1663 2929 933 1866 x8# 14928
2 Threads 541 962 1569 2851 4776
4 Threads 605 1109 2439 4161 8243 Max est 16 x 605 9680
Lenovo Tab 2 1.3 GHz
Cortex-A53 175 344 677 1285 1979 666 1333 x4 5333
2 Threads 241 479 968 1883 3724
4 Threads 277 556 1130 2126 4328 Max est 16 x 277 4432
Moto G4 1.5 GHz
Cortex-A53 172 339 658 1247 2014 933 1866 x4 7466
2 Threads 307 591 1124 2192 3839
4 Threads 353 813 1692 3015 6058 Max est 16 x 353 5648
Raspberry Pi 2 0.9 GHz
ARM-V7 71 159 281 628 1147 450 900 x4 3600
2 Threads 87 177 311 697 1256
4 Threads 98 191 297 700 1186 Max est 16 x 98 1568
Raspberry Pi 3 1,2 GHz
Cortex-A53 136 263 513 1047 2080 450 900 x4 3600
2 Threads 138 276 554 1108 2149
4 Threads 137 269 536 1169 2383 Max est 16 x 137 2192
# dual channel
Below are the Raspberry Pi results from busSpeed.txt log file, running at the default speed settings. The program main test had 64 C statements that translate into 64 load and 64 AND instructions. With loop overheads that translates to 132 instructions on 256 bytes, where MIPS will be MB/second x 0.516.
The results suggest that data transfer bursts are 32 bytes (8 transfers of 4 bytes), with a possible maximum speed of 8 x 34 = 272 MB/second, at this single core level. They imply that there is also burst reading from caches besides using RAM, and performance of the latter is not very good, with this single core CPU.
Raspberry Pi CPU 700 MHz, Core 400 MHz, SDRAM 400 MHz
Maximum speed 400 x 2 (DDR) x 4 Width = 3.2 GB/sec
BusSpeed 32 Bit V1.1 Wed May 22 15:28:01 2013
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
16 290 304 568 984 1125 1142 L1
32 133 116 131 133 225 465 L2
64 116 98 116 109 192 409
128 60 54 62 68 126 273
256 34 34 34 43 88 192 RAM
512 34 34 34 45 91 200
1024 34 31 34 45 91 181
4096 32 33 33 45 87 183
16384 32 32 34 44 83 186
65536 34 32 34 44 88 186
End of test Wed May 22 15:28:13 2013
|
Bus Speed Comparison
The first one for comparison is the overclocked Pi, where most results are as might be expected at the higher clock frequencies but, again, with some L2 cache speeds quite a bit faster.
Raspberry Pi 2 results are shown with the CPU at 900 MHz and overclocked to 1 GHz, corresponding SDRAM frequencies are 450 and 500 MHz. The busspeedPiA6 speeds are most unusual, on reading all data, where speed, on reading all data, is slower than reading every other word. Assembly Code appears to show that there is little difference in generated instructions, from the two versions, except PiA7 uses negative indexing. Comparisons, shown with PiA7 1 GHz details, suggest that speed from RAM is at least 2.5 times faster from gcc 4.8. The other comparisons are for busspeeddPiA6, where the highest performance gains, of RPi 2, are via data in L2 cache.
Next results are for one CPU core on a Nexus 7, with a 1300 MHz ARM Cortex-A9 processor. The overclocked Pi is not too far away on RAM performance but falls behind on L1 and L2 cache based data.
The two Intel examples are clearly much faster but BusSpd2k Results on PCs provides results on older systems where the Raspberry Pi is the winner (ignore the last two columns for MMX instructions). There are also results of some slower systems in Android Benchmarks.htm.
On the Raspberry Pi 3, busspeedPiA6, and the newer busspeedPiA7 benchmark, demonstrate almost identical performance. With the former, considering just the Read All results, the RPi 3 is shown to average 2.85 times faster than the RPi 2 using cache based data and 5.26 times from RAM. Corresponding ratios using PiA7 are 2.31 and 1.42 times.
The 32 bit compiler, used for the Cortex-A53 based tablet tests, produced different performance characteristics to those used on the Raspberry Pi, some better scores and some worse. The same might apply to the 64 bit version, but results from RAM were faster than other A53 tablet and RPi 3 tests, the latter by an average of 50%.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - With the Read All tests being the most representative of data transfers normally used, comparisons are provided for these and there was not much difference in performance between 32 bit PiA7, 64 bit gcc 6 and 64 bit gcc 4.8 speeds. The one exception is at 16 KB data size, where gcc 6 tests were slow. The C code loop has 64 AND statements. Disassembly shows that the gcc 4.8 version has 64 AND and 65 load (ldr) instructions, using 8 w registers. The gcc 6 program has 64 AND, 19 load (ldr) and 23 lad pair (ldp) instructions, using up to 16 w registers - more registers, fewer instructions but slower?
Raspberry Pi CPU 1000 MHz, Core 500 MHz, SDRAM 600 MHz, 6 volts
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
16 290 387 984 1505 1575 1750 L1
32 246 186 232 232 393 731 L2
64 146 113 131 148 273 546
128 102 87 93 113 210 420
256 53 48 53 75 131 303 RAM
512 48 48 50 75 137 300
1024 48 50 49 69 139 305
4096 50 52 52 72 134 299
16384 48 52 52 69 139 296
65536 49 52 49 72 139 291
############################## RPi 2 ##################################
Raspberry Pi 2 CPU 900 MHz, Core 250 MHz, SDRAM 450 MHz
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
PiA6
16 1346 1428 1575 1641 1706 1489 L1
32 930 984 1163 1422 1489 1641
64 426 372 630 1024 1365 1365 L2
128 341 380 682 1137 1462 1191
256 213 232 512 813 1191 1169
512 129 136 273 570 840 782
1024 73 83 167 360 685 412 RAM
4096 63 76 152 293 629 322
16384 69 74 149 314 599 335
65536 69 78 148 279 629 335
PiA7
16 950 1509 1632 1726 1734 1738
32 1240 1318 1437 1716 1633 1681
64 419 429 747 1214 1479 1587
128 386 411 702 1211 1572 1625
256 367 399 691 1194 1573 1634
512 138 164 313 598 990 1363
1024 79 88 175 372 673 1264
4096 66 76 154 300 632 1266
16384 71 77 154 299 633 1264
65536 71 76 154 297 633 1261
########################### RPi 2 OC ##################################
Raspberry Pi 2 CPU 1000 MHz, Core 500 MHz, SDRAM 500 MHz, over_voltage=2
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read Pi2/Pi
KBytes Words Words Words Words Words All 1 GHz
PiA6
16 1066 1662 1706 1975 1861 1896 1.08
32 930 1163 1367 1706 1706 1861 2.55
64 465 474 820 1219 1575 1462 2.68
128 372 426 787 1241 1706 1490 3.55
256 393 426 745 1260 1626 1491 4.92
512 266 281 522 916 1367 1196 3.99
1024 105 114 249 456 913 508 1.67
4096 93 115 220 396 880 419 1.40
16384 100 113 227 419 838 441 1.49
65536 97 111 209 419 883 447 1.54
A7/A6
PiA7 1 GHz
16 1554 1662 1813 1894 1892 1894 1.00
32 629 648 911 1328 1604 1756 0.94
64 453 461 803 1245 1572 1752 1.20
128 394 430 773 1284 1705 1783 1.20
256 280 410 747 1306 1733 1798 1.21
512 242 253 472 891 1335 1607 1.34
1024 107 122 243 481 919 1287 2.53
4096 95 108 216 420 886 1204 2.87
16384 98 108 216 419 885 1205 2.73
65536 99 109 216 419 888 1204 2.69
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
PiA6
16 3429 3555 3938 4266 4266 4266 L1
32 1066 1066 1693 2625 3413 3657
64 639 609 1125 1896 2978 3276 L2
128 533 546 1023 1862 2844 3413
256 533 525 1023 1706 2730 3414
512 351 393 758 1310 2184 2983
1024 123 136 274 548 1012 1879 RAM
4096 100 117 254 471 943 1852
16384 119 129 244 489 978 1806
65536 122 123 258 479 1032 1789
PiA7 /PiA6
16 3335 3741 4075 4371 4388 4413 1.03
32 1964 2229 2787 4271 4308 4311 1.18
64 612 615 1121 1932 2880 3546 1.08
128 570 573 1034 1803 2756 3467 1.02
256 541 544 995 1758 2737 3457 1.01
512 382 408 794 1360 2269 3105 1.04
1024 128 136 256 533 1025 1945 1.04
4096 109 125 245 482 961 1585 0.86
16384 120 125 241 477 964 1744 0.97
65536 120 125 243 477 947 1881 1.05
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
/PiA7
16 3370 3765 4085 4440 4477 3399 0.80
32 2070 2222 2768 4314 4386 3389 0.93
64 590 604 1138 1875 2866 3100 0.95
128 559 568 1061 1784 2781 3135 0.92
256 534 542 1023 1741 2759 3161 0.93
512 477 485 948 1628 2648 3107 1.04
1024 100 142 273 519 1082 2038 1.08
4096 90 128 254 493 988 1935 1.04
16384 123 128 253 495 999 1963 1.09
65536 123 128 254 497 994 1980 1.11
############################ RPi 3 Gentoo #############################
/SUSE
16 1927 3680 4011 4336 4394 3335 0.98
32 2022 2159 2688 4171 4257 3299 0.97
64 579 595 1121 1859 2835 3065 0.99
128 549 557 1041 1750 2735 3082 0.98
256 518 528 1001 1700 2701 3095 0.98
512 384 397 788 1397 2284 2744 0.88
1024 128 131 253 505 1010 1923 0.94
4096 88 119 238 461 938 1737 0.90
16384 115 116 238 455 929 1657 0.84
65536 115 119 238 459 934 1764 0.89
############################# RPi 3 SUSE ##############################
Compiled for 64 bit ARM v8a+fp+sim
/SUSE64
16 3275 3775 4021 4277 4330 4399 1.29
32 914 966 1582 2441 3246 3771 1.11
64 601 611 1144 1958 2899 3548 1.14
128 559 567 1054 1824 2796 3471 1.01
256 534 543 1019 1758 2744 3405 1.08
512 319 348 682 1280 2164 3021 0.97
1024 114 138 274 539 1064 2045 1.00
4096 86 124 247 489 966 1788 0.92
16384 121 123 247 488 971 1858 0.95
65536 121 125 247 490 963 1736 0.88
######################## Other Cortex A53 ##############################
Tab 2 A8-50, 1.3 GHz quad core 64 bit ARM Cortex-A53
ARM/Intel BusSpeed Benchmark 1.2 06-Aug-2015 10.57
Compiled for 32 bit ARM v7a
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
16 874 932 1814 2302 2355 2263 L1
32 758 803 1309 1820 2323 2386
64 653 671 1203 1741 2206 2332 L2
128 603 620 1107 1693 2222 2351
256 574 589 1075 1711 2211 2327
512 332 372 681 1075 1863 2120
1024 137 193 371 578 1322 2129 RAM
4096 172 179 351 567 1151 2126
16384 172 178 351 504 1117 2136
65536 172 177 349 478 882 2129
ARM/Intel BusSpeed Benchmark 1.2 06-Aug-2015 11.02
Compiled for 64 bit ARM v8a
16 3188 3635 3937 4327 4372 4462
32 1478 1607 2246 3382 3853 4144
64 600 622 1163 2011 2972 3585
128 558 575 1056 1889 2892 3525
256 538 550 1028 1826 2837 3260
512 371 425 813 1490 2403 3202
1024 136 196 382 728 1423 2750
4096 170 177 346 669 1340 2652
16384 169 174 341 678 1352 2663
65536 168 174 341 676 1347 2611
############################# Other ####################################
Android BusSpeed Benchmark 19-Oct-2012 17.29
ARM Cortex-A9 1300 MHz, 1 GB DDR3 RAM
RAM 1 GB DDR3L-1333 Bandwidth 5.3 GB/sec
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
16 2723 2420 3044 3364 3499 3500 L1
32 1054 1087 1061 1382 1565 2145
64 436 433 419 652 751 1160 L2
128 345 337 337 542 633 943
256 329 309 322 522 614 961
512 339 299 311 506 574 937
1024 170 168 180 269 349 629
4096 59 55 84 127 176 338 RAM
16384 56 56 83 125 173 335
65536 56 56 82 125 174 334
Intel Atom 1666 MHz busspeedIL
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
16 3703 5160 5881 6249 6399 6529 L1
32 484 396 745 1474 2499 3931 L2
64 484 393 787 1516 2482 3878
128 491 410 775 1462 2509 3923
256 492 415 775 1454 2540 3887
512 225 327 606 1213 2184 3534
1024 130 266 533 1034 1952 3306 RAM
4096 126 262 524 1048 1941 3313
16384 135 270 508 1048 1917 3276
65536 135 262 541 1048 1973 3262
Core 2 2400 MHz, Dual channel DDR2 RAM, busspeedIL
Reading Speed 4 Byte Words in MBytes/Second
Memory Inc32 Inc16 Inc8 Inc4 Inc2 Read
KBytes Words Words Words Words Words All
16 6535 5516 6059 6490 6205 6304 L1
32 5925 3225 3938 6023 6094 5966
64 1721 1305 2154 3047 4444 5269 L2
128 1407 1333 2172 3033 4571 5333
256 1538 1365 2206 3047 4432 5334
512 1391 1376 2150 3102 4552 5336
1024 1377 1376 2202 3104 4519 5460
4096 731 814 1425 2206 3669 4882
16384 345 380 761 1310 2530 4343 RAM
65536 321 374 748 1310 2485 4066
|
FFT Benchmarks - fft1-RPi2, fft3c-Rpi2, fft1-RPi64, FFT3c-RPi64
In 2000, I provided optimised code for a Fast Fourier Transform program, resulting in a series of Windows benchmarks that provided graphical output - see fftgraf results.htm. The fastest one used SSE type assembly code that modern compilers can also produce. The new versions use all C code, with identical calculations compiled to run via Linux, Windows and Android. The benchmarks and source codes are in FFT Benchmarks.zip with further details and results from PCs, Android devices and RPi 2 in FFTBenchmarks.htm.
There are two benchmarks, FFT1, the original, and FFT3c, optimised, with 32 bit and 64 bit versions, when appropriate. Performance is measured in milliseconds, for FFTs sized 1K to 1024K, with three measurements using both single and double precision floating point data, plus some sumchecks for the largest ones. Results from a Raspberry Pi 2, at 900 MHz, are below. These are similar to a year 2000 Pentium III PC.
Raspberry Pi 3 average performance gains were similar to the clock speed ratio of 1.33.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - On running the newly compiled 64 bit versions on both systems, wide variations in performance were observed, with the smaller FFTs, where measured time is less than a millisecond. Full speed could be achieved by using “performance” CPU MHz setting (where available) or running another CPU bound program at the same time. These slower speeds also became apparent on 32 bit results, including via Raspberry Pi 2. All tests were repeated to run at maximum speeds, producing the results shown below. In some cases, the earlier slow measurements are also included.
Gentoo and SUSE produced virtually the same performance, with variations probably caused by different L2 cache presence. The 64 bit version averaged 24% faster on the single precision FFTs but with no real difference using double precision calculations.
The 64 bit benchmarks and source codes are included in Rpi3-64-Bit-Benchmarks.tar.gz.
Small FFT Tests - shortfft64 and shortfft32 - New programs were produced to identify differences in MHz settings. These execute 30 of the smallest 1K single precision FFTs 500 times. A summary of results is below. Besides the 500 measurements, total time is provided that includes data generation and checking overheads, these being included in a final summary. With on demand CPU MHz setting, 32 bit Raspbian and 64 bit Gentoo generally produce much slower execution times over the first few measurements, with the remainder at similar faster speeds. 64 bit OpenSUSE tends to produce the same slow speeds at the start but also has random longer periods of slow performance, Results from all three systems indicate constant running time with performance MHz setting or running another CPU benchmark at the same time.
These are also included in
Rpi3-64-Bit-Benchmarks.tar.gz.
RPi2 FFT 32 Bit Benchmark Version 1.0 Thu Feb 16 12:23:55 2017
Size milliseconds
K Single Precision Double Precision
1 0.212 0.206 0.206 0.246 0.245 0.252
2 0.462 0.447 0.447 0.689 0.678 0.723
4 1.244 1.206 1.192 1.704 1.634 1.616
8 2.995 3.133 2.989 4.397 3.963 3.899
16 6.983 6.785 6.767 13.282 10.515 9.748
32 17.142 17.182 16.855 31.020 30.025 31.891
64 52.794 52.885 52.727 152.318 146.516 145.472
128 278.668 280.006 285.012 358.963 362.587 360.340
256 624.823 636.579 632.442 779.830 790.282 815.686
512 1506.681 1512.883 1514.028 1678.495 1681.863 1668.933
1024 3288.894 3293.423 3312.335 3792.264 3808.471 3789.059
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565234e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Thu Feb 16 12:24:51 2017
========================== Slow Speed =========================
1 0.309 0.305 0.307 0.364 0.356 0.355
2 0.666 0.673 0.680 0.928 0.912 0.900
###################################################
RPi2 FFT 32 Bit Benchmark Version 3c.0 Thu Feb 16 12:21:57 2017
Size milliseconds
K Single Precision Double Precision
1 0.282 0.237 0.232 0.255 0.246 0.247
2 0.612 0.529 0.582 0.574 0.627 0.635
4 1.523 1.249 1.203 1.498 1.668 1.543
8 2.925 2.781 2.727 3.226 3.141 3.063
16 7.220 6.679 6.672 8.954 8.808 8.737
32 16.862 17.276 15.712 23.606 23.662 23.527
64 41.294 41.568 40.916 57.516 56.900 56.923
128 98.052 97.028 96.708 128.591 127.978 127.868
256 217.731 214.874 214.927 277.817 276.615 280.291
512 466.673 461.412 462.023 596.874 598.976 595.552
1024 1009.119 998.319 999.178 1325.278 1310.229 1304.572
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565233e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Thu Feb 16 12:22:39 2017
========================== Slow Speed =========================
1 0.393 0.349 0.348 0.253 0.237 0.283
2 0.820 0.781 0.802 0.562 0.551 0.552
######################### Raspberry Pi 3 #########################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
RPi2 FFT 32 Bit Benchmark Version 1.0 Wed Feb 15 11:05:59 2017
Size milliseconds
K Single Precision Double Precision
1 0.167 0.164 0.163 0.166 0.164 0.165
2 0.393 0.366 0.366 0.419 0.417 0.418
4 1.036 1.007 0.934 1.117 1.091 1.088
8 2.269 2.247 2.236 2.550 2.506 2.501
16 5.624 5.290 5.231 6.086 5.852 5.842
32 12.714 12.569 12.844 22.068 22.479 21.907
64 43.349 44.585 43.293 110.424 110.410 110.581
128 214.541 217.334 216.575 269.974 269.617 269.755
256 526.296 525.924 525.682 615.746 615.259 615.811
512 1199.912 1199.233 1199.311 1364.511 1364.153 1367.418
1024 2509.227 2538.168 2523.659 2831.903 2831.330 2826.171
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565233e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 15 11:06:47 2017
========================== Slow Speed =========================
1 0.329 0.335 0.326 0.446 0.340 0.340
2 0.729 0.733 0.765 0.913 0.840 0.824
###################################################
RPi2 FFT 32 Bit Benchmark Version 3c.0 Wed Feb 15 11:03:37 2017
Size milliseconds
K Single Precision Double Precision
1 0.215 0.199 0.199 0.170 0.164 0.164
2 0.453 0.462 0.455 0.376 0.373 0.373
4 1.027 1.279 1.023 0.888 0.889 0.883
8 2.333 2.320 2.282 2.052 2.047 2.043
16 5.465 5.362 5.613 5.987 5.977 6.043
32 12.309 12.468 12.216 15.382 15.479 15.396
64 30.695 31.084 30.685 37.030 36.987 37.003
128 72.510 72.023 72.091 84.237 84.239 84.367
256 161.194 160.483 160.714 193.733 193.813 193.760
512 369.130 367.713 367.509 426.499 426.238 425.983
1024 802.163 799.225 798.768 957.992 948.540 948.625
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565233e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 15 11:04:06 2017
========================== Slow Speed =========================
1 0.427 0.397 0.398 0.175 0.165 0.166
2 0.996 0.952 0.924 0.396 0.395 0.393
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
armv8 64 Bit FFT Benchmark Version 1.0 Wed Feb 8 20:01:52 2017
Size milliseconds
K Single Precision Double Precision
1 0.153 0.152 0.152 0.175 0.170 0.168
2 0.347 0.339 0.334 0.402 0.387 0.387
4 0.817 0.763 0.766 1.946 1.433 1.242
8 3.296 2.018 1.963 2.966 2.716 2.698
16 4.623 4.456 4.392 6.719 6.229 6.759
32 10.551 10.417 10.301 18.407 18.816 18.941
64 28.290 28.555 28.032 126.881 127.317 127.272
128 173.229 173.332 172.477 299.374 298.644 298.596
256 405.373 405.188 407.602 657.365 657.037 657.864
512 905.640 921.727 921.347 1461.983 1463.511 1462.099
1024 2018.414 2018.043 2018.976 3163.591 3163.848 3164.858
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565234e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 8 20:02:29 2017
###################################################
armv8 64 Bit FFT Benchmark Version 3c.0 Wed Feb 8 20:11:05 2017
Size milliseconds
K Single Precision Double Precision
1 0.195 0.161 0.159 0.190 0.184 0.185
2 0.380 0.355 0.360 0.421 0.419 0.420
4 0.988 0.796 0.778 0.959 0.956 0.957
8 2.282 2.183 1.802 2.131 2.101 2.100
16 4.371 4.191 4.091 5.203 5.160 5.176
32 9.477 9.550 9.520 14.318 14.219 14.188
64 26.061 25.553 25.462 33.704 33.668 33.720
128 61.337 60.707 60.460 77.791 77.816 77.922
256 137.002 134.328 134.307 179.822 179.707 181.027
512 315.380 313.872 313.642 392.380 394.200 392.586
1024 692.640 689.569 689.751 859.132 854.983 852.890
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565234e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 8 20:11:22 2017
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
armv8 64 Bit FFT Benchmark Version 1.0 Wed Feb 8 19:46:59 2017
Size milliseconds
K Single Precision Double Precision
1 0.177 0.155 0.166 0.190 0.168 0.168
2 0.346 0.370 0.348 0.640 0.496 0.471
4 0.806 0.776 0.773 1.792 1.811 2.455
8 2.879 2.026 2.313 3.143 2.673 2.614
16 4.694 4.487 4.446 6.501 6.077 6.090
32 10.824 11.067 10.520 27.899 27.393 32.721
64 49.580 37.161 37.028 119.094 118.648 118.820
128 172.333 186.946 172.173 294.386 294.253 294.366
256 406.581 407.594 406.053 670.012 670.096 670.169
512 938.983 938.567 939.929 1486.050 1485.846 1486.961
1024 1987.861 1989.141 1997.740 3143.410 3143.533 3143.669
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565234e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 8 19:47:34 2017
###################################################
armv8 64 Bit FFT Benchmark Version 3c.0 Wed Feb 8 19:55:51 2017
Size milliseconds
K Single Precision Double Precision
1 0.181 0.172 0.160 0.190 0.185 0.185
2 0.400 0.366 0.362 0.458 0.420 0.423
4 0.892 0.937 0.932 0.989 0.976 0.994
8 1.986 1.967 2.604 2.269 2.270 2.334
16 5.590 4.686 4.433 5.615 5.533 5.621
32 10.438 10.081 10.263 14.656 14.616 14.669
64 27.759 27.381 27.154 34.832 34.816 34.853
128 63.303 62.331 62.107 79.898 79.849 79.896
256 138.935 170.902 137.272 186.385 186.580 186.381
512 318.062 315.184 315.421 409.840 410.370 410.283
1024 691.349 683.468 685.295 919.255 904.665 904.236
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565234e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 8 19:56:07 2017
###################################################
Example 64 Bit Results With On Demand CPU MHz
========================== Slow Speed =========================
armv8 64 Bit FFT Benchmark Version 3c.0 Wed Feb 8 19:58:15 2017
Size milliseconds
K Single Precision Double Precision
1 0.367 0.321 0.320 0.200 0.213 0.188
2 0.875 0.835 0.805 0.443 0.444 0.425
4 1.974 2.038 1.862 0.996 0.978 0.993
8 6.018 5.208 3.971 2.294 2.285 2.278
16 9.424 4.566 4.586 5.574 5.585 5.561
32 10.608 10.236 10.202 14.902 14.826 14.728
64 28.013 27.164 27.240 34.889 34.867 34.939
128 63.213 62.583 62.562 80.222 80.257 80.036
256 139.365 137.684 137.460 186.954 187.057 187.003
512 318.927 316.056 315.992 412.486 412.306 412.417
1024 693.102 684.980 686.608 918.059 902.694 902.613
1024 Square Check Maximum Noise Average Noise
SP 9.999520e-01 3.346482e-06 4.565234e-11
DP 1.000000e+00 1.133294e-23 1.428110e-28
End at Wed Feb 8 19:58:31 2017
###################################################
RPi 3 500 x 30 1K Single Precision FFT milliseconds
Raspbian On Demand
12.9 12.2 7.4 6.0 6.0 6.4 6.0 6.0 6.0 6.0
6.1 6.0 6.0 6.0 6.0 6.0 6.1 6.1 6.0 6.2
6.2 6.0 6.0 6.1 6.0 6.0 6.0 6.0 6.1 6.0
6.2 6.0 6.0 7.0 6.1 6.0 6.0 6.0 6.1 6.0
6.2 6.1 6.0 6.0 6.2 6.0 6.0 6.0 6.0 7.2
To
6.5 6.3 6.1 6.2 6.1 6.1 6.1 6.1 6.1 6.1
6.5 6.3 6.1 6.1 6.1 6.1 6.1 6.1 6.1 6.1
6.4 6.2 6.1 6.1 6.2 6.1 6.1 6.1 6.1 6.1
Raspbian With Stress Test
6.7 6.2 6.0 6.0 6.0 6.0 6.1 6.0 6.1 6.0
6.5 6.2 6.0 6.0 6.0 6.0 6.0 6.0 6.0 6.0
6.4 6.2 6.0 6.0 6.0 6.0 6.0 6.1 6.0 6.0
To
6.3 6.2 6.0 6.0 6.0 6.0 6.0 6.0 6.0 6.0
6.3 6.2 6.0 6.0 6.0 6.0 6.0 6.0 6.0 6.0
6.3 6.2 6.0 6.0 6.1 6.0 6.0 6.0 6.0 6.0
OpenSUSE On Demand
12.1 12.5 8.9 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.3 5.7 5.3 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.3 5.6 5.3 5.3 5.3 5.3 5.3 5.3 5.3 5.3
To
7.9 11.7 10.7 10.6 10.6 10.6 10.6 10.6 10.6 10.7
11.6 11.2 10.6 10.7 10.6 10.6 10.6 10.6 10.6 10.6
11.7 11.5 10.6 10.6 10.6 10.6 10.6 10.6 10.6 10.6
11.8 11.1 10.6 10.6 10.7 10.6 10.6 10.7 10.6 10.6
To
5.5 6.0 5.8 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.5 5.9 5.7 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.5 6.0 5.8 5.3 5.3 5.3 5.3 5.3 5.3 5.4
OpenSUSE Performance
6.1 6.0 5.4 5.5 5.4 5.3 5.3 5.3 5.3 5.3
5.5 6.0 5.8 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.5 6.1 5.8 5.3 5.3 5.3 5.3 5.3 5.3 5.3
To
5.5 6.2 5.7 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.5 6.1 5.8 5.3 5.3 5.3 5.3 5.3 5.3 5.3
5.5 6.0 5.7 5.3 5.3 5.3 5.3 5.3 5.3 5.3
Gentoo On Demand
17.5 15.4 11.8 8.6 5.4 5.4 5.4 5.4 5.4 5.4
5.5 5.8 6.0 5.4 5.5 5.4 5.5 5.4 5.4 5.4
5.5 5.6 6.1 5.4 5.5 5.4 5.5 5.5 5.4 5.4
To
5.7 6.9 5.7 5.4 5.4 5.4 5.5 5.4 5.4 5.4
5.8 6.8 5.8 5.6 5.4 5.4 5.4 5.5 5.4 5.4
5.7 6.4 5.7 5.5 5.4 5.4 5.5 5.4 5.4 5.4
Gentoo With Stress Test
5.9 7.2 5.9 5.5 5.4 5.4 5.4 5.4 5.4 5.5
5.6 6.9 5.7 5.4 5.4 5.4 5.4 5.4 5.4 5.4
5.6 6.5 5.7 5.4 5.4 5.4 5.4 5.4 5.4 5.4
5.8 7.1 5.9 5.4 5.4 5.4 5.4 5.4 5.4 5.4
To
5.7 6.8 5.7 5.4 5.4 5.4 5.4 5.4 5.4 5.4
5.7 6.7 6.1 5.4 5.4 5.4 5.4 5.4 5.4 5.4
5.8 6.6 5.6 5.4 5.4 5.4 5.4 5.4 5.4 5.4
################### Summary millisecons ###################
Each Av 30 500x30 +Overheads
Raspbian On Demand 0.206 6.17 3086 14402
Raspbian Plus Stress Test 0.202 6.07 3036 14222
OpenSUSE On Demand 0.221 6.23 3314 13035
OpenSUSE Performance 0.182 5.45 2725 10663
Gentoo On Demand 0.190 5.70 2852 8994
Gentoo Plus Stress Test 0.187 5.61 2802 8872
|
Single Core NEON Benchmarks
Some of these are essentially the same as my Android NEON Benchmarks.htm, using NEON Intrinsic Functions. Others are produced by including the compile option -funsafe-math-optimizations, alongside -mfpu=neon-vfpv4. Results for single core NEON benchmarks are included in this document, with the programs and source codes in Raspberry_Pi_Benchmarks.zip. For MultiThreading versions, see Raspberry Pi Multithreading Benchmarks.htm. and Raspberry_Pi_MP_Benchmarks.zip.
64 Bit Versions - The compiler does not have the NEON directive, but translates NEON intrinsic functions into 64 bit vector instructions. The 64 bit benchmarks and source codes are in
Rpi3-64-Bit-Benchmarks.tar.gz.
Linpack NEON Benchmarks - linpackPiNEONi, linpackPiFSSP, linpackPiNEONi64
The Android version was written, using NEON Intrinsic Functions and was converted to Linux format in linpackneon.c, compiled as LinpackPiNEONi. The standard Linux single precision version was recompiled with the additional -funsave parameter as linpackPiFSSP. Comparative performance of the intrinsic program is shown Linpack Benchmark Comparisons above.
Linpack benchmark performance is mainly determined by the daxpy function, specifically an unrolled loop with four dy[i] = dy[i] + da * dx[i] statements, accessing sequential data. NEON q registers are 128 bits or four words and there are multiply and add instructions, using three registers. The assembly code loop has two loads and one store, with linpackPiNEONi using vmla Vector Multiply Accumulate instruction and linpackPiFSSP using the faster vfma Fused Multiply Accumulate - one instruction for 4 multiplies and 4 adds.
Raspberry Pi 3 speeds are shown to be 54% to 57% faster than the non-overclocked Raspberry Pi 2, compared with a 33% faster CPU MHz.
These instructions are known to produce rounding complications, differences in results being shown below. I could not say whether they are acceptable
Raspberry Pi 3 SUSE and Gentoo 64 Bits - As both use different varieties of SIMD instructions, performance is not that much better than the 32 bit version.
linpackPiNEONi linpackPiFSSP linpackPiNEONi64
RPi 2 MFLOPS at 900 MHz 300 311
RPi 2 MFLOPS at 1000 MHz 334 348
RPi 3 MFLOPS at 1200 MHz 486 488 530
NEON Function vmla.f32 q8, q9, q10 vfma.f32 q8, q9, q10 fmla v0.4s, v1.4s, v2.4s
norm resid resid x[0]-1 x[n-1]-1
Pi, Android+NEON 1.6 3.80277634e-05 -1.38282776e-05 -7.51018524e-06
Pi 2/3 Not NEON 2.0 4.69621336E-05 -1.31130219E-05 -1.30534172E-05
Pi 3 64 NEON In 2.0 4.69621336E-05 -1.31130219E-05 -1.30534172E-05
Pi 3 64 Not NEON 2.0 4.69621336E-05 -1.31130219E-05 -1.30534172E-05
Pi 2/3 Intrinsic 2.2 5.16722466e-05 -2.38418579e-07 -5.06639481e-06
Pi 2/3 Compiled 1.9 4.62468779e-05 -1.31130219e-05 -1.30534172e-05
|
NEON Float & Integer Benchmark - NeonSpeed, NeonSpeedPi64
This was the first benchmark produced to measure speed using NEON instructions on ARM v7 CPUs using Android. It executes some of the code used in Memory Speed Benchmark, with additional tests recoded using NEON intrinsic functions. The benchmark and source code are included in Raspberry_Pi_Benchmarks.zip.
The compile command (for gcc 4.8) is shown below, where the -funsafe-math-optimizations option leads to the compiler generating NEON code for normal floating point statements. In this case, vfma Fused Multiply Accumulate instructions were generated, as opposed to vmla Vector Multiply Accumulate from the intrinsic functions. Then, vadd.i32 was produced for all integer tests. In this case, performance from both methods was quite similar.
Raspberry Pi 3 speeds were quite a bit faster than the Raspberry Pi 2 at 900 MHz. Average, minimum and maximum improvements, using data in L1 cache, were 1.71, 1.37 and 2.02 times. L2 cache ratios were 3.13, 1.90 and 2.45, with RAM, best, at 3.57, 2.92 and 5.33. The RPi 3 was also more efficient in running the NEON instructions using caches.
Examples Android results logs are also provided, to show the difference where compiled NEON instructions are not provided at 32 bits. Performance at 64 bits is also provided, for the tablet with the ARM-A53 CPU, where NEON instructions are compiled and cache based speeds similar to the RPi 3.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - 64 bit and 32 bit speeds are, again, nearly the same, using different variations of vector instructions. An exception is the slower performance from gcc 4.8 in translating NEON intrinsic functions for the v=v+s*v test.
gcc neonspeed.c cpuidc.c -lm -lrt -O3 -mcpu=cortex-a7 -mfloat-abi=hard
-mfpu=neon-vfpv4 -funsafe-math-optimizations -o NeonSpeed
##############################################
Raspberry Pi 2 CPU 900 MHz, Core 250 MHz, SDRAM 450 MHz
NEON Speed Test V 1.0 Tue Mar 17 12:06:58 2015
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 1914 1978 2049 2293 2341 2797 L1
32 1897 1951 2032 2253 2310 2745
64 1517 1543 1619 1694 1718 1915 L2
128 1417 1435 1510 1569 1594 1791
256 1414 1433 1499 1571 1593 1771
512 680 578 654 600 577 604
1024 434 403 451 414 396 409 RAM
4096 327 328 332 324 324 330
16384 333 334 338 345 330 337
65536 339 336 340 172 331 338
Max MFLOPS 479 495
Max MOPS 512 573
##################### OC ######################
Raspberry Pi 2 CPU 1000 MHz, Core 500 MHz, SDRAM 500 MHz,
over_voltage=2
NEON Speed Test V 1.0 Tue Mar 17 12:12:37 2015
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 2114 2183 2265 2531 2587 3090 L1
32 2078 2134 2228 2461 2532 3003
64 1673 1703 1785 1870 1900 2118 L2
128 1565 1581 1668 1736 1761 1974
256 1545 1577 1660 1726 1752 1951
512 1055 1042 1100 1121 1101 1178
1024 499 506 523 525 512 530 RAM
4096 429 431 440 428 433 445
16384 436 438 448 453 440 454
65536 446 443 452 229 444 458
Max MFLOPS 529 546
Max MOPS 566 633
End of test Tue Mar 17 12:12:57 2015
################### RPi 3 ###################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
NEON Speed Test V 1.0 Fri Jul 29 12:03:47 2016
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 2720 4001 3459 4225 4474 4750
32 2598 3706 3268 3879 4091 4320
64 2453 3389 3069 3526 3675 3859
128 2503 3466 3178 3598 3718 3918
256 2530 3516 3230 3649 3779 3950
512 2221 2923 2718 2964 3104 3217
1024 1262 1326 1317 1316 1324 1316
4096 1170 1213 1204 1213 1210 1195
16384 1177 1229 1218 1147 1222 1215
65536 1181 1226 1221 916 1208 1218
Max MFLOPS 680 1000
Max MOPS 865 1056
End of test Fri Jul 29 12:04:07 2016
################ RPi 3 SUSE ################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 2393 4497 3479 4252 4783 4932
32 2299 4081 3284 3910 4362 4441
64 2193 3663 3067 3593 3896 3904
128 2227 3701 3144 3603 3909 3926
256 2226 3693 3153 3586 3896 3923
512 1913 3461 2958 3358 3609 3577
1024 1271 1408 1406 1364 1363 1422
4096 1130 1207 1219 1158 1186 1208
16384 1102 1116 1132 1037 1111 1116
65536 1089 1095 1107 810 1091 1095
Max MFLOPS 598 1124
Max MOPS 870 1063
############### RPi 3 Gentoo #################
16 2352 4419 3418 4178 4700 4850
32 2330 4355 3388 4122 4664 4806
64 2177 3678 3066 3607 3932 3923
128 2230 3772 3174 3683 4012 4007
256 2240 3785 3199 3694 4024 4024
512 1936 3095 2690 2996 3241 3279
1024 1143 1203 1253 1162 1178 1229
4096 1097 1182 1182 1115 1138 1192
16384 1103 1193 1188 1138 1143 1201
65536 1109 1199 1200 866 1165 1214
Max MFLOPS 588 1104
Max MOPS 855 1045
################ RPi 3 SUSE ##################
Compiled for 64 bit ARM v8a+fp+sim
16 2390 3001 3187 3925 4135 4372
32 2381 2985 3187 3894 4135 4371
64 2174 2674 2817 3300 3468 3608
128 2177 2704 2859 3341 3512 3654
256 2200 2712 2848 3315 3520 3637
512 2010 2400 2539 2894 3018 3094
1024 1238 1314 1338 1356 1382 1385
4096 1098 1148 1159 1158 1170 1188
16384 1063 1082 1120 1041 1109 1114
65536 1063 1067 1108 815 1092 1097
Max MFLOPS 598 750
Max MOPS 797 981
#################### Android #####################
Tab 2 A8-50, 1.3 GHz quad core 64 bit ARM Cortex-A53
ARM/Intel NeonSpeed Benchmark V1.2 13-Aug-2015 16.32
Compiled for 32 bit ARM v7a
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 971 3853 1807 4059 3957 4397
32 970 3812 1800 3983 3891 4323
64 927 3228 1605 3038 3269 3521
128 926 3321 1681 3343 3354 3596
256 936 3386 1693 3449 3413 3667
512 898 2889 1578 2996 2927 3118
1024 794 1859 1345 2057 1996 1924
4096 794 1796 1250 1788 1813 1835
16384 792 1773 1270 1820 1829 1864
65536 796 1811 1289 1852 1832 1880
Total Elapsed Time 11.3 seconds
ARM/Intel NeonSpeed Benchmark V1.2 13-Aug-2015 16.37
Compiled for 64 bit ARM v8a
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 3054 4055 3605 4376 4911 5094
32 2922 3787 3435 4198 4546 4682
64 2795 3514 3259 3658 4050 4116
128 2886 3529 3373 3924 4148 3963
256 2883 3641 3264 3942 4193 4276
512 2454 3165 2985 3385 3586 3542
1024 1633 2000 1835 2043 2114 2105
4096 1738 1893 1899 1900 1956 1955
16384 1757 1870 1886 1802 1921 1846
65536 1755 1875 1870 1903 1936 1937
Max MFLOPS 764 1014
Max MOPS 901 1094
Total Elapsed Time 10.2 seconds
#################### Android #####################
Nexus 7 Quad 1200 MHz Cortex-A9, Android 4.1.2
Android NeonSpeed Benchmark 15-Dec-2012 14.38
Vector Reading Speed in MBytes/Second
Memory Float v=v+s*v Int v=v+v+s Neon v=v+v
KBytes Norm Neon Norm Neon Float Int
16 860 2575 2325 2918 3053 3245 L1
32 950 2551 2400 2823 2944 3131
64 744 1396 1329 1434 1465 1496 L2
128 713 1342 1319 1365 1392 1417
256 714 1339 1311 1357 1377 1400
512 708 1323 1299 1348 1358 1383
1024 608 875 869 917 930 952
4096 460 493 492 481 488 504 RAM
16384 460 498 487 507 506 504
65536 459 495 469 251 503 505
Max MFLOPS 238 644
Max MOPS 600 730
|
MemSpeed NEON - memSpdPiNEON
This is compiled from the Memory Speed Benchmark source code, using the -funsafe-math-optimizations additional compile parameter. An example of results in included above. The memspeedPiA7 benchmarks, compiled with the -mfpu=neon-vfpv4 option, generated NEON instructions for integer arithmetic (vadd.i32 q8, q8, q10), as with memSpdPiNEON. leading to the same performance. Then four scalar fused multiply and add instructions ( fadds s12, s8, s12) were generated for the single precision (SP) floating point test, as opposed to NEON (vfma.f32 q8, q9, q6) with the new benchmark, with similar differences for the second set of calculations. Details are above, and maximum MFLOPS below. showing a gain of approaching 50% through using NEON instructions. Note: currently NEON floating point functions are only available at single precision. For reference, double precision (DP) results are also shown.
Both compilations for memspeedPiA7 and memSpdPiNEON have NEON integer instructions of the form vadd.i32 q8, q8, q9, providing significant performance gains, as shown by integer MOPS below.
Raspberry Pi 3 - Best gains were on Integer MOPS of 1.5 to 1.7 times 900 MHz RPi 2. Some double precision speeds were slower than clock MHz ratio of 1.33.
Raspberry Pi 3 SUSE and Gentoo 64 Bits - Compile options not available, but see
Memory Speed Benchmark above.
MFLOPS
memspeedPiA6 memspeedPiA7 memSpdPiNEON
Raspberry Pi 2
SP MFLOPS at 900 MHz 333 299 445
SP MFLOPS at 1000 MHz 351 330 493
DP MFLOPS at 900 MHz 133 175 174
DP MFLOPS at 1000 MHz 148 193 193
Raspberry Pi 3
SP MFLOPS at 1200 MHz 444 454 594
DP MFLOPS at 1200 MHz 208 203 203
INT MOPS
memspeedPiA6 memspeedPiA7 memSpdPiNEON
Raspberry Pi 2
Int MOPS at 900 MHz 323 512 509
Int MOPS at 1000 MHz 333 566 562
Raspberry Pi 3
Int MOPS at 1200 MHz 485 865 864
|
Maximum One Core Single Precision MFLOPS
notOpenMP-MFLOPS, notOpenMP-MFLOPS64, MP-MFLOPSPiA7, MP-MFLOPS64MP-NeonMFLOPS, MP-NeonMLOPS64, MP-MFLOPSPiNeon
All of these carry out the same calculations executed in the form x[i] = (x[i] + a) * b - (x[i] + c) * d + (x[i] + e) * f with 2, 8 or 32 operations per input data word. Full results are provided below. OpenMP-MFLOPS automatically uses all available cores and notOpenMP-MFLOPS uses one core with no MP overheads. All others use 1, 2, 4 and 8 threads, best MFLOPS from 1 thread shown here.
The compilation for PiA7 MP-MFLOPS includes an option to use NEON instructions, but does not do so in the 32 bit version. MP-MFLOPS64 and OpenMP-MFLOPS64 varieties use the simple “-march=armv8-a” directive.
The compiled MP-MFLOPSPiNeon and OpenMP benchmarks include “-funsafe-math-optimizations” parameter that produces SIMD instructions. This option is not available at 64 bits. MP-NeonMFLOPS and MP-NeonMFLOPS64 use a well ordered structure of NEON intrinsic functions, clearly suitable for SIMD operation. gcc neonmflops.c cpuidc.c -lm -lrt -O3 -mcpu=cortex-a7 -mfloat-abi=hard -mfpu=neon-vfpv4 -funsafe-math-optimizations -lpthread -o MP-NeonMFLOPS
Raspberry Pi 3 speeds were 1.75 times faster than model 2, at two operations per word, increasing to 2.28 times at 32 operations per word.
64 Bit Versions MPMFLOPS results were between 2.3 to 4 time faster than the 32 bit version, due to using SIMD instructions. The notOpenMP-MFLOPS performance was similar with both SIMD. MP-NeonMLOPS64 intrinsics were compiled as more effective vector instructions, to produce gains between 1.25 and 1.54 times.
Cortex-A53 based Android tablet results are also shown, with similar performance. Details are in Android 64 Bit Benchmarks.htm.
Reliability Tests - The MP-MFLOPS functions were used in stress testing programs that have command line options to define which function to use and running time. See
Reliability Tests,
64 Bit Reliability Tests
and
Raspberry Pi 2 and 3 Stress Tests.htm.
The original versions, such as burninfpuPiA7 and MFLOPS benchmarks, produced less the 1.5 MFLOPS per MHz, where the test functions were driven by repetitive external calls. A later one, burninfpuPi2, in
Raspberry_Pi_2_Stress_Tests.zip,
included the repeat calls within the functions, and unrolled some of the calculations, producing some much faster speeds. The 64 bit version, burninfpuPi64, in
Rpi3-64-Bit-Benchmarks.tar.gz,
produced similar superior performance, as reflected in the results below.
Single Precision MFLOPS
MHz 2 Ops/word 8 Ops/word 32 Ops/word
Raspberry Pi 2
notOpenMP-MFLOPS 900 398 777 692
notOpenMP-MFLOPS 1000 461 861 765
burninfpuPiA7 L2 900 450 777 685
Raspberry Pi 3 1200
notOpenMP-MFLOPS 716 1697 1581
MP-MFLOPSPiA7 182 693
MP-MFLOPSPiNeon Compiled 782 1672
MP-NeonMFLOPS Intrinsics 583 1706
burninfpuPiA7 L2 cache data 721 1644 1703
notOpenMP-MFLOPS64 718 1720 1496
MP-MFLOPS64 730 1579
MP-MFLOPSNeon Compiled N/A
MP-NeonMLOPS64 Intrinsics 729 2640
burninfpuPi64 L2 cache data 1721 3796 1562
Cortex A53 Android Tablet 1300 MHz 1 Core Threaded
SP MFLOPS 32 bit Intrinsics 619 1426
SP MFLOPS 64 bit Intrinsics 726 2639
|
MultiThreading Benchmarks
These are essentially the same as my Android Multithreading Benchmarks.htm. Except for OpenMP tests, all run the benchmarks using 1, 2, 4 and 8 threads. Those that use caches and RAM have data sizes around 12.8 KB, 128 KB and 12.8 MB. The test runs considered below are to provide Raspberry Pi 3 comparisons of 64 bit versus 32 bit operation. Tne new benchmarks and source codes are included in Rpi3-64-Bit-Benchmarks.tar.gz. Details and results of earlier measurements can be found in Raspberry Pi Multithreading Benchmarks.htm, with benchmarks and source codes in Raspberry_Pi_MP_Benchmarks.zip.
Where appropriate, the benchmarks show that the same numerical results are produced using a varying number of threads. Example results for different compilations of MP-MFLOPS are shown below. At 32 bits, the benchmark was compiled with normal floating point parameters, secondly with additional NEON directives and thirdly with NEON intrinsic functions, replacing normal C code.
At 64 bits, the first and last of these was appropriate. The intrinsic functions were translated into different forms of vector instructions. The end products produced variations in numerical results, as shown in the following.
################ MP-MFLOPS FORMAT #################
MP-MFLOPS armv8 64Bit Fri Feb 24 13:30:16 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 730 717 413 1579 1575 1541
2T 1361 1351 389 3075 3145 2849
4T 2259 2417 370 5399 6114 4944
8T 2226 1919 352 5346 5948 4986
Results x 100000, 0 indicates ERRORS
1T 76406 97075 99969 66015 95363 99951
2T 76406 97075 99969 66015 95363 99951
4T 76406 97075 99969 66015 95363 99951
8T 76406 97075 99969 66015 95363 99951
End of test Fri Feb 24 13:30:21 2017
MP-MFLOPS Linux/ARM V7A
1T 76406 97075 99969 66015 95363 99951
MP-MFLOPS Compiled NEON
1T 76406 97075 99969 66008 95367 99951
MP-MFLOPS NEON Intrinsics
1T 76406 97075 99969 66014 95363 99951
MP-MFLOPS 64 Bit
1T 76406 97075 99969 66015 95363 99951
MP-MFLOPS NEON Intrinsics 64 Bit
1T 76406 97075 99969 66015 95363 99951
MP-MFLOPS Double Precision
1T 76384 97072 99969 66065 95370 99951
MP-MFLOPS 64 Bit DP
1T 76384 97072 99969 66065 95370 99951
|
MP-MFLOPS - MP-MFLOPSPiA7, MP-MFLOPSDP, MP-MFLOPSPi64, MP-MFLOPSPi64DP
MP-MFLOPS measures floating point speed on data from caches and RAM. The first calculations are as used in Memory Speed Benchmark, with a multiply and an add per data word read. Others use more calculations in the form of x[i] = (x[i] + a) * b - (x[i] + c) * d + (x[i] + e) * f with 8 or 32 operations per input data word. Each thread carries out the same calculations but accesses different segments of the data. The result, on cache based calculations, is often performance proportional to the number of cores used.
64 Bit vs 32 Bit - Bearing in mind that results represented by the third column are likely to be dependent on memory speed, average speed gains of the first cache based tests were four times faster, with 25% improvement from RAM. Then, with 32 operations per word, a 2.19 speed gain applied. Double precision improvements were much less.
Single/Double Precision - Results were quite similar using the 32 bit benchmark. At 64 bits, average improved SP speed was 2.1 times, at 2 operations per word, and demonstrated a 37% improvement with the higher number of calculations.
SUSE vs Gentoo - Exccept for the isolated blip, that can be expected on these type of tests, performance was essentially the same.
MP gains - Ignoring 12800 memory based tests, that can be lower, four versus 1 thread gains averaged 3.38 times, with a maximum of 3.88 times.
Comparison with other MP-MFLOPS benchmarks - see
Maximum 1 Core MFLOPS above.
###################### RPi 3 #######################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
MP-MFLOPS Linux/ARM V7A v1.0 Tue Aug 30 14:16:59 2016
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 159 181 178 690 692 685
2T 342 364 353 1384 1386 1368
4T 466 501 456 2451 2473 2633
8T 581 643 479 2618 2502 2550
Results x 100000
1T 76406 97075 99969 66015 95363 99951
########### RPi 3 V7A2 Double Precision ############
MP-MFLOPS Double Precision v1.0 Wed Sep 7 17:07:12 2016
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 143 182 171 678 680 674
2T 343 361 240 1360 1360 1335
4T 441 712 240 2232 2208 2185
8T 406 593 241 2345 2315 2272
Results x 100000
1T 76384 97072 99969 66065 95370 99951
################## RPi 3 SUSE #####################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-MFLOPS armv8 64Bit Fri Feb 24 13:30:16 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 730 717 413 1579 1575 1541
2T 1361 1351 389 3075 3145 2849
4T 2259 2417 370 5399 6114 4944
8T 2226 1919 352 5346 5948 4986
Results x 100000
1T 76406 97075 99969 66015 95363 99951
########### RPi 3 SUSE Double Precision ############
MP-MFLOPS armv8 64Bit Double Precision Fri Feb 24 13:53:27 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 365 356 198 1233 1230 1127
2T 659 657 166 2401 2397 1923
4T 1200 927 176 4678 4640 2776
8T 1051 1039 174 4678 4682 2909
Results x 100000
1T 76384 97072 99969 66065 95370 99951
################ RPi 3 Gentoo ######################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-MFLOPS armv8 64Bit Thu Mar 2 16:48:04 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 709 634 391 1541 1535 1497
2T 1095 1072 355 3095 3023 2925
4T 1503 2249 350 5419 6070 5230
8T 2475 1985 381 5440 5975 5030
Results x 100000
1T 76406 97075 99969 66015 95363 99951
########## RPi 3 Gentoo Double Precision ###########
MP-MFLOPS armv8 64Bit Double Precision Thu Mar 2 16:52:33 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 354 327 197 1205 1187 1081
2T 685 691 201 2411 2369 1763
4T 1202 1063 202 4681 4595 2064
8T 1145 1077 201 4520 4581 2663
Results x 100000
1T 76384 97072 99969 66065 95370 99951
|
MP-Whetstone - MP-WHETSPiA7, MP-WHETSPi64
Multiple threads each run the eight test functions at the same time, but with some dedicated variables. Measured speed is based on the last thread to finish, with Mutex functions, used to avoid the updating conflict by only allowing one thread at a time to access common data. Again performance is generally proportional to the number of cores used. There can be some significant differences from the single CPU Whetstone benchmark results on particular tests due to a different compiler being used.None of the test functions are suitable for SIMD operation, with the simpler instructions being used can lead to some 32 bit tests being faster than those compiled for 64 bits. The Fixed Point MIPS loops are clearly over optimised but, in any case, the time taken has little influence on the overall MWIPS rating.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
MP-Whetstone Benchmark Linux/ARM V7A v1.0 Mon Aug 15 19:34:21 2016
Using 1, 2, 4 and 8 Threads
MWIPS MFLOPS MFLOPS MFLOPS Cos Exp Fixpt If Equal
1 2 3 MOPS MOPS MOPS MOPS MOPS
1T 723.1 517.2 517.0 254.9 12.1 8.8 5853.9 1181.8 1189.8
2T 1464.7 960.5 1025.1 511.3 24.1 18.5 11899.0 2381.2 2385.7
4T 2902.3 1696.4 1867.3 1013.4 47.8 36.8 19754.6 4541.3 4687.1
8T 3004.0 2747.8 2569.0 1066.4 48.6 38.0 25502.9 6075.2 5610.8
Overall Seconds 4.77 1T, 4.74 2T, 4.88 4T, 9.76 8T
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-Whetstone Benchmark armv8 64 Bit Tue Mar 7 23:27:25 2017
Using 1, 2, 4 and 8 Threads
MWIPS MFLOPS MFLOPS MFLOPS Cos Exp Fixpt If Equal
1 2 3 MOPS MOPS MOPS MOPS MOPS
1T 985.3 336.2 336.3 287.7 18.1 12.3 1478579.3 2331.7 1198.9
2T 1964.8 670.7 672.6 566.7 36.2 24.6 2794892.5 4724.7 2372.4
4T 3900.7 1248.1 1330.8 1139.9 71.6 48.9 3931546.6 9424.8 4747.9
8T 3925.4 1314.4 1349.8 1146.9 72.0 49.1 6508657.2 9578.2 4779.7
Overall Seconds 4.94 1T, 4.98 2T, 5.14 4T, 10.11 8T
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-Whetstone Benchmark armv8 64 Bit Wed Mar 8 11:48:21 2017
Using 1, 2, 4 and 8 Threads
MWIPS MFLOPS MFLOPS MFLOPS Cos Exp Fixpt If Equal
1 2 3 MOPS MOPS MOPS MOPS MOPS
1T 1045.1 322.6 330.4 282.5 20.4 12.8 1527755.4 2316.1 1178.5
2T 2091.3 653.1 661.0 563.9 40.9 25.5 2764929.6 4599.8 2356.7
4T 2460.5 1199.4 1314.7 1124.8 41.2 27.3 5201735.3 9305.0 2480.2
8T 3394.6 1422.0 1697.0 1192.2 56.4 44.8 4006323.7 10229.6 2480.3
Overall Seconds 5.02 1T, 5.02 2T, 8.57 4T, 13.51 8T
|
MP-Dhrystone - MP-DHRYPiA7, MP-DHRYPi64
This runs multiple copies of the whole program at the same time. Dedicated data arrays are used for each thread but there are numerous other variables that are shared. The latter reduces performance gains via multiple threads and, in some cases, these can be slower than using a single thread.The only reliable measurement, for comparison purposes, is the single thread speed. Here, the 64 bit version indicates a speed improvement of 50%, over the 32 bit program.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
MP-Dhrystone Benchmark Linux/ARM V7A v1.0 Mon Aug 15 19:47:57 2016
Using 1, 2, 4 and 8 Threads
Threads 1 2 4 8
Seconds 0.95 1.12 1.59 3.04
Dhrystones per Second 4229473 7124952 10091677 10523432
VAX MIPS rating 2407 4055 5744 5989
Internal pass count correct all threads
End of test Mon Aug 15 19:48:04 2016
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-Dhrystone Benchmark armv8 64 Bit Tue Mar 7 22:20:45 2017
Using 1, 2, 4 and 8 Threads
Threads 1 2 4 8
Seconds 0.63 0.77 1.40 2.77
Dhrystones per Second 6343818 10382333 11459690 11533058
VAX MIPS rating 3611 5909 6522 6564
Internal pass count correct all threads
End of test Tue Mar 7 22:20:51 2017
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-Dhrystone Benchmark armv8 64 Bit Wed Mar 8 11:34:32 2017
Using 1, 2, 4 and 8 Threads
Threads 1 2 4 8
Seconds 0.63 0.78 2.75 3.11
Dhrystones per Second 6367171 10213192 5810865 10285768
VAX MIPS rating 3624 5813 3307 5854
Internal pass count correct all threads
End of test Wed Mar 8 11:34:40 2017
|
MP-BusSpeedPiA7, MP-BusSpeedPi64
This runs integer read only tests using caches and RAM, each thread accessing the same data sequentially. To start with, data is read with large address increments to demonstrate burst data transfers. Performance gains, using L1 cache, can be proportional to the number of cores, but not quite so using L2. The program is designed to produce maximum throughput over buses and demonstrates the fastest RAM speeds using multiple cores.In the original version, each thread started reading data from the same starting point. This produced acceptable results until shared L2 caches appeared. Then it produced excessive RAM speeds, using more than one thread. With version 2, as used for the following, each thread starts reading from different addresses, providing more realistic results.
The 32 bit ARM V7A compilation produced the expected pattern of speeds, doubling up with decreasing address increments, where burst reading is used, and improving L1 cache data transfer rate, also providing reasonable MP performance gains. The 64 bit results were much slower and, particularly, demonstrated slower L1 cache speeds at reducing address increments. The reason can be identified from a disassembly of the code used for the important “Read All” tests. Here, the C code has a loop with 64 AND operations. The 32 bit version translated these arithmetic operations into 16 NEON four way vector instructions. The 64 bit version had 64 scalar AND and 64 data load instructions,
overall executing 2.5 times the number of instructions, than the 32 bit version, to deal with the same amount of data.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
MP-BusSpd ARM V7A v2 Sun Jul 24 09:26:21 2016
MB/Second Reading Data, 1, 2, 4 and 8 Threads
Staggered starting addresses to avoid caching
KB Inc32 Inc16 Inc8 Inc4 Inc2 RdAll
12.3 1T 3011 3715 3792 4080 4400 4149
2T 5391 6873 7125 7827 8466 8124
4T 8622 11926 13488 15276 16419 13422
8T 4922 7930 9659 11732 13307 11995
122.9 1T 565 563 1070 1792 2830 3865
2T 886 901 1762 3225 5402 7584
4T 901 921 1863 3727 7185 13816
8T 874 919 1762 3712 6269 9242
12288 1T 120 125 244 420 968 1926
2T 126 128 246 537 1000 2184
4T 110 118 231 443 990 1824
8T 120 137 262 517 1043 2124
End of test Sun Jul 24 09:26:33 2016
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-BusSpd armv8 64 Bit Tue Mar 7 22:44:44 2017
MB/Second Reading Data, 1, 2, 4 and 8 Threads
Staggered starting addresses to avoid caching
KB Inc32 Inc16 Inc8 Inc4 Inc2 RdAll
12.3 1T 2885 2407 2576 2093 1460 1521
2T 4764 4197 4944 3960 2890 2929
4T 6842 6443 8343 6997 5360 5667
8T 4563 4352 6368 6106 4600 5184
122.9 1T 545 584 1043 1596 1456 1462
2T 872 890 1718 3001 2807 2861
4T 828 900 1859 3687 5523 5789
8T 866 913 1875 3691 5477 5704
12288 1T 113 123 244 486 915 1145
2T 69 125 226 435 1149 1964
4T 86 91 268 490 998 2092
8T 89 104 219 480 976 1798
End of test Tue Mar 7 22:44:57 2017
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-BusSpd armv8 64 Bit Wed Mar 15 11:23:10 2017
MB/Second Reading Data, 1, 2, 4 and 8 Threads
Staggered starting addresses to avoid caching
KB Inc32 Inc16 Inc8 Inc4 Inc2 RdAll
12.3 1T 2699 2430 2645 2052 1467 1493
2T 4687 4153 4854 3797 2827 2933
4T 6825 6472 8358 7148 4789 5680
8T 4272 4146 5928 5705 4588 4977
122.9 1T 550 568 1022 1615 1427 1472
2T 872 852 1691 3027 2821 2932
4T 821 894 1845 3654 5570 5822
8T 896 892 1850 3602 5136 5439
12288 1T 108 115 224 455 852 1085
2T 51 120 216 432 856 1722
4T 68 109 229 402 887 1604
8T 67 109 240 583 975 1834
End of test Wed Mar 15 11:23:23 2017
|
MP-RandMemPiA7, MP-RandMemPi64
The benchmark has cache and RAM read only and read/write tests using sequential and random access, each thread accessing the same data but starting at different points. It uses the Mutex functions as in Whetstone above, sometimes leading to no performance gains using multiple threads. Although performance via the L1 cache, L2 cache and RAM can be different, it is normally consistent, in each of these areas, during read/write tests. With the read only tests, performance via L1 cache typically produced a throughput gain of 3.6 to 3.8 times using four cores, but somewhat less so, using shared data in L2 cache. Random access is also demonstrated as being relatively slow where burst data transfers are involved. Note that performance can vary somewhat, and a few runs might be needed to demonstrate best case results.L1 cache 64 bit speeds are shown to be 43% faster than those at 32 bits, for read only tests and 20% via L2 cache, but in the same areas, up to 20% slower when writing is involved.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
MP-RandMem Linux/ARM V7A v1.0 Mon Aug 15 19:37:27 2016
MB/Second Using 1, 2, 4 and 8 Threads
KB SerRD SerRDWR RndRD RndRDWR
12.3 1T 2907 3773 2917 3790
2T 5480 3768 5187 3775
4T 11198 3679 10960 3712
8T 10094 3697 10038 3685
122.9 1T 2673 3340 686 892
2T 5031 3386 1251 888
4T 9398 3378 2002 890
8T 9291 3370 1916 886
12288 1T 1896 899 50 64
2T 2535 900 98 65
4T 2878 896 137 64
8T 2631 897 130 65
End of test Mon Aug 15 19:38:14 2016
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-RandMem armv8 64 Bit Tue Mar 7 23:20:26 2017
MB/Second Using 1, 2, 4 and 8 Threads
KB SerRD SerRDWR RndRD RndRDWR
12.3 1T 4251 3142 4180 3074
2T 7641 3118 7586 3120
4T 15308 3077 15309 3060
8T 14920 3041 14761 3043
122.9 1T 3462 2848 889 858
2T 6356 2899 1590 846
4T 11078 2910 2013 857
8T 11069 2917 2018 843
12288 1T 1858 873 83 67
2T 2331 864 148 66
4T 2359 878 160 66
8T 2108 890 163 66
End of test Tue Mar 7 23:21:12 2017
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-RandMem armv8 64 Bit Sun Mar 12 11:18:10 2017
MB/Second Using 1, 2, 4 and 8 Threads
KB SerRD SerRDWR RndRD RndRDWR
12.3 1T 4268 3087 4267 3087
2T 7520 3062 7525 3055
4T 15295 3021 14322 3021
8T 15200 2973 14897 2999
122.9 1T 3384 2851 872 839
2T 6314 2877 1523 838
4T 11027 2871 2012 836
8T 10344 2864 1937 835
12288 1T 1795 846 78 63
2T 1933 771 136 63
4T 1760 845 152 63
8T 1972 843 138 63
End of test Sun Mar 12 11:18:56 2017
|
OpenMP-MFLOPS, notOpenMP-MFLOPS, OpenMP-MFLOPS64, notOpenMP-MFLOPS64
The benchmark uses the same source code program calculations as the original MP_MFLOPS benchmark for Linux with MP-MFLOPS above using a cut down version, implemented to use on Android devices. OpenMP-MFLOPS benchmark uses the simplest OpenMP directive, #pragma omp parallel for, before the for loops where parallelisation might be expected, and a -fopenmp compile parameter. Also, notOpenMP-MFLOPS is the same, without the compile parameter.Samples of full results are below for 32 bit and 64 bit benchmarks. At this time OpenMP libraries are not included in gcc for 64 bit Gentoo but, of course, the notOpenMP-MFLOPS64 program could be run.
Below the detailed results are performance comparisons and a table of numeric results. Although the latter were constant during a test run, variations occur on values from different compilations. In should be noted that minimum data size is 400 KB, or in L2 cache using one core or four cores.
64 Bit vs 32 Bit - Main gains were at 32 operations per word read, little different with the single core test, maybe a little slower, but up to 2.8 times faster using all cores.
MP gains - The main gains were on tests using L2 cache and 32 calculations per word, with maximum of 2.72 times at 32 bits and 3.89 times at 64 bits.
Different Numeric Results - 32 bit and 64 bit results can be different. The with and without OpenMP values are the same, except for 32 operations per word at 32 bits. Here, the same type of instructions are used, but in a different order.
Comparison with other MP-MFLOPS benchmarks - see
Maximum 1 Core MFLOPS
above.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Not OpenMP MFLOPS Benchmark 1 Mon Aug 15 19:23:03 2016
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 100000 2 2500 0.697952 716 0.929538 Yes
Data in & out 1000000 2 250 1.160158 431 0.992550 Yes
Data in & out 10000000 2 25 1.140070 439 0.999250 Yes
Data in & out 100000 8 2500 1.178477 1697 0.957126 Yes
Data in & out 1000000 8 250 1.442497 1386 0.995524 Yes
Data in & out 10000000 8 25 1.428921 1400 0.999550 Yes
Data in & out 100000 32 2500 5.060230 1581 0.890268 Yes
Data in & out 1000000 32 250 5.203246 1538 0.988078 Yes
Data in & out 10000000 32 25 5.203889 1537 0.998806 Yes
OpenMP MFLOPS Benchmark 1 Sat Jul 30 13:01:12 2016
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 100000 2 2500 0.363631 1375 0.929538 Yes
Data in & out 1000000 2 250 1.133716 441 0.992550 Yes
Data in & out 10000000 2 25 1.150107 435 0.999250 Yes
Data in & out 100000 8 2500 0.432833 4621 0.957126 Yes
Data in & out 1000000 8 250 1.177219 1699 0.995524 Yes
Data in & out 10000000 8 25 1.151536 1737 0.999550 Yes
Data in & out 100000 32 2500 3.845114 2081 0.890232 Yes
Data in & out 1000000 32 250 3.754590 2131 0.988068 Yes
Data in & out 10000000 32 25 3.737356 2141 0.998785 Yes
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
notOpenMP MFLOPS64 Fri Feb 24 15:48:41 2017
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 100000 2 2500 0.696362 718 0.929538 Yes
Data in & out 1000000 2 250 1.202102 416 0.992550 Yes
Data in & out 10000000 2 25 1.140033 439 0.999250 Yes
Data in & out 100000 8 2500 1.162491 1720 0.957117 Yes
Data in & out 1000000 8 250 1.504922 1329 0.995518 Yes
Data in & out 10000000 8 25 1.478444 1353 0.999549 Yes
Data in & out 100000 32 2500 5.346043 1496 0.890215 Yes
Data in & out 1000000 32 250 5.482719 1459 0.988088 Yes
Data in & out 10000000 32 25 5.477190 1461 0.998796 Yes
OpenMP MFLOPS64 Fri Feb 24 16:49:35 2017
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 100000 2 2500 0.229756 2176 0.929538 Yes
Data in & out 1000000 2 250 1.230560 406 0.992550 Yes
Data in & out 10000000 2 25 1.159971 431 0.999250 Yes
Data in & out 100000 8 2500 0.344756 5801 0.957117 Yes
Data in & out 1000000 8 250 1.245537 1606 0.995518 Yes
Data in & out 10000000 8 25 1.187876 1684 0.999549 Yes
Data in & out 100000 32 2500 1.373730 5824 0.890215 Yes
Data in & out 1000000 32 250 1.519274 5266 0.988088 Yes
Data in & out 10000000 32 25 1.469316 5445 0.998796 Yes
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
notOpenMP MFLOPS64 Thu Mar 2 17:05:47 2017
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 100000 2 2500 0.739649 676 0.929538 Yes
Data in & out 1000000 2 250 1.230036 406 0.992550 Yes
Data in & out 10000000 2 25 1.179612 424 0.999250 Yes
Data in & out 100000 8 2500 1.196997 1671 0.957117 Yes
Data in & out 1000000 8 250 1.560925 1281 0.995518 Yes
Data in & out 10000000 8 25 1.483354 1348 0.999549 Yes
Data in & out 100000 32 2500 5.437056 1471 0.890215 Yes
Data in & out 1000000 32 250 5.585995 1432 0.988088 Yes
Data in & out 10000000 32 25 5.576582 1435 0.998796 Yes
OpenMP MFLOPS64 - OpenMP libray file not available
################### Comparison ###################
Words Ops/ MP Gains 64 Bit Gains
Word 32 Bit 64 Bit Not OMP
100000 2 1.92 3.03 1.00 1.58
1000000 2 1.02 0.98 0.97 0.92
10000000 2 0.99 0.98 1.00 0.99
100000 8 2.72 3.37 1.01 1.26
1000000 8 1.23 1.21 0.96 0.95
10000000 8 1.24 1.24 0.97 0.97
100000 32 1.32 3.89 0.95 2.80
1000000 32 1.39 3.61 0.95 2.47
10000000 32 1.39 3.73 0.95 2.54
#################### Numeric Results #####################
Words Ops/ Not OMP Not OMP
Word 32 Bit 32 Bit 64 Bit 64 Bit
100000 2 0.929538 0.929538 0.929538 0.929538
1000000 2 0.992550 0.992550 0.992550 0.992550
10000000 2 0.999250 0.999250 0.999250 0.999250
100000 8 0.957126 0.957126 0.957117 0.957117
1000000 8 0.995524 0.995524 0.995518 0.995518
10000000 8 0.999550 0.999550 0.999549 0.999549
100000 32 0.890268 0.890232 0.890215 0.890215
1000000 32 0.988078 0.988068 0.988088 0.988088
10000000 32 0.998806 0.998785 0.998796 0.998796
|
OpenMP-MemSpeed2, NotOpenMP-MemSpeed2, OpenMP-MemSpeed264, NotOpenMP-MemSpeed264
This is the same as Memory Speed Benchmark but with measurements extending to test more memory, also using the OpenMP directive and compile parameter. The NotOpenMP tests use the same code without specifying a compilation using OpenMP. These allow comparisons of MP performance gains over the full range of memory use. At this time, OpenMP was not available in Gentoo, but the NotOpernMP benchmark was run.MP Gains and Losses As all the test functions involve writing back results, with few instructions in between, MP benefits are often not that good. With the OpenMP 64 bit version, integer tests averaged 12% to 30% slower, but faster on floating point calculations 1.62 to 2.45 times DP and 1.25 to 1.88 times SP. 32 bit ratios were 33% to 61%, 2.85 to 3.75 and 1.44 to 1.88 respectively.
64/32 Bit Ratios 64 bit versus 32 bit comparisons were also diverse, starting with the former’s RAM speeds being somewhat slower. For cache based data, average integer, DP and SP performance ratios, with OpenMP, were 1.23 to 1.45, 0.82 to 1.05 and 0.71 to 1.04, then with notOpenMP, 1.05 to 1.35, 1.63 to 2.60 and 0.96 to 1.35.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Memory Reading Speed Test OpenMP Version 2 by Roy Longbottom
Start of test Mon Sep 5 14:27:38 2016
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
4 5518 2990 1309 8808 4732 1455 15426 7656 1244
8 5414 3115 1322 10150 5068 1470 14323 8301 1254
16 5503 3143 1270 10255 5154 1378 16743 8043 1221
32 5507 3145 1344 10142 5089 1458 16572 7732 1206
64 5033 2999 1257 9230 4867 1419 16012 7869 1228
128 5255 3041 1258 9372 5014 1365 9452 8192 1252
256 5266 3093 1282 9401 5006 1372 8418 7864 1313
512 4494 2765 1358 7248 4482 1332 5748 5460 1410
1024 3810 2683 1078 4425 3668 1155 1753 1732 1265
2048 2008 1425 1098 2274 2214 980 1086 1094 1333
4096 3972 2413 1075 4628 3672 945 1058 1057 839
8192 1597 2435 920 3671 3649 1199 1059 1067 1043
16384 3838 1624 1867 4440 1550 1108 1065 1076 1166
32768 1658 2273 1695 4227 1876 1054 1066 1039 921
65536 3657 1247 1286 4839 3801 1308 1053 1046 1133
131072 990 655 810 1260 932 826 1129 1083 619
End of test Mon Sep 5 14:28:08 2016
####################### RPi 3 Not OMP ###########################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Memory Reading Speed Test Not OpenMP Version 2 by Roy Longbottom
Start of test Mon Sep 5 14:28:22 2016
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
4 785 2536 3789 2360 3448 3787 2670 2693 2692
8 1594 2547 3812 2389 3465 3812 2715 2716 2716
16 1595 2551 3824 2392 3477 3823 2727 2728 2728
32 1556 2435 3564 2300 3272 3565 2730 2722 2723
64 1513 2314 3330 2189 3091 3327 2599 2435 2435
128 1516 2312 3357 2188 3118 3353 2635 2569 2569
256 1521 2316 3381 2187 3130 3384 2676 2618 2617
512 1419 2034 2765 1977 2674 2835 2593 2481 2524
1024 1113 1379 1544 1348 1521 1543 1691 1583 1586
2048 995 1203 1282 1193 1277 1257 1263 1231 1232
4096 992 1196 1248 1178 1252 1259 1203 1176 1166
8192 1041 1237 1290 1213 1298 1291 927 943 954
16384 1052 1262 1311 1229 1252 1303 874 866 867
32768 1053 1271 1317 1239 1325 1303 995 987 991
65536 1057 1281 1323 1245 1343 1316 920 920 918
131072 1057 1283 1323 1184 1350 1327 856 849 840
End of test Mon Sep 5 14:28:50 2016
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
Memory Reading Speed Test OpenMP 64 Bit by Roy Longbottom
Start of test Tue Mar 7 23:41:04 2017
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
4 5788 3106 1698 8203 4576 1827 11038 5622 2042
8 6182 3187 1711 9272 4842 1848 11315 5645 2054
16 5631 3197 1639 9320 4850 1753 11223 5520 1813
32 6132 3174 1604 9124 4833 1640 11040 5408 1731
64 5967 3168 1602 8641 4764 1688 9768 5338 1763
128 5469 3173 1572 8682 4408 1727 9054 5358 1811
256 5242 3177 1625 8630 4668 1678 8276 4972 1822
512 3684 3015 1640 7187 4321 1659 6745 5019 1585
1024 2326 2620 1307 4240 3442 1284 1656 1634 1071
2048 3767 2494 1283 4155 3419 1243 1088 1066 989
4096 1996 2628 962 4139 3391 1361 1049 1034 803
8192 854 1627 1304 4122 3352 1595 1010 987 1045
16384 859 2221 1635 3764 1334 1735 865 819 843
32768 1349 1109 1821 1222 1645 1101 912 797 979
65536 3554 533 550 1493 1223 1258 857 874 1600
131072 927 640 737 1097 860 740 891 1272 549
End of test Tue Mar 7 23:41:35 2017
####################### RPi 3 SUSE Not OMP ###########################
Memory Reading Speed Test notOpenMP 64 Bit by Roy Longbottom
Start of test Tue Mar 7 23:40:15 2017
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
4 3991 2484 4123 5232 3381 4123 4521 3674 3672
8 4033 2494 4144 5322 3398 4149 4628 3714 3693
16 4006 2497 4156 5339 3402 4157 4656 3734 3733
32 3487 2331 3711 4570 3102 3710 4615 3600 3628
64 3181 2199 3436 3980 2954 3455 4371 3580 3580
128 3313 2259 3478 3941 2999 3478 4197 3466 3464
256 3418 2263 3502 3966 3011 3507 4244 3493 3489
512 2683 1918 2749 2994 2425 2701 3585 3129 3143
1024 673 1215 1298 1330 1314 1337 1365 1562 1548
2048 729 982 1135 1141 1122 1133 1039 1087 1093
4096 713 1069 1116 1128 1117 1089 968 993 986
8192 704 1074 1111 1125 1119 1110 927 969 960
16384 624 1077 1108 1123 1118 1107 953 958 801
32768 795 1064 1108 1123 1120 1107 962 720 949
65536 1112 1081 1109 1123 1121 921 966 997 1006
131072 908 805 886 1118 1148 1159 959 965 1014
End of test Tue Mar 7 23:40:43 2017
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
OpenMP Not Available
####################### RPi 3 Gentoo Not OMP ###########################
Memory Reading Speed Test notOpenMP 64 Bit by Roy Longbottom
Start of test Wed Mar 8 11:50:40 2017
Memory x[m]=x[m]+s*y[m] Int+ x[m]=x[m]+y[m] x[m]=y[m]
KBytes Dble Sngl Int32 Dble Sngl Int32 Dble Sngl Int32
Used MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S MB/S
4 4059 2496 4143 5250 3396 4140 4545 3689 3692
8 4135 2503 4138 5342 3412 4168 4646 3728 3727
16 4134 2509 4172 5365 3418 4172 4678 3751 3750
32 3563 2327 3668 4399 3082 3671 4443 3611 3616
64 3390 2287 3549 4081 3026 3549 4309 3524 3558
128 3344 2298 3561 4025 3060 3561 4231 3500 3520
256 3337 2276 3496 3951 3040 3495 4243 3508 3510
512 2542 1744 2559 2790 2282 2575 2587 2816 2845
1024 766 1167 1268 1290 1245 1264 1268 1437 1418
2048 765 1054 1118 1126 1107 1106 828 902 897
4096 793 1056 1105 1105 1098 1106 875 903 909
8192 797 1083 1141 1124 1122 1135 782 788 787
16384 913 1098 1164 1147 1140 1163 734 733 740
32768 1137 1105 1175 1156 1150 1166 734 737 741
65536 1137 1106 1176 1157 1151 1176 712 719 718
131072 1135 1087 1180 1155 1155 1175 745 761 761
End of test Wed Mar 8 11:51:08 2017
|
NEON MultiThreading Benchmarks
32 bit versions are in Raspberry_Pi_MP_Benchmarks.zip with details and results in Raspberry Pi Multithreading Benchmarks.htm. The new 64 bit varieties are included in Rpi3-64-Bit-Benchmarks.tar.gz.
There is no NEON compile option, for C code, at 64 bits but, as at 32 bits, programs using NEON intrinsic functions are compiled as different vector instructions.
MP-MFLOPSPiNeon, MP-NeonMFLOPS, MP-NeonMFLOPS64
MP-MFLOPSPiNeon is compiled, at 32 bits, from the same source code as MP-MFLOPS, using NEON compile options. The other two carry out the same calculations using a well ordered structure of NEON intrinsic functions, clearly suitable for SIMD operation. The two 32 bit benchmarks produce similar speeds but slightly different results of numeric calculations, through using different instructions.
64 Bit vs 32 Bit - Average speed improvements, with cached based data, was 60%, with RAM speeds slightly slower.
MP gains - At 64 bits and cached data, throughput increased between 3.0 and 3.97 times, but somehat less at 32 bits.
Comparison with other MP-MFLOPS benchmarks - see Maximum 1 Core MFLOPS above.
The 64 bit NEON intrinsics version produced the best MP performance, at just over 10 GFLOPS, compared with 6.3 GFLOPS at 32 bits.
################## RPi 3 V7A2 Compiled NEON ####################
MP-MFLOPS Compiled NEON v1.0 Mon Aug 15 19:09:46 2016
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 419 782 437 1672 1660 1637
2T 1324 1529 442 3331 3308 3212
4T 1903 1574 439 5040 6073 5738
8T 1613 2204 433 5543 5780 5445
Results x 100000
1T 76406 97075 99969 66008 95367 99951
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
MP-MFLOPS NEON Intrinsics v1.0 Mon Aug 15 19:41:37 2016
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 347 583 427 1706 1703 1657
2T 1080 1157 438 3397 3398 3226
4T 979 1430 437 6265 6128 5464
8T 1218 1351 436 5507 5766 5426
Results x 100000
1T 76406 97075 99969 66014 95363 99951
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-MFLOPS NEON Intrinsics 64 Bit Tue Feb 28 15:37:21 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 729 688 404 2640 2570 2479
2T 1427 1423 348 5142 5119 4646
4T 1433 2729 361 9844 10075 5788
8T 2202 2481 358 9199 10119 5844
Results x 100000
1T 76406 97075 99969 66015 95363 99951
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
MP-MFLOPS NEON Intrinsics 64 Bit Thu Mar 2 17:03:53 2017
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 695 688 386 2595 2577 2423
2T 1373 1242 375 5163 5096 4445
4T 1389 1785 371 10035 10030 6171
8T 2071 2470 339 9410 9481 6209
Results x 100000
1T 76406 97075 99969 66015 95363 99951
|
linpackNeonMP, linpackNeonMP64
The original Linpack benchmark for Raspberry Pi, operates on double precision floating point 100x100 matrices (N = 100). This version uses mainly the same C programming code as the single precision floating point NEON compilation. It is run run on 100x100, 500x500 and 1000x1000 matrices using 0, 1, 2 and 4 separate threads. The 0 thread procedures are identical to those in the single core 100 x 100 NEON compilation, using NEON intrinsic functions. The benchmark was produced to demonstrate that the original Linpack 100x100 code could not be converted (by me) to show increased performance using multiple threads. The official line is that users are allowed to use their own linear equation solver for this purpose.In this case, the 64 bit version tends to be a little faster than the 32 bit program.
Results from the numeric calculations are not the same, due to different instructions being compiled from intrinsic NEON functions.
############################## RPi 3 ##################################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Linpack Single Precision MultiThreaded Benchmark
Using NEON Intrinsics, Mon Aug 15 19:44:30 2016
MFLOPS 0 to 4 Threads, N 100, 500, 1000
Threads None 1 2 4
N 100 538.46 116.24 113.61 113.47
N 500 467.73 335.53 338.61 338.97
N 1000 363.87 336.10 336.72 336.22
NR=norm resid RE=resid MA=machep X0=x[0]-1 XN=x[n-1]-1
N 100 500 1000
NR 2.17 5.42 9.50
RE 5.16722466e-05 6.46698638e-04 2.26586126e-03
MA 1.19209290e-07 1.19209290e-07 1.19209290e-07
X0 -2.38418579e-07 -5.54323196e-05 -1.26898289e-04
XN -5.06639481e-06 -4.70876694e-06 1.41978264e-04
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
Linpack Single Precision MultiThreaded Benchmark
64 Bit NEON Intrinsics, Tue Mar 7 22:30:51 2017
MFLOPS 0 to 4 Threads, N 100, 500, 1000
Threads None 1 2 4
N 100 566.59 130.23 127.00 123.08
N 500 475.35 349.60 346.54 340.43
N 1000 355.27 326.07 324.62 325.75
NR=norm resid RE=resid MA=machep X0=x[0]-1 XN=x[n-1]-1
N 100 500 1000
NR 1.97 5.40 13.51
RE 4.69621336e-05 6.44138840e-04 3.22485110e-03
MA 1.19209290e-07 1.19209290e-07 1.19209290e-07
X0 -1.31130219e-05 5.79357147e-05 -3.08930874e-04
XN -1.30534172e-05 3.51667404e-05 1.90019608e-04
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
Linpack Single Precision MultiThreaded Benchmark
64 Bit NEON Intrinsics, Wed Mar 8 11:36:25 2017
MFLOPS 0 to 4 Threads, N 100, 500, 1000
Threads None 1 2 4
N 100 552.47 112.73 105.19 105.31
N 500 442.32 303.75 303.64 305.03
N 1000 353.88 315.96 309.15 308.31
NR=norm resid RE=resid MA=machep X0=x[0]-1 XN=x[n-1]-1
N 100 500 1000
NR 1.97 5.40 13.51
RE 4.69621336e-05 6.44138840e-04 3.22485110e-03
MA 1.19209290e-07 1.19209290e-07 1.19209290e-07
X0 -1.31130219e-05 5.79357147e-05 -3.08930874e-04
XN -1.30534172e-05 3.51667404e-05 1.90019608e-04
|
Java Benchmarks
Java programs can run via any Operating System, assuming that a compatible Java RunTime Environment (JRE) is available. The JRE translates a general purpose .class file into hardware dependent computer instructions. The .class files are produced using a Java Development Kit (JDK) and these can be run via suitable Operating Systems.
Java programming code can be arranged in two different ways, that is off-line, in this case via a Terminal command (example java myprog), or on-line as an Applet launched by an HTML document. In both cases, the .class files are produced using javac command (example javac myprog.java).
Relating my experiences, the initial Rasbian Operating System had no JREs or JDKs installed. After executing the following, the command java -version indicated Java version ?.6.0_27? Java Applets and off-line files could then be executed but floating point arithmetic was painfully slow.
sudo apt-get update sudo apt-get install icedtea-plugin
It was then discovered that Oracle Java SE 8 Developer Preview for ARM was needed to provide high speed hard float support. This and JRE 7 were installed using Instructions to install Java 8 and 7 (Then the various JREs could be selected using sudo update-alternatives --config java).
Using JRE 8 produced the desired effect with off-line Java but made no difference accessing on-line Applets. This question in Raspberry Pi Forum provided a solution to at least faster floating point. This specifies changes to .cfg files to enable JamVM to be used as an alternative Java Virtual Machine. Further details from a Pi Forum message suggested that Cacao VM would be faster than JamVM on floating point calculations, and this proved to be true. The available version was icedtea-6-jre-cacao, or for JRE 6. It seems that this is run using the command java -cacao program and -jamvm can be used or -zero for the original slow version, but only when JRE 6 is selected.
Using a newly installed Raspbian, the on-line versions only run via the Midori browser. After loading the page, it can take longer than 10 seconds before a benchmark starts running.
As usual the benchmarks and source codes are included in Raspberry_Pi_Benchmarks.zip.
64 Bit Versions - Existing java benchmarks could be run using OpenSUSE, via readily available Java Runtime Environment software, but those for Gentoo would have involved a lot of studying. However, Oracle JDK 1.8 was downloaded for temporary use. This allowed execution of the Java Whetstone Benchmark but not JavaDraw tests. On the other hand, it could compile a 1.8 version, of the latter, that would run using OpenSUSE. The Java benchmarks are available in
Rpi3-64-Bit-Benchmarks.tar.gz.
Java Whetstone Benchmarks
See Comparisons BelowDetails of the Whetstone Benchmark are provided above. Both off-line and on-line versions are provided in the zip file, including source code for off-line and Applet versions, along with the HTML page to run the program. A text log file is produced with the off-line version but a screen copy (scrot -s command, click on browser - needs installing - sudo apt-get install scrot) has to be made for on-line runs, if a record of performance is required. Examples of both are below.
The benchmark .class files were compiled using JDK 1.6 via Linux Ubuntu 10.04, and these run via Windows and Linux. The zip file also includes .class files produced by JDK 7 on the Raspberry Pi. WARNING: this failed to run via Ubuntu using JRE 6 but it does on the Pi that also has JRE 7.
The on-line versions are run by clicking on whetjava2.htm (or right click and select browser) and the off-line varieties using the command “java whetstc?
The on-line version can also be run via
Online Benchmarks.htm.
Whetstone Benchmark Java Version, May 27 2013, 18:09:00
1 Pass
Test Result MFLOPS MOPS millisecs
N1 floating point -1.124750137 49.18 0.3904
N2 floating point -1.131330490 46.54 2.8880
N3 if then else 1.000000000 27.73 3.7320
N4 fixed point 12.000000000 92.48 3.4060
N5 sin,cos etc. 0.499110103 1.08 77.3100
N6 floating point 0.999999821 26.69 20.2100
N7 assignments 3.000000000 39.90 4.6320
N8 exp,sqrt etc. 0.751108646 0.31 119.9300
MWIPS 43.01 232.4984
Operating System Linux, Arch. arm, Version 3.6.11+
Java Vendor Oracle Corporation, Version 1.8.0-ea
|
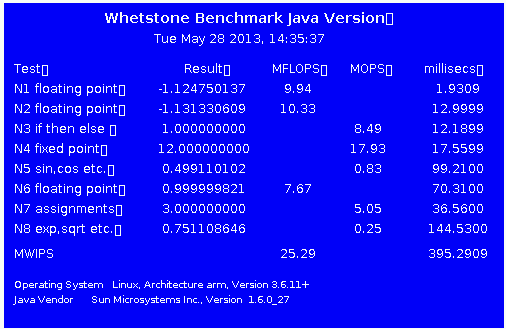
Java Whetstone Comparison
Following are off-line and on-line results, showing the changes in performance through using upgraded JREs and with overclocking (CPU 1000 MHz, Core 500 MHz, SDRAM 600 MHz, 6 volts). There is not much difference in overall MWIPS on using JamVM and the original is faster on the COS/EXP tests, but much slower on the other tests. Similarly, JRE 8 averages about four times faster than JRE 7 with JamVM, if the COS/EXP results are excluded. Later results, using Cacao VM, show that this is much faster than JamVM, again except for the COS/EXP functions.
The off-line versions ran without any problems on the Raspberry Pi 2, other than the EXP test that was particularly slow via JRE 8, reducing the overall MWIPS rating. Other than this, performance via JRE 8 was significantly better than using JRE 6 or JRE 7, as it was on the original RPi. JRE 8 RPi 2 speeds were between 1.5 and 4.3 times faster than RPi 1.
I was unable to persuade Epiphany Browser to use JRE 7 or 8, to run the on-line version. I installed IcedTea 1.6, then Midori Browser to obtain the first results (subject to providing permission to JRE 6). Then, out of the blue, Epiphany ran the benchmark applet, obtaining the same performance as Midori. Results, with the CPU at 1 GHz, were 2.0 to 5.7 times faster than those run on the earlier Raspberry Pi.
Some time was spent attempting to run this benchmark efficiently on a Raspberry Pi 3, but without success in enabling hardware acceleration. This was achieved running the off-line version using Java 1.8 Runtime Environment. Here, average performance was 1.5 times RPi 2, compared with 1.33 times MHz speed. Performance was somewhat different to the Cortex-A53 based tablet.
A result of the C version is also shown, along with another from the Android version. For further details and results see Android Benchmarks and Whetstone Benchmark Java Results.
64 Bit Versions - Performance varied considerably using the different Java implementations. OpenSUSE compared well with an original 32 bit version, with performance ratios, for the different tests, varying between 0.28 and 16.1, average 3.53. The Gentoo was 12% faster than OpenSUSE, on average.
Version JRE MWIPS ------MFLOPS------- -------------MOPS---------------
1 2 3 COS EXP FIXPT IF EQUAL
Off-line
Original 6 18.3 4.4 6.4 3.3 0.99 0.30 7.9 2.9 2.5
JamVM 6 23.4 9.4 10.0 8.9 0.69 0.23 17.8 8.1 5.4
Cacao 6 32.7 25.5 36.7 25.7 0.76 0.24 55.2 28.9 25.8
Original 7 18.7 4.3 6.2 3.5 0.98 0.30 7.9 2.9 2.6
JamVM 7 25.7 12.3 11.7 9.7 0.74 0.24 23.6 10.9 6.2
Original 8 47.8 49.4 47.8 26.7 1.19 0.36 93.3 27.8 40.0
1000 MHz 8 75.1 71.4 69.2 39.8 2.10 0.53 134.9 40.3 57.8
Raspberry Pi 2
Original 6 101.8 30.3 43.6 20.2 2.89 1.98 60.7 38.2 15.0
Original 7 100.8 30.4 43.6 19.9 2.84 1.99 60.8 38.3 14.8
Original 8 117.4 118.8 125.3 62.2 3.89 0.74 278.8 60.8 224.8
javac 1.7 7 100.6 30.4 43.6 19.9 2.83 1.99 60.8 38.3 14.8
javac 1.7 8 116.9 119.5 125.1 62.2 3.91 0.73 278.5 60.8 223.0
javac 1.8 8 116.8 119.5 125.0 62.2 3.81 0.74 278.3 60.8 224.8
1000 MHz 1.7 8 128.6 133.0 139.4 69.3 4.19 0.81 310.3 67.7 249.7
Raspberry Pi 3
javac 1.7 # 7 83.6 25.3 25.8 21.5 4.55 0.94 42.0 18.6 10.4
javac 1.7 8 183.0 183.8 178.0 91.1 6.02 1.18 461.1 88.4 276.7
javac 1.8 8 183.4 184.1 179.6 91.1 5.94 1.19 460.5 88.6 276.6
# no hardware acceleration
########################## RPi 3 SUSE 64 Bit ###########################
javac 1.7 7 521.8 269.4 247.3 114.2 12.33 10.04 599.5 191.7 80.0
javac 1.7 8 692.7 273.8 254.5 114.2 21.88 19.01 620.3 211.7 78.2
######################### RPi 3 Gentoo 64 Bit ##########################
javac 1.7 8 783.0 335.4 296.3 207.0 18.95 18.09 667.1 160.8 88.3
###############################################################################
On-line
JamVM 6 25.3 9.9 10.3 7.7 0.63 0.25 17.9 8.5 5.1
1000 MHz 6 39.0 14.1 13.7 11.2 1.30 0.40 25.4 12.2 7.2
Raspberry Pi 2
900 MHz 6 101.8 40.8 42.8 26.5 2.90 2.01 65.9 51.4 12.4
1000 MHz 6 120.4 45.7 47.9 28.5 3.20 2.27 73.8 57.7 14.1
Raspberry Pi 3
Similar to javac 1.7 # no hardware acceleration
###############################################################################
Other
MHz
C Version 700 270.5 97.8 100.8 85.7 5.90 2.70 425.3 698.6 499.0
C RPi 2 900 525.0 252.0 261.3 223.0 10.20 5.10 1102.5 1358.4 882.0
C RPi 3 1200 724.5 331.0 347.5 298.1 12.1 8.70 1520.4 1873.4 1216.3
Android Native C
v8-A53 1300 834.7 348.9 312.7 310.9 36.7 5.40 1556.7 1867.2 570.5
v7-A9 1200 731.1 273.6 253.0 252.8 28.0 5.00 1185.2 2383.4 1192.1
Android Java
v8-A53 1300 391.3 86.0 155.7 66.8 12.3 8.60 277.8 89.8 61.4
v7-A9 1000 286.7 53.7 84.7 46.7 14.5 5.40 183.0 69.7 33.2
|
JavaDraw Benchmark
See Comparisons BelowJavaDraw is intended to run the same test functions as my JavaDraw.apk benchmark for Android devices, where details and results can be found in Android Graphics Benchmarks.htm. The benchmark uses small to rather excessive simple objects to measure drawing performance in Frames Per Second (FPS). Five tests draw on a background of continuously changing colour shades. For further details and results see JavaDraw.htm, where links to on-line versions are also provided. However, some displays from these can be erratic and tearing.
- Test 1 loads two PNG files, one bitmap moving left/right for each frame, the other circling. This is repeated twice, in this version, as the long start up time leads to slow speeds being reported.
- Plus Test 2 for JavaDraw.apk generates 2 SweepGradient multi-coloured circles moving towards the centre and back. The circles are loaded a PNG file for this version.
- Plus Test 3 draws 200 random small circles in the middle of the screen.
- Plus Test 4 draws 80 lines from the centre of each side to the opposite side, again with changing colours.
- Plus Test 5 draws the same small random circles as Test 3 but with 4000, filling the screen.
- Each test runs for approximately 10 seconds at window size 1280 x 720 pixels.
- Two versions are available, JavaDrawPC, compiled using JDK 6 via Linux Ubuntu, and JavaDrawPi produced on the Pi using JDK 7. Both can be run via Windows and Linux, subject to tha appropriate JRE being available. Commands to use are “java JavaDrawPC?and “java JavaDrawPi?
Measured speeds are displayed in the Terminal window and in JavaDraw.txt log file. An example is shown below, preceded by the display during Test 4. The benchmark identifies the Operating System and JRE used.
Java Drawing Benchmark, May 30 2013, 12:40:39
Produced by javac 1.7.0_02
Test Frames FPS
Display PNG Bitmap Twice Pass 1 24 2.39
Display PNG Bitmap Twice Pass 2 118 11.72
Plus 2 SweepGradient Circles 116 11.56
Plus 200 Random Small Circles 95 9.48
Plus 320 Long Lines 56 5.60
Plus 4000 Random Small Circles 20 1.92
Total Elapsed Time 60.8 seconds
Operating System Linux, Arch. arm, Version 3.6.11+
Java Vendor Oracle Corporation, Version 1.7.0_07
|
JavaDraw Comparison - Frames Per Second
Following are Raspberry Pi results at normal and overclocked settings, using JRE 6, 7 and 8. Basic JRE 6 and with JamVM produced similar results with Cacao VM being slightly faster. A surprise was that JRE 8 speeds were much slower (early release - see later results below). JavaDrawPC (from JDK 6) and JavaDrawPi (from Pi JDK 7) also produced similar performance, via JRE 7.
Raspberry Pi 2 results provided an average speed gain of 4.2 times for JRE 7, the CPU running at 1000 MHz, with JRE 8 performance being even better. As the original tests, on the older RPi, indicated extremely slow performance using JRE 8, the software was updated to a new version, and the benchmark rerun. Further tests were carried out, a second one restricted to using one CPU core, whilst running vmstat performance monitor at the same time - See Details and results below. These confirm that JavaDraw can use more than one core to improve performance.
Raspberry Pi 3 had the latest (May 2016) version of Raspbian installed, along with the new OpenGL GLUT experimental driver. As shown below, performance, using JRE 8, was too slow. The previous Operating System was loaded, and that produced average speeds 50% faster than the Raspberry Pi 2. Back to the newer OS, the GLUT driver was disabled, enabling the faster performance, but somewhat slower with JRE 7 selected.
Android results on a Nexus 7 are also shown and these are matched by the Pi at 1 GHz. The final much faster results are for running the same tests via Linux on an Atom and Core 2 based PCs. The screen shot above was from a PC the a quad core 3 GHz Phenom CPU under Windows, where CPU utilisation was around 57%, indicating that more that two cores were fully utilised.
64 Bit Versions - Even more variations were demonstrated, where one OpenSUSE download consistently produced different results to another. Then, maximum FPS speeds were significantly slower than those on a Raspberry Pi 2 and best case using Raspberry Pi 3 at 32 bits.
PNG PNG +Sweep +200 +320 +4000
Bitmaps Bitmaps Gradient Small Long Small
JRE 1 2 Circles Circles Lines Circles
Pi 700 MHz 6 3.6 12.0 11.9 9.5 5.5 1.8
Pi 700 MHz 6 Cac 0.2 13.6 14.7 12.4 7.2 2.8
Pi 700 MHz 7 2.4 11.7 11.6 9.5 5.6 1.9
Pi 700 MHz 8 0.4 2.7 2.6 1.9 0.8 0.4
Pi 1000 MHz 6 10.1 19.5 19.3 15.9 9.4 3.1
Pi 1000 MHz 6 Cac 8.3 23.1 21.9 18.2 11.0 4.2
Pi 1000 MHz 7 11.1 19.2 18.7 16.2 9.5 3.1
Pi 1000 MHz 8 2.0 4.3 4.2 3.0 1.3 0.6
Later Java
Pi 700 MHz 7 0.3 10.9 10.8 8.2 5.0 1.3
Pi 700 MHz 8 0.2 7.2 10.7 11.7 7.7 5.1
Raspberry Pi 2
Pi 2 900 MHz 6 43.1 54.3 54.2 48.4 31.8 18.4
Pi 2 900 MHz 7 40.8 52.5 51.9 46.9 30.5 17.1
Pi 2 900 MHz 8 44.4 56.8 57.3 55.0 38.6 25.2
1 CPU 900 MHz 8 22.1 35.8 35.4 36.0 38.3 22.4
Pi 2 1000 MHz 6 51.4 65.7 64.5 57.5 37.4 20.3
Pi 2 1000 MHz 7 51.5 63.7 62.8 56.4 36.9 20.1
Pi 2 1000 MHz 8 55.0 69.5 70.0 67.7 46.4 29.5
Raspberry Pi 3
Pi 3 1200 MHz 7@ 2.9 3.2 7.3 8.1 7.5 7.0
Pi 3 1200 MHz 8@ 2.9 3.1 7.3 8.1 7.6 7.0
Pi 3 1200 MHz 7+ 71.8 78.9 84.0 73.1 47.7 23.2
Pi 3 1200 MHz 8+ 81.1 96.9 96.9 88.7 62.8 43.3
Pi 3 1200 MHz 8- 81.0 97.2 96.7 92.1 61.9 42.1
@ Later Raspbian with the new OpenGL GLUT driver
+ Driver installed but not enabled
- Older Raspbian without GLUT driver
Raspberry Pi 3 64 Bit OpenSUSE
Pi 3A 1.7 > 1.8.0_111 8.6 10.9 10.7 10.1 7.9 3.6
Pi 3B 1.7 > 1.8.0_121 22.8 32.1 32.3 27.7 15.3 6.2
A and B different OpenSUSE downloads
Raspberry Pi 3 64 Bit Gentoo - Not available
Other
ARM A53 1300 MHz 55.7 36.7 28.5 17.8 5.0
ARM A9 1300 MHz 20.4 16.5 14.5 11.3 3.8
Atom 1666 MHz 57.3 83.2 80.1 74.8 53.6 24.5
Core 2 2400 MHz 271.5 360.6 227.7 237.6 205.2 142.5
Cac = Cacao VM
|
OpenGL ES Benchmark - OpenGL1Pi.bin
See Comparisons BelowThis benchmark is essentially the same as JavaOpenGL1 described in Android Graphics Benchmarks.htm. This has four tests that draw a background of 50 cubes first as wireframes then colour shaded. The third test views the cubes in and out of a tunnel with slotted sides and roof, also containing rotating plates. The last test adds textures to the cubes and plates. The 50 cubes are redrawn 15, 30 and 60 times, with randomised positions, colours and rotational settings. With 6 x 2 triangles per cube, minimum triangles per frame for the three sets of tests are 9000, 18000 and 36000.
Speed is measured in Frames Per second (FPS). With Android, maximum FPS is 60, limited by the imposition of wait for vertical blank (VSYNC). So, there is not much point in using lighter loading. As VSYNC appears not to be forced under Raspbian, additional tests using five cubes (x15 repeats) are included.

The commands to compile the OpenGL ES program were extracted from sample program hello_pi makefile.
Nominal duration of each test is 10 seconds. Actual elapsed times and FPS scores are displayed on the LXTerminal display as the tests progress. On completion, results are saved in a text log file. See example below, along with compile and execute commands, the latter having parameters that define the window size to use. As usual, the benchmark, source code and image files used are available in Raspberry_Pi_Benchmarks.zip.
Of particular note, CPU utilisation, shown in Task Manager, is less than 50% for the most stressful test. The run time parameters were changed to allow the benchmark to run for a specified time- see Reliability Tests. This still runs 16 tests but each generates 36000 textured triangles.
June 2015 - Version 1.2 produced. The original version was found to be counting frames twice, doubling FPS speed results. This is not important when comparing performance at different system settings or with Raspberry Pi 2. The revised program has the correct frame count. The results suggest that displays are synchronised to run at a maximum of 50 FPS, using the UK standard frequency of 50 Hz, as the VSYNC setting.
Compile Commands Use the two cc extremely long (>512 charas) compile
commands and the cc link command in comments
at the start of OpenGL1Pi.c
Make files These are now included in the zip file. A make
comaand executes Makefile that uses Makefile.include to
comopile and link the benchmark programs.
Run Commands ./OpenGL1Pi.bin Wide pppp, High pppp RunTime mm
pppp = pixels, mm - minutes for reliability test
Default ./OpenGL1Pi.bin - 1280 x 720, 16 x 10 second tests
parameter names just first letter used upper or lower case
pppp any size e.g. W 1920, H 1080 - W 120, H 60 - W 60, H 120
Example OpenGLPi.txt Log File
Raspberry Pi OpenGL ES Benchmark 1.2, Mon Jun 8 11:22:12 2015
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
900+ 50.05 50.01 43.50 39.30
9000+ 20.20 20.06 15.06 11.60
18000+ 10.27 10.19 8.72 6.41
36000+ 5.15 5.13 4.74 3.43
Screen Pixels 1280 Wide 720 High
End Time Mon Jun 8 11:24:54 2015
|
OpenGL ES Comparison - Frames Per Second
The following results show that maximum overclocking, larger window sizes and smaller ones do not produce significant variations in performance.
Raspberry Pi 2 - The benchmarks were run on RPi 2 and resultant speeds are little different. Measured CPU utilisation was typically 6% or 24% of one CPU core. Recompilation with Cortex A7 parameters made no difference. Details are below.
Raspberry Pi 3 The benchmark would not run with the new OpenGL GLUT driver installed and enabled, but did with it disabled. Then, as shown below, performance was similar to that from the Raspberry Pi 2.
Lastly, some Android JavaOpenGL1 results are shown for comparison purposes.
############ Original Raspberry Pi #############
RPi 700 MHz, Screen Pixels 1280 x 720
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
900+ 50.05 50.01 43.50 39.30
9000+ 20.20 20.06 15.06 11.60
18000+ 10.27 10.19 8.72 6.41
36000+ 5.15 5.13 4.74 3.43
RPi 1000 MHz, Screen Pixels 1280 x 720
900+ 50.07 50.01 43.82 39.58
9000+ 20.20 20.18 15.13 11.64
18000+ 10.25 10.25 8.76 6.42
36000+ 5.15 5.16 4.76 3.44
RPi 700 MHz, Screen Pixels 1920 x 1080
900+ 50.05 50.01 43.50 39.30
9000+ 20.20 20.06 15.06 11.60
18000+ 10.27 10.19 8.72 6.41
36000+ 5.15 5.13 4.74 3.43
RPi 700 MHz, Screen Pixels 320 x 180
900+ 50.11 50.01 44.90 41.80
9000+ 20.60 20.49 15.33 12.79
18000+ 10.41 10.35 8.85 7.21
36000+ 5.23 5.20 4.79 3.87
################ Raspberry Pi 2 #################
RPi 2 900 MHz, Screen Pixels 1280 x 720
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
900+ 50.07 50.00 44.76 41.10
9000+ 20.38 20.61 15.36 12.24
18000+ 10.37 10.42 8.90 6.89
36000+ 5.21 5.23 4.82 3.72
RPi 2 900 MHz, Screen Pixels 1920 x 1080
900+ 50.07 50.00 43.32 38.94
9000+ 19.63 19.75 14.85 11.69
18000+ 10.15 10.03 8.60 6.02
36000+ 4.99 5.06 4.66 3.07
################ Raspberry Pi 3 #################
OpenGL GLUT driver disabled
RPi 3 1200 MHz, Screen Pixels 1280 x 720
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
900+ 60.02 60.00 43.48 40.03
9000+ 20.30 20.13 15.03 12.15
18000+ 10.29 10.19 8.71 6.83
36000+ 5.17 5.13 4.72 3.67
RPi 3 1200 MHz, Screen Pixels 1920 x 1080
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
900+ 59.99 60.00 41.45 37.88
9000+ 19.38 19.17 14.42 11.59
18000+ 9.84 9.75 8.34 6.49
36000+ 4.91 4.90 4.52 3.30
##################### Other #####################
Excludes Tests With 900+ Triangles
1.3 GHz quad core 64 bit MediaTek ARM Cortex-A53
Android 5.0, GPU Mali T720 MP2
Screen Pixels 800 Wide 1216 High
Android Java OpenGL Benchmark 26-Aug-2015 16.24
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
9000+ 22.55 22.11 16.67 14.27
18000+ 11.55 11.60 9.98 8.27
36000+ 5.92 5.98 5.48 4.48
Andoid JavaOpenGL1 Galaxy SIII, Quad Cortex-A9
1.4 GHz, Android 4.0.4, ARM Mali-400 MP4 quad
core graphics. Screen Pixels 1280 x 720
--------- Frames Per Second --------
Triangles WireFrame Shaded Shaded+ Textured
9000+ 57.98 59.62 51.93 41.19
18000+ 34.46 34.28 29.61 15.25
36000+ 14.45 13.11 13.03 7.34
Andoid JavaOpenGL1 Nexus 7 Quad 1300 MHz Cortex-A9,
Android 4.1.2, nVidia ULP GeForce Graphics 12 core,
416 MHz. Screen Pixels 1280 x 736
9000+ 42.18 43.57 33.38 23.54
18000+ 23.68 23.47 19.91 13.38
36000+ 12.05 11.95 11.00 7.10
|
OpenGL GLUT Benchmark - videogl32, videogl64
See Comparisons BelowIn 2011, I produced a Linux version of my 2004 Windows VideoGL1 benchmark. Its pedigree was established in 2012, when I approved a request from a Quality Engineer at Canonical, to use this OpenGL benchmark in the testing framework of the Unity desktop software. One reason probably was that it can be run for extended periods as a stress test. Further details and Linux results are in Linux OpenGL Benchmarks.htm.
The OpenGL version required minimum conversion, with OpenGL code functions unchanged. The benchmark, source code and image files are included in the OpenGL folder in Raspberry_Pi_Benchmarks.zip, also separately in Raspberry_Pi_OpenGL_Benchmark.zip,
The benchmarks measure graphics speed in terms of Frames Per Second (FPS) via six simple and more complex tests. The first four tests portray moving up and down a tunnel including various independently moving objects, with and without texturing. The last two tests, represent a real application for designing kitchens. The first is in wireframe format, drawn with 23,000 straight lines. The second has colours and textures applied to the surfaces. The textures are obtained from 24 bit BMP files that can be up 256 x 256 pixels at 192 KB, with those supplied being 64 x 64 pixels at 12 KB.
After booting Raspbian-jessie on a Raspberry Pi 2, freeglut software was installed via:
sudo apt-get update sudo apt-get install freeglut3 sudo apt-get install freeglut3-dev
The command raspi-config had to be run, the function updated and the experimental GL driver enabled via Advanced Options.
The benchmark was coppiled and linked by the following Terminal command:
gcc ogl1.c cpuidc.c -lrt -lm -O3 -lglut -lGLU -lGL -o videogl32
The default benchmark runs all tests, each for 5 seconds, at the current display size settings, with an output header (configuration details and main headings), one line of results and end messages (date and time). Other parameters are pixel dimensions W or Width and H or Height. Initial results, in the next section, were produced via the following script (runit included in zip file), to provide a single table with minimum additional data. The export command is a later addition to turn off Wait For Vertical Blank (or VSYNC), to demonstrate maximum speeds.
export vblank_mode=0 ./videogl32 Width 320, Height 240, NoEnd ./videogl32 Width 640, Height 480, NoHeading, NoEnd ./videogl32 Width 1024, Height 768, NoHeading, NoEnd ./videogl32 NoHeading
Stress test results, running videogl32 and CPU tests, are included in the stress test report. See: Livermore Loops and Maximum MFLOPS benchmarks.
64 Bit Version - The later compilations for 64 bit operation are available in
Rpi3-64-Bit-Benchmarks.tar.gz.
This also includes the source code and script file to run the benchmark at different window sizes. The program can also be used as a stress test, as indicated above.
In order to compile and run, FreeGLUT library (or equivalent) has to be installed. This did not work on some OpenSUSE Leap 42.2 distributions.
OpenGL GLUT Benchmark Comparisons
The first set of results demonstrated extremely slow speeds. Then, via sudo raspi-config I enabled the experimental desktop GL driver, to produce the much improved second set of results. These appear to be limited to a maximum of 50 Frames Per Second, assumed to be due to Wait For Vertical Blank (VSYNC) being active. Googling indicated that an export vblank_mode=0 command was needed. So this was added to the script file to produce the third report.
The fourth table loaded 192 KB BMP texture files instead of the default ones at 12 KB. These could reduce displayed speed by up to three times.
The fifth sores are with the system overclocked from 900 to 1000 MHz (1.11 times). Average improvements in FPS speeds were 1.13 times, with small window plain colour tests appearing to be up to 25% faster, these probably being more dependent on graphics speed.
Raspberry Pi 3 - results below show that this was 47% to 76% faster than the non-overclocked Raspberry Pi 2 at the smallest window size. At full screen, 1920 x 1080 pixels, performance was similar using plain colours, then up to 81% faster with the more complex displays.
64 Bit Version - Results below include some from 64 bit versions of OpenSUSE and Gentoo, plus comparisons of the latter and the 32 bit Raspbian based version. At the smaller window sizes, and simple objects, the Raspbian results were faster, but the opposite was apparent on running the more complex kitchen displays. Performance became more equal at increasing window sizes. OpenSUSE speeds were slower than those using Gentoo, particularly with simple objects and all tests at window size 1920 x 1080 pixels.
First results
######################## Raspberry Pi 2 ########################
GLUT OpenGL Benchmark 32 Bit Version 1, Mon Apr 18 10:01:21 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 9.5 5.4 7.1 3.7 1.5 1.1
640 480 3.5 2.9 2.8 1.9 1.3 0.7
1024 768 1.5 1.3 1.3 1.3 1.0 0.4
1824 984 0.7 0.6 0.6 0.5 0.7 0.2
End at Mon Apr 18 10:04:58 2016
After enabling the experimental desktop GL driver
######################## Raspberry Pi 2 ########################
GLUT OpenGL Benchmark 32 Bit Version 1, Mon Apr 18 10:18:33 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 49.4 49.4 39.9 24.9 10.0 7.1
640 480 50.0 49.4 30.1 23.8 10.0 7.1
1024 768 47.2 45.4 24.7 23.3 10.0 7.0
1920 1080 18.5 18.2 16.5 15.5 9.8 7.0
End at Mon Apr 18 10:20:48 2016
After disabling VSYNC
######################## Raspberry Pi 2 ########################
GLUT OpenGL Benchmark 32 Bit Version 1, Tue Apr 19 09:02:30 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 210.3 114.4 52.6 32.5 12.1 7.8
640 480 115.0 89.5 48.5 30.6 11.9 7.7
1024 768 47.9 46.7 37.5 28.3 11.6 7.6
1920 1080 20.6 18.6 16.8 15.9 11.4 7.4
End at Tue Apr 19 09:04:45 2016
Larger texture files - 192 KB instaed of 12 KB
######################## Raspberry Pi 2 ########################
GLUT OpenGL Benchmark 32 Bit Version 1, Tue Apr 19 13:30:49 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 213.4 110.6 39.5 12.4 11.7 2.6
640 480 111.1 84.1 34.0 12.1 11.9 2.5
1024 768 49.1 47.0 27.7 11.0 11.7 2.4
1920 1080 20.2 17.3 15.7 9.3 11.5 2.2
End at Tue Apr 19 13:33:07 2016
Default Textures, Overclocked CPU at 1000 MHz (1.11 time faster)
######################## Raspberry Pi 2 ########################
GLUT OpenGL Benchmark 32 Bit Version 1, Thu Apr 21 15:41:04 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 266.7 138.7 60.4 36.9 13.5 8.7
640 480 126.7 103.8 56.4 35.8 13.5 8.8
1024 768 55.3 51.1 41.4 32.3 13.1 8.5
1920 1080 21.6 20.7 18.0 17.2 12.8 8.5
Average Gain 1.14 1.14 1.12 1.13 1.13 1.13
Raspberry Pi 3 1200 MHz Default Textures
######################## Raspberry Pi 3 ########################
GLUT OpenGL Benchmark 32 Bit Version 1, Wed Jul 27 20:31:52 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 308.4 182.1 82.6 52.3 21.6 13.7
640 480 129.5 119.6 74.6 49.2 21.6 13.8
1024 768 54.8 52.2 43.7 39.2 21.4 13.6
1920 1080 21.5 17.9 20.3 19.6 20.6 13.4
End at Wed Jul 27 20:34:06 2016
Comparison With Raspberry Pi 2 At Sefault 900 MHz
320 240 1.47 1.59 1.57 1.61 1.79 1.76
1920 1080 1.04 0.96 1.21 1.23 1.81 1.81
Larger texture files - 192 KB instaed of 12 KB
GLUT OpenGL Benchmark 32 Bit Version 1, Wed Jul 27 20:42:04 2016
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 312.2 178.0 61.0 20.1 21.1 4.2
640 480 129.8 119.5 47.8 18.3 21.3 4.1
1024 768 54.8 52.9 37.3 17.0 21.6 3.9
1920 1080 21.9 18.5 18.0 14.0 20.6 3.6
End at Wed Jul 27 20:44:19 2016
############################# RPi 3 SUSE ##############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
GLUT OpenGL Benchmark 64 Bit Version 1, Sat Mar 18 19:03:25 2017
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
160 120 87.1 76.3 64.3 46.9 24.3 15.6
320 240 59.2 54.7 53.7 43.9 25.6 15.6
640 480 33.4 31.7 31.0 27.6 24.4 15.3
1024 768 17.5 17.5 17.7 17.0 16.2 14.1
1920 1080 8.2 8.3 9.0 9.3 8.4 7.6
End at Sat Mar 18 19:06:16 2017
############################ RPi 3 Gentoo #############################
Raspberry Pi 3 CPU 1200 MHz, SDRAM 900 MHz
Compiled for 64 bit ARM v8a
GLUT OpenGL Benchmark 64 Bit Version 1, Sat Mar 18 18:21:44 2017
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
160 120 184.3 127.5 72.7 48.4 26.8 16.6
320 240 161.8 116.0 67.1 46.3 26.7 16.7
640 480 76.8 74.8 49.8 41.4 25.9 16.3
1024 768 35.7 34.8 29.7 26.7 25.0 15.7
1920 1080 18.0 18.7 16.4 15.8 17.1 13.1
End at Sat Mar 18 18:24:35 2017
64 Bit / 32 FPS Bit Speed Comparisons
320 240 0.52 0.64 0.81 0.89 1.24 1.22
1024 768 0.65 0.67 0.68 0.68 1.17 1.15
1920 1080 0.84 1.04 0.81 0.81 0.83 0.98
|
DriveSpeed Benchmark
The main execution C code in version 1.0 was the same as the Android version. However, as some of the results were vastly different to a version produced for Linux, the program was revised. The execution and source code are again in Raspberry_Pi_Benchmarks.zip. The benchmark is provided to measure speeds of the main SD card drive and USB attached storage devices. In my case, a mini USB hub was used that has multiple ports and card reading slots. An example of results, displayed and saved in driveSpeed.txt log file, are shown below. Tests carried out and changes made are:
Test 1 - Write and read three 8 and 16 MB; Results given in MBytes/second
Test 2 - Write 8 MB, read can be cached in RAM; Results given in MBytes/second
Test 3 - Random write and read 1 KB from 4 to 16 MB; Results are Average time in milliseconds.
The original version appeared to enable caching on reading.
Test 4 - Write and read 200 files 4 KB to 16 KB; Results in MB/sec, msecs/file and delete seconds.
Version 1.0 included an extra “safe to remove?flush that increased file writing times.
Below is a log file for the benchmark running on the SD card. Raspberry Pi 2 speeds were little different (See Comparisons), except for the caching test where, results below demonstrate RPi 2 faster RAM speed.
64 Bit Versions - See
Drive and LAN Benchmarks.
#####################################################
DriveSpeed RasPi 1.1 Mon Dec 16 16:20:35 2013
Current Directory Path: /home/pi/benchmarks/DriveSpeed
Total MB 14894, Free MB 12338, Used MB 2556
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 8.33 8.82 6.87 22.46 22.74 22.74
16 14.45 14.07 19.45 22.66 22.78 22.76
Cached
8 45.95 49.94 58.35 156.96 156.18 155.54
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.711 0.709 0.757 3.34 2.97 6.67
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 1.49 2.54 3.72 5.35 8.65 11.91
ms/file 2.75 3.23 4.41 0.77 0.95 1.38 0.086
End of test Mon Dec 16 16:21:06 2013
#####################################################
Raspberry Pi 2
DriveSpeed RasPi 1.1 Sun Mar 1 10:43:41 2015
Current Directory Path: /home/pi/benchmarks/drivespd
Total MB 6266, Free MB 3444, Used MB 2822
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
Cached
8 101.13 118.31 143.66 487.11 495.06 481.95
|
As usual, the tests are run from an LX Terminal command (./DriveSpeed), pointing to the directory containing the benchmark. As shown above, there are also run time parameters for starting file size (example for 16 and 32 MB) and path for the data. The latter is particularly important for measuring speeds via USB connections. Format options for the run command to use a different path for data and file size is
Mounted USB devices can be identified by executing a df command, with my results shown below (/dev) for a USB Flash drive and a USB powered disk drive with two partitions, the first for a FAT formatted area and the second (long number) for a Linux bootable Ext4 section. The benchmark can be executed, as shown below, using the displayed path. Sometimes, a sudo command might be needed. The benchmark can also be saved on the USB drive and run from there.
At least my system appears to crash sometimes, on changing the USB drive, even after executing an unmount command (see below). A better option appeared to be via the Places tab on File Manager.
Step 1 display paths pi@raspberrypi ~ $ df Filesystem Size Used Avail Use% Mounted on rootfs 15G 2.0G 12G 14% / /dev/root 15G 2.0G 12G 14% / devtmpfs 180M 0 180M 0% /dev tmpfs 38M 300K 38M 1% /run tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 75M 0 75M 0% /run/shm /dev/mmcblk0p1 56M 19M 38M 34% /boot /dev/sdc1 1.9G 222M 1.7G 12% /media/USB2 (USB2 = volume name) /dev/sda1 56M 19M 38M 34% /media/C522-EA52 /dev/sda2 7.3G 1.7G 5.4G 24% /media/62ba9ec9-47d9-4421-aaee-71dd6c0f3707 Execute Examples pi@raspberrypi ~/testdir $ ./DriveSpeed FilePath /media/USB2 pi@raspberrypi ~/testdir $ sudo ./DriveSpeed FilePath /media/that-long-path Benchmark On USB Drive Examples pi@raspberrypi ~ $ /media/path/DriveSpeed pi@raspberrypi /media/path $ ./DriveSpeed Possibility Permissions need setting pi@raspberrypi /media/bmarkhere $ sudo chmod 0777 DriveSpeed Unmount pi@raspberrypi ~/testdir $ sudo umount /media/path |
DriveSpeed Comparison
Following are example results, but note that there can be considerable variations from different test runs. The first two of the SD cards have a Class 4 specification, where the number represents minimum speed for recording a video, in MBytes/second. SD 3 has a Class 10 rating but can be the slowest. SD 4 is a SanDisk Extreme Pro microSDHC UHS-1 Class 10 card, rated at up to 633X or 95 MB/second. This clearly has the fastest card writing speeds but, as for most reading speeds, is limited by bus clock frequency. CPU utilisation was less than 10% during writing and reading the large files. All SD cards are as Ext4 formatted as system drives. Rpi booting times are also shown, where SD 3 is again the slowest, maybe relative to random reading times.
Next are a series of USB Flash memory sticks with FAT formatting. St1 is a SanDisk Cruzer with maximum writing speed rated at 10 MB/s and has an 8 KB sector size. For reference, St2 is an old drive. Patriot Rage XT St3 write/read ratings are 25/27 MB/s with 4 KB sectors. St5 is a high speed SanDisk Extreme USB 3.0 drive, with write/read ratings of 110/190 MB/s and 16 KB sectors. St4 and St6 are the last two with Ext4 format. The main observations are that the faster drive provides little advantage on reading performance, limited by bus speed and other overheads, but produces the fastest writing speeds, with significant gains using Ext4 format over that using FAT.
The disk drive (USB2 HD) results probably reflect bus and RPi overheads, with similar performance to the fastest USB stick on large file tests, including gains from the improved formatting. This is not the case on random access and small files, particularly on writing and more so using FAT format.
The last results are on a Linux based PC with a 2.4 GHz CPU and USB2 sockets. Source code, identical that used for RPi, was compiled for the tests. The first is for a SATA based disk drive, with its superior performance, particularly on large files. Then there are results for USB sticks St1, St5 and St6, indicating faster hardware speeds and lower overheads, particularly on writing and reading large files. Then FAT formatting lead to worst performance writing small files.
Raspberry Pi 2 speeds are provided for the main SD card and USB sticks St5 FAT and St6 Ext4. also the fast micro SD 4 card via two different readers. The latter produced faster USB 2 speeds, on large files, using a USB 3 card reader. With other devices, performance could be somewhat better or worse than that via the original Raspberry Pi.
MB/second 16 MB files Boot
Large Write1 Write2 Write3 Read1 Read2 Read3 Secomds
SD Main 16 GB 11.5 10.3 11.5 22.7 22.7 22.8 36
SD 2 4 GB 8.0 9.4 8.2 20.2 20.2 20.2 37
SD 3 8 GB 3.8 6.7 4.6 18.3 18.4 18.2 59
SD 4 16 GB 19.6 19.8 19.9 22.6 22.2 22.8 37
USB2 St1 16 GB FAT 3.8 4.0 3.8 24.3 24.7 24.1
USB2 St2 2 GB old 3.9 3.9 3.9 14.4 14.6 14.6
USB2 St3 8 GB FAT 9.1 9.2 9.3 25.6 25.5 24.6
USB2 St4 8 GB Ext4 11.8 11.7 10.8 25.6 25.3 25.3
USB3 St5 32 GB FAT 17.2 17.3 16.2 25.9 26.1 26.0 [2]
USB3 St6 32 GB Ext4 26.1 26.4 26.4 26.5 26.2 26.2 [2]
USB3 St7 32 GB F2fs 22.0 22.0 22.3 24.9 25.4 25.8 [2]
USB2 HD FAT 17.0 16.0 16.0 24.0 25.6 25.7
USB2 HD Ext4 24.8 23.8 24.7 22.5 23.4 21.1
Raspberry Pi 2 Boot
Seconds
SD Main 8 GB 12.6 12.5 12.6 19.5 19.2 19.5 33
SD 4A 16 GB 29.8 28.6 29.6 30.1 29.4 28.9
SD 4B 16 GB 15.6 15.7 15.7 19.2 19.3 19.4
USB3 St5 32 GB FAT 9.2 7.8 11.6 29.1 29.0 29.3
USB3 St6 32 GB Ext4 19.0 19.2 26.3 24.1 30.3 30.3
Raspberry Pi 3 Boot
Seconds
SD Main 16 GB 8.7 7.3 11.0 16.9 22.9 23.1 17
USB2 8 GB FAT 10.6 4.8 3.7 35.0 35.6 34.8
Linux
Main HD PC Ext4 68.4 52.0 77.0 77.7 69.7 70.0
USB2 St1 Linux FAT 4.3 3.4 4.0 26.7 26.1 25.8
USB3 St5 Linux FAT 28.1 28.5 27.5 39.0 39.3 39.3 [1]
USB3 St6 Linux Ext4 29.5 29.6 29.6 39.1 39.3 39.3 [1]
USB3 St7 Linux F2fs 29.6 30.0 29.6 39.6 39.7 39.4 [1]
Random milliseconds
Read Write
From MB 4 8 16 4 8 16
SD Main Kingston 0.568 0.538 0.535 4.6 5.0 5.2
SD 2 PNY 0.821 0.775 0.997 11.1 26.6 28.9
SD 3 Verbatim 0.995 1.076 1.144 8.5 113.8 70.3
SD 4 SanDisk EP 0.748 0.735 0.696 2.6 4.4 2.4
USB2 St1 San Cruzer 0.806 0.799 0.791 20.1 22.2 62.9
USB2 St2 Old 0.906 0.888 0.889 42.2 56.7 291.7
USB2 St3 Patriot Rge 0.817 0.789 0.937 3.7 10.1 30.0
USB2 St4 Pat Ext4 0.775 0.776 0.801 6.0 3.6 10.3
USB3 St5 San Exteme 0.894 0.891 0.871 1.4 1.2 0.8 [3]
USB3 St6 San Ex Ext4 0.839 0.822 0.845 0.9 0.8 0.8 [3]
USB3 St7 San Ex F2fs 0.851 0.903 0.896 2.1 3.2 2.3 [3]
USB3 St6 4 KB Ext4 0.928 0.940 0.950 1.0 1.0 1.0 [4]
USB3 St7 4 KB F2fs 0.926 0.943 0.946 0.9 0.9 0.9 [4]
USB3 St6 Cached Ext4 0.024 0.034 0.114 0.03 0.03 0.04 [5]
USB3 St7 Cached F2fs 0.025 0.021 0.191 0.01 0.01 0.01 [5]
1 GB file 4 KB from 256, 512, 1024 MB
USB3 St6 Cached Ext4 1.168 1.137 1.117 0.32 1.07 0.56 [6]
USB3 St7 Cached F2fs 1.212 1.160 1.149 0.13 0.12 0.14 [6]
USB2 HD FAT 0.904 1.490 3.879 1.7 2.1 2.3
USB2 HD Ext4 0.892 1.750 4.250 1.6 2.2 2.4
Raspberry Pi 2
SD Main 8 GB 0.389 0.571 0.403 3.5 8.3 3.4
SD 4A 16 GB 0.656 0.708 0.698 2.2 3.2 2.7
SD 4B 16 GB 0.807 0.856 0.843 2.8 4.5 2.1
USB3 St5 32 GB FAT 0.979 0.484 0.481 1.40 1.60 0.61
USB3 St6 32 GB Ext4 0.415 0.416 0.439 0.69 0.75 0.59
Raspberry Pi 3
SD Main 16 GB 0.460 0.450 0.400 1.68 2.60 1.77
USB2 8 GB FAT 0.717 0.771 0.797 1.94 2.38 2.41
Linux
Main HD PC Ext4 0.501 0.385 4.163 1.5 2.5 3.3
USB2 St1 Linux FAT 0.501 0.498 0.499 91.9 41.5 80.1
USB3 St5 Linux FAT 0.505 0.501 0.500 0.8 1.0 1.5 [3]
USB3 St6 Linux Ext4 0.503 0.498 0.499 1.1 0.8 0.6 [3]
USB3 St7 Linux F2fs 0.602 0.624 0.624 1.8 1.7 1.8 [3]
Milliseconds per file
Write Read Delete
File KB 4 8 16 4 8 16 Seconds
SD Main 5.30 4.15 4.49 0.87 0.94 1.39 0.108
SD 2 4.99 6.25 6.39 1.16 1.65 2.23 0.122
SD 3 5.83 17.44 8.40 1.37 1.99 2.64 0.105
SD 4 2.68 2.58 3.79 0.82 0.94 1.33 0.094
USB2 St1 FAT 30.75 18.41 25.15 1.09 1.17 1.55 0.100
USB2 St2 FAT 53.83 40.84 35.26 1.75 1.63 1.98 0.058
USB2 St3 Pat FAT 15.01 15.71 19.27 1.25 1.46 1.57 0.096
USB2 St4 Pat Ext4 4.48 4.73 8.72 1.14 1.30 1.61 0.043
USB3 St5 San Ex FAT 4.95 4.48 4.94 1.01 1.30 1.51 0.445 [7]
USB3 St6 San Ex Ext4 1.57 1.43 2.02 0.98 1.06 1.32 0.043 [7]
USB3 St7 San Ex F2fs 1.56 1.51 1.87 0.92 1.05 1.36 0.032 [7]
USB2 HD FAT 8.87 8.20 8.49 1.46 1.37 1.97 0.409
USB2 HD Ext4 2.86 1.88 2.23 4.43 1.50 1.57 0.109
Raspberry Pi 2
SD Main 2.79 2.27 2.72 0.57 0.84 1.25 0.036
SD 4A 1.49 2.22 1.20 0.64 0.91 1.14 0.037
SD 4B 0.96 1.21 1.74 0.60 0.86 1.29 0.037
USB3 St5 32 GB FAT 2.39 1.77 9.88 0.42 0.67 3.60 0.043
USB3 St6 32 GB Ext4 1.02 0.84 2.37 0.71 0.57 0.76 0.025
Raspberry Pi 3
SD Main 16 GB 4.39 1.75 3.83 0.54 0.70 1.09 0.019
USB2 8 GB FAT 7.24 9.12 12.72 0.64 0.74 0.63 0.012
Linux
Main HD PC 1.25 0.24 0.35 0.30 0.29 0.37 0.004
USB2 St1 Linux FAT 40.85 27.53 37.09 0.60 0.64 0.89 0.004
USB3 St5 Linux FAT 1 10.49 10.70 10.86 0.53 0.67 0.73 0.004 [7]
USB3 St5 Linux FAT 2 1.22 1.07 0.96 0.69 0.73 0.76 0.003 [7]
USB3 St6 Linux Ext4 0.72 0.65 0.90 0.38 0.52 0.76 0.004 [7]
USB3 St7 Linux F2fs 0.51 0.59 0.51 0.39 0.51 0.40 0.003 [7]
FAT 1 and FAT 2 Typical variations on this device using FAT
SD 4A Old USB 2 Hub, SD 4B USB 3 card reader
|
DriveSpeed F2FS Format
F2FS Flash Friendly File System was created by Samsung to work with Linux, specifically to suit characteristics of such as SSDs and SD cards. Published benchmark results often show that writing performance is superior to using Ext4 format, particularly with random access. Others indicate faster speeds on handling small files.
In order to format a USB Flash drive, a recent version of Linux is required. In my case, Ubuntu 13.10 with Linux 3.12.0 was installed, followed by f2fs-tools. I formatted my SanDisk Extreme USB 3.0 drive, using GParted, with three partitions, FAT, Ext4 and F2fs. The F2fs partition was shown as having an unknown format and did not show using the DF command. However, it could be mounted as shown here. Even then it was not visible in Ubuntu, but the directory path could be accessed by the benchmark (using sudo).
For the Raspberry Pi, I downloaded and installed 2013.12.20 Rasbian with Linux 3.10. This provides support at least for reading and writing F2fs partitions. Initially, the existing F2fs USB drive partition was not visible using the df command but, as the drive had another partition, the Filesystem path could be assumed and mounted. DriveSpeed benchmark was run on the Linux PC and RPi, results being included above under St5, St6 and St7 - See [] references.
Large Files - The three different formats produced the same high speed writing and reading on the Linux PC [1] but with some degradation on writing on the RPi to F2fs and particularly FAT [2].
Random Access - Random reading was slightly slower using F2fs and noticeably the slowest on writing. Again the Linux PC was faster [3]. Random access for the benchmark is via 1 KB block sizes. Using VMSTAT and F2fs, it was found that 4 KB was being read and written for each 1 KB access. Increasing block size to 4 KB avoided the reading and F2fs was slightly faster than Ext4 [4].
Random Access Cached - The benchmark opens the file for random access using Direct I/O, avoiding data being kept in the RAM based cache. Enabling caching produces ridiculously fast response times, with the file sizes used [5] (at 1KB block size).
Random Access Larger Files - The next step was to see what happens with larger files, where up to 1 GB was used [6] (with 4 KB blocks). In this case, random writing times varied considerably with Ext4 (more than shown) but were consistently much faster with F2fs formatting, apparently due to the way in which data stored. The benchmark is supposed to measure speeds over four seconds but, with Ext4, actual time could be much longer, probably due to shuffling the memory after writing was committed.
Small Files - [7] Average writing and reading times of small files could vary quite a bit but, using Ext4 and F2fs, were generally faster than via FAT formatting and F2fs marginally the winner.
Random Accesses Longer Time - Below [8]are further cached results with 4 KB from 256, 512 and 1024 MB, but running for 40 seconds (Ext4 up to 45 seconds), from which the number of transactions executed has been calculated. Other statistics shown were derived from running VMSTAT at the same time.
Ext4 and F2fs response times and system loading are similar on reading. The speed is now much faster reading from 256 MB, with higher CPU utilisation, due to more data being in the RAM based cache. KB per transaction numbers represent data read over the USB and this can be larger than the 4 KB data requests.
Writing response times are a little slower than with 4 second tests but more consistent with Ext4. The most important observation is that F2fs is still remarkably fast, transferring data over USB at near maximum speed and with high CPU utilisation organising the data.
4 KB Random Access Over 40 Seconds [8]
Read Write
From MB 256 512 1024 256 512 1024
USB3 St6 Cached Ext4 msecs 0.099 0.617 0.967 0.80 1.35 1.26
Transactions x 1000 404 65 41 53 33 33
Million Bytes 263 314 324 151 139 115
KB per transaction 0.7 4.8 7.8 2.9 4.2 3.4
MB per second 6.6 7.8 8.1 3.6 3.1 2.7
CPU Utilisation 64% 49% 49% 33% 27% 30%
USB3 St7 Cached F2fs msecs 0.107 0.636 0.997 0.14 0.17 0.18
Transactions x 1000 374 63 40 286 235 222
Million Bytes 262 310 318 945 885 833
KB per transaction 0.7 4.9 7.9 3.3 3.8 3.7
MB per second 6.6 7.7 7.9 23.6 22.1 20.8
CPU Utilisation 62% 50% 49% 95% 91% 92%
|
Copying F2FS Files
Performance investigation of USB drives formatted with F2fs, compared with Ext4, were prompted by reports in XBMC Community Forum that copying files to the former was up to nine times faster than to the same drive formatted as Ext4. The particular page is not now directly available but might still be found by Googling for “OpenELEC Testbuilds for RaspberryPi Part 2?2013-12-19 20:03 (was page 199, later 133). DriveSpeed benchmark did not demonstrate this level of performance gain, except during an extended period of random writing. Now, copying files is likely to involve normal reading and writing, transferring data via a RAM based file cache.
DriveSpeed measures speed with caching enabled, but for larger files. A modified caching version was produced using a large number of small files of increasing sizes where, unlike copying, writing precedes reading. Average results of three tests are shown below [9]. F2fs is faster using smaller files, but not that much, with the position reversed as file sizes are increased. Data transfer speed in MBytes per second is provided [10], to demonstrate caching, where USB speed is exceeded (like > 30 MB/second). Data was not cached, starting at 256 MB, half RAM size.
Next stage involved producing a series of directories, with average file sizes between 6 KB and 500 KB, occupying >100 MB (similar to sizes quoted in XBMC Forum). Results, below [11] show that, still using the SanDisk Extreme USB 3.0 drive, F2fs is a little faster at the larger file sizes, but the position is reversed at reducing file sizes. Most significant is at 6 KB, where Ext4 is 70% faster, with the du command reporting 178 MB, compared with 269 MB with F2fs. VMSTAT recorded MegaBytes written, read, memory used and cache space are also shown for this test, confirming at least these volumes. Windows identified total file size and disk space used under NTFS are also shown. For comparison purposes, calculated MB/second speeds are based on the former.
I installed XBMC Media Center, on a Windows based PC, to produce a Thumbnails directory from photographs, included in the mix, in case there was something special about them. The directory comprised 4370 JPG files at around 34 KB average size, occupying 161 MB with Ext4 and 178 MB under F2fs, the former being slightly faster. These directories were also copied, using two other USB sticks, via the Raspberry Pi and a Linux based PC (plus limited tests with FAT formatting). Linux was faster on all, and the other drives were slower than the Extreme, but there were no significant variations between Ext4 and F2fs formatting. Results are again shown below.
XBMC for the Raspberry Pi is part of OpenElec (Open Embedded Linux Entertainment Center). I installed various versions of this on SD cards and ran DriveSpeed benchmark and file copying tests, booted to OpenElec.
Details are in
Raspberry Pi OpenElec Benchmarks.htm.
[9] DriveSpeed 1000 small files, cached, average milliseconds per file, Extreme Drive
File KB 4 8 16 32 64 128 256 512 1024
F2FS
Write 0.35 0.32 0.45 0.63 1.50 3.40 9.67 20.49 40.97
Read 0.09 0.12 0.18 0.28 0.69 1.72 13.00 23.29 43.94
Ext4
Write 0.46 0.48 0.60 1.07 2.33 5.28 10.21 20.29 43.40
Read 0.12 0.16 0.21 0.33 0.63 1.43 11.80 21.33 43.75
[10] F2FS MB/second
Write 11.5 25.0 35.8 51.1 42.8 37.6 26.5 25.0 25.0
Read 44.4 68.6 88.9 112.9 92.8 74.6 19.7 22.0 23.3
Copying command and results format
time sh -c "cp -r /source /destination && sync"
real 0m35.851s
user 0m0.420s
sys 0m7.420s
[11] Copying Six Different Directories Extreme Drive
Based on Win MB
Win KB Win Win on F2FS Ext4 F2FS Ext4 F2FS Ext4
Set Files /file MB Drive du MB du MB Secs Secs MB/sec MB/sec
1 22945 6 129 173 269 xxx 178 106.9 63.0 1.2 2.0
2 12974 11 140 171 227 176 66.5 57.0 2.1 2.5
3 7118 23 161 179 212 184 47.2 39.1 3.4 4.1
4T 4370 34 148 156 178 161 35.9 30.0 4.1 4.9
5 932 107 100 102 109 105 14.9 18.0 6.7 5.6
6 959 492 472 474 466 462 46.2 51.6 10.2 9.1
xxx vmstat MB F2FS Read 272 Write 277, Ext4 Read 184 Write 223
xxx vmstat MB F2FS RAM 298 Cache 288, Ext4 RAM 286 Cache 248
XBMC Thumbnails 4T - 4370 Files 148 MB
F2FS Ext4 FAT
Drive Elap CPU MB/sec Elap CPU MB/sec Elap CPU MB/sec
Secs Secs Secs Secs Secs Secs
Rpi
Extreme 35.9 7.8 4.1 30.0 8.2 4.9 64.9 19.9 2.3
Attache 75.3 7.8 2.0 75.4 9.2 2.0
Cruzer 118.9 7.9 1.2 103.7 9.2 1.4
Linux
Extreme 26.9 0.8 5.5 26.8 0.8 5.5 55.7 1.8 2.7
Attache 54.7 0.7 2.7 65.0 0.7 2.3
Cruzer 98.6 0.7 1.5 86.4 0.8 1.7
|
LAN/WiFi Benchmark - LanSpeed
This is mainly the same as the DriveSpeed benchmark, described above. The exception is that the cached data test is not possible and the open file options to avoid caching produces run time errors. The benchmark and source code are again in Raspberry_Pi_Benchmarks.zip. Tests carried out are:
Test 1 - Write and read three 8 and 16 MB; Results given in MBytes/second
Test 2 - Random write and read 1 KB from 4 to 16 MB; Results are Average time in milliseconds
Test 3 - Write and read 200 files 4 KB to 16 KB; Results in MB/sec, msecs/file and delete seconds.
The benchmark can measure performance communicating to both Windows and Linux via Local Area Network (LAN), including a wireless connection, in my case via a Windows Workgroup. The first step is to set up a directory on the Raspberry Pi to mirror the remote sharable data, in my case /public in /media. Then, a directory on the remote system is useful, in my case /test.
The second step is to obtain the Internet Protocol (IP) address of remote PCs - in my case this is dynamic, variable not constant. The appropriate commands are shown below, followed by those for the third step to mount the sharable drive, partition or directory.
The benchmark can be run in three ways with LAN involvement, firstly with the Terminal pointing to the directory on the RPi containing the benchmark and a FilePath parameter /media/public/test (in my case). The second method requires a copy of LanSpeed in /media/public/test with Terminal pointing to that source. The final method uses the remote copy but just loads the benchmark and uses the home (or whichever) folder for writing and reading files, with no LAN activity. As with DriveSpeed, a run time parameter can also specify minimum size for the large file tests (example ./LanSpeed MB 32 for 32 and 64 MB).
64 Bit Versions - See
Drive and LAN Benchmarks.
Create new folder command - sudo mkdir /media/public NOTE: there should be no spaces after commas with multiple -o options Windows Command Prompt ipconfig command = 192.168.0.2 Windows share drive (partition) d sudo mount -t cifs -o dir_mode=0777,file_mode=0777 //192.168.0.2/d /media/public can also add -o password=pi - in this case unchanged default password Linux Terminal command ifconfig eth0 (or eth1) = 192.168.0.3 Linux Wireless Connection Information = 192.168.0.4 Linux share directory all sudo mount -t cifs -o user=UU,password=PP //192.168.0.3/all /media/public UU and PP are IDs for Linux system, -o dir_mode=0777,file_mode=0777 not needed NOTE: If wrong IDs are used, a locked file will be generated and this leads to a failure to open a new file when correct IDs are used. The file must be deleted. Benchmark and log on Raspberry Pi pi@raspberrypi ~/benchmarks/lanspeed $ ./LanSpeed FilePath /media/public/test Benchmark and log on remote system pi@raspberrypi /media/public/test $ ./LanSpeed Benchmark remote, data and log /home/pi - does not use LAN pi@raspberrypi ~ $ /media/public/test/LanSpeed sudo umount //192.168.0.2/d or //192.168.0.3/all |
LAN/WiFi Benchmark - More
The Raspberry Pi LAN speed is rated at 100 Mbps, whereby maximum data transfer speed will be less than 12.5 MB/second, due to overheads. See the example results below. The overheads also lead to the fairly constant average time to write and read small files.
See Raspberry Pi 2 results in comparisons, below.
#####################################################
LanSpeed RasPi 1.0 Tue Jul 2 10:56:28 2013
Current Directory Path: /media/public/test
Total MB 230000, Free MB 85052, Used MB 144948
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 7.49 5.84 8.13 11.56 9.04 11.57
16 7.29 8.13 6.78 11.53 11.60 11.58
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.011 2.272 1.651 3.40 4.12 4.17
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.62 1.20 2.13 1.05 1.62 2.74
ms/file 6.63 6.83 7.68 3.88 5.07 5.98 0.280
End of test Tue Jul 2 10:57:12 2013
|
Intel Linux and Windows Versions - LanSpdx86Lin, LanSpdx86Win.exe
Versions to run on Intel processors via Linux and Windows have been produced. The former was compiled from the supplied lanspeed.c code, but with a different version string for printing. The Windows version has some slight changes, inherited from an earlier benchmark. The execution files are included in the zip file. They can be run from the host PC or stored on the RPi drive and executed via the LAN.
In order for Windows Workgroup systems to access RPi files, samba and samba-common-bin need to be installed, along with changes to /etc/samba/smb.conf. Detailed procedures are in Treating Raspberry Pi as just another Windows machine.
The remote Pi can be made visible using Windows “Map network drive" - T: on my PC). The Raspberry Pi user name and password need to be entered (I seem to have changed the password from raspberry to pi, so mine in pi and pi). The benchmark can the be run from a Windows Command prompt in two ways, as shown below, where LanSpdx86Win.exe is in folder D:\WinDDK\32bit\lanspeed. The .exe file can also be copied to a folder on the Pi, the folder selected in Windows and the benchmark run by double clicking on the .exe file. The log will be saved in the same folder.
The rather convoluted mount command, shown below, is needed to run from Linux. The benchmark (in my case from roy@roy-64Bit:~/all/lanspeed$) can be run from a Terminal command, also shown below. The program can be saved on the RPi (in /media/public/lanspeed). I also copied a script file, runlan86, with the command "./LanSpdx86Lin" and execution permission set. This can be run by clicking on the script file, where output is on the Linux Terminal display.
Windows D:\WinDDK\32bit\lanspeed>LanSpdx86Win FilePath T:\test D:\WinDDK\32bit\lanspeed>LanSpdx86Win FilePath \\MYPI\pi\test Raspberry Pi ifconfig eth0 = 192.168.0.8 Linux Ubuntu 10.10 using smbfs - mount all on one line sudo mount -t smbfs -o user=pi,password=pi,dir_mode=0777,file_mode=0777 //192.168.0.8/public/home/pi/benchmarks /media/public Linux run command - ./LanSpdx86Lin FilePath /media/public/lanspeed |
LAN/WiFi Comparison
The results log files identify the system running the tests in Configuration Details with somewhat different variations using Windows and Linux. The destination system can normally be identified from logged Current Directory Path and Total MB (drive capacity).
The first four results are for the RPi handling data to/from Windows and Linux, then as destination from/to the two PCs. It should be noted that there can be significant performance differences depending on which system is the source or destination.
The next two sets of results are from RPi to a laptop via WiFi, showing the reduction in speed when the laptop is some distance from the router. These are followed by a test not using the LAN, but with RPi accessing the local drive, as DriveSpeed above, where data is cached in RAM.
The last four results are using a Gigabit LAN, again with wide variations in performance depending on the configuration used.
Some LanSpeed Raspberry Pi 2 results are included. Running this, accessing a Windows PC, appeared to produce more consistent high reading and writing times for the large files, at over 11 MB/second (demonstrating 100 Mbps LAN), compared with the original RPi. Running LanSpdx86Win.exe, stored on the SD drive, demonstrated some improvement.
Source Dest MBytes/Second
CPU CPU/drive MB Write1 Write2 Write3 Read1 Read2 Read3
Rpi Ph Win 16 7.29 8.13 6.78 11.53 11.60 11.58
Ph Win Rpi 16 11.29 11.18 10.70 4.22 2.70 1.97
Rpi 2 Ph Win 16 11.31 11.32 11.32 11.65 10.80 11.65
Ph Win RPi 2 16 11.51 11.53 11.49 5.33 3.47 2.57
Rpi 3 Ph Win 16 11.41 11.40 11.39 11.68 11.66 11.67 LAN
Rpi 3 Ph Win 16 2.69 3.16 2.63 1.60 1.46 0.80 WiFi
Rpi C2 Lin 16 7.79 7.52 7.84 11.62 11.61 11.66
C2 Lin Rpi 16 6.53 6.36 6.23 5.58 5.49 6.01
Rpi LT Lin 16 3.23 3.24 3.20 3.59 3.50 3.50 WiFi
Rpi LT Lin 16 1.78 1.62 1.00 0.92 0.89 0.39 WiFi outside
Rpi Rpi 16 57.41 60.05 50.00 155.48 152.66 155.89 cached
C2 Lin Ph Win 16 57.76 54.31 55.02 33.82 31.91 32.13 1Gbps
Ph Win C2 Lin 16 108.62 89.62 109.83 36.45 22.09 15.30 write later
Ph Win C2 Win 16 29.19 38.20 38.18 21.48 14.95 11.59 1Gbps
C2 Win Ph Win 16 72.36 68.46 50.16 25.96 18.76 12.71 1Gbps
Random msecs Read Write
From MB 4 8 16 4 8 16
Rpi Ph Win 0.011 2.272 1.651 3.40 4.12 4.17
Ph Win Rpi 1.299 1.208 1.275 1.29 1.37 1.28
Rpi 2 Ph Win 0.124 0.911 0.998 1.96 1.56 1.68
Ph Win RPi 2 0.722 0.699 0.688 0.73 0.73 0.73
Rpi 3 Ph Win 0.459 0.864 0.743 3.47 2.77 3.16 LAN
Rpi 3 Ph Win 7.178 10.447 7.784 11.18 9.79 8.99 WiFi
Rpi C2 Lin 0.637 2.160 0.872 2.42 2.14 2.15
C2 Lin Rpi 1.820 0.978 1.259 3.05 2.49 2.45
Rpi LT Lin 4.520 5.391 3.234 4.08 3.22 3.16 WiFi
Rpi LT Lin 10.264 11.906 11.107 5.16 4.08 4.29 WiFi outside
Rpi Rpi 0.012 0.012 0.012 23.03 24.69 25.01 cached
C2 Lin Ph Win 0.001 0.002 0.002 1.79 2.04 1.77 1Gbps
Ph Win C2 Lin 0.556 0.468 0.423 0.43 0.43 0.43 write later
Ph Win C2 Win 0.846 0.875 5.553 1.13 2.41 2.88 1Gbps
C2 Win Ph Win 0.613 0.585 0.583 0.88 1.24 1.37 1Gbps
milliseconds per file
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
Rpi Ph Win 6.63 6.83 7.68 3.88 5.07 5.98 0.28
Ph Win Rpi 14.15 14.21 15.76 10.32 10.52 11.47 1.79
Rpi 2 Ph Win 3.92 4.31 5.08 2.33 2.65 3.48 0.15
Ph Win RPi 2 7.78 8.33 9.54 4.84 5.31 5.96 0.74
Rpi 3 Ph Win 4.39 4.66 5.39 1.79 2.31 3.29 0.33 LAN
Rpi 3 Ph Win 30.22 34.09 53.57 36.84 22.94 40.33 3.13 WiFi
Rpi C2 Lin 5.74 6.83 8.96 4.87 5.97 6.74 0.60
C2 Lin Rpi 9.87 10.55 11.73 7.13 7.52 8.44 1.30
Rpi LT Lin 9.79 10.81 13.34 7.69 8.95 11.53 1.07 WiFi
Rpi LT Lin 12.26 16.08 18.94 9.30 12.53 15.09 1.54 WiFi outside
Rpi Rpi 0.87 0.73 0.67 0.08 0.15 0.19 0.05 cached
C2 Lin Ph Win 2.57 2.52 2.61 0.85 0.83 0.86 0.13 1Gbps
Ph Win C2 Lin 3.72 3.58 3.60 3.20 3.22 3.31 0.52 write later
Ph Win C2 Win 4.92 3.46 3.50 3.22 3.09 3.42 0.40 1Gbps
C2 Win Ph Win 3.10 3.12 3.19 3.99 2.93 2.73 0.46 1Gbps
Ph Win = Phenom Windows 7 C2 Win = Core 2 Vista C2 Lin = Core 2 Ubuntu 10.1
LT Lin = Laptop Ubuntu 10.1 RPi = Raspberry Pi
|
DriveSpeed64, DriveSpeed64Long and LanSpeed64
As indicated earlier, the DriveSpeed and LanSpeed benchmarks are identical, except the former opens files with a parameter to not use caching, except for the cached test. Result for both are shown below, where many were not as expected and those from Gentoo, OpenSUSE and SUSE SLES were often different. Perhaps this could be changed via Linux tuning parameters. LanSpeed benchmark speeds are also shown from running on local drives, to help to explain unusual results.
Performance of these cannot be compared with earlier 32 bit varieties via Raspbian, as the 64 bit Linux systems are installed on faster micro USB cards, but what can be compared is relative behaviour. These comments are included in the results below.
DriveSpeed64 and DriveSpeed64Long - This only ran successfully via SUSE SLES on the main drive and a Gentoo USB connected external SD card with btrfs format, but still with certain peculiarities. Although the benchmarks did not run properly using USB flash drives, there were no problems in using normal USB connections via Gentoo, but rather complex procedures were required to mount USB drives via OpenSUSE.
LanSpeed64 - Only OpenSUSE could be used, following instructions provided here. Samba for Gentoo was said to be not tested at 64 bits and that for SUSE SLES could not be downloaded following a necessary reinstallation of the system. LanSpeed64 was also run targeting USB and main drives, mainly to identify caching effects. As shown below, there were some strange results.
These 64 bit benchmarks and source codes are now included in Rpi3-64-Bit-Benchmarks.tar.gz.
Complete logs of the latest 32 Bit Results are also provided, showing expected performance pattern is still being produced.
###################### DriveSpeed64 SUSE SLES ######################
DriveSpeed RasPi 64 Bit 1.1 Mon Apr 3 23:40:21 2017
Current Directory Path: /home/roy/driveLANSUSE
Total MB 29465, Free MB 27495, Used MB 1970
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 10.26 15.50 7.78 47.27 51.62 48.91
16 10.58 13.86 10.14 54.05 55.50 45.78
Cached
8 520.96 586.68 601.25 709.43 709.23 706.46
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.005 0.004 0.004 16.91 20.31 22.13
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.25 0.36 1.06 252.55 403.28 621.47
ms/file 16.10 23.00 15.43 0.02 0.02 0.03 0.029
End of test Mon Apr 3 23:40:59 2017
>>>>>>>>>>>>>>>>>>> Comparison with 32 Bit Version <<<<<<<<<<<<<<<<<<<
Large Files > Faster SD card reflected, reading > twice as fast
Random > Writing exceptionally slow, reading far too fast, data cached?
Small Files > Writing exceptionally slow, reading far too fast, data cached?
#################### DriveSpeed64Long SUSE SLES ####################
Linux Storage Speed Test 64-Bit Version 1.2, Mon Apr 3 23:42:37 2017
Current Directory Path:
/home/roy/driveLANSUSE
Total MB 29465, Free MB 27495, Used MB 1970
8 MB File 1 2 3 4 5
Writing MB/sec 16.26 7.47 10.28 7.43 10.54
Reading MB/sec 45.71 53.63 48.12 61.91 38.85
16 MB File 1 2 3 4 5
Writing MB/sec 13.88 10.92 11.15 8.22 10.59
Reading MB/sec 55.18 55.05 52.56 56.11 67.87
32 MB File 1 2 3 4 5
Writing MB/sec 9.18 10.36 10.23 9.45 10.99
Reading MB/sec 54.81 51.33 52.77 50.28 54.82
---------------------------------------------------------------------
8 MB Cached File 1 2 3 4 5
Writing MB/sec 505.97 566.27 554.70 567.73 572.96
Reading MB/sec 583.78 689.28 696.95 687.48 695.33
---------------------------------------------------------------------
Bus Speed Block KB 64 128 256 512 1024
Reading MB/sec 3096.23 3292.99 1743.08 808.57 733.75
---------------------------------------------------------------------
1 KB Blocks File MB > 2 4 8 16 32 64 128
Random Read msecs 0.54 0.57 1.01 0.71 0.64 0.65 0.65
Random Write msecs 17.21 10.61 12.56 10.99 22.69 23.40 15.47
---------------------------------------------------------------------
500 Files Write Read Delete
File KB MB/sec ms/File MB/sec ms/File Seconds
2 0.17 11.79 57.04 0.04 0.073
4 0.27 15.16 184.70 0.02 0.063
8 0.55 14.86 414.95 0.02 0.071
16 0.96 17.12 334.40 0.05 0.077
32 1.92 17.10 700.71 0.05 0.080
64 2.30 28.51 207.18 0.32 0.093
End of test Mon Apr 3 23:45:06 2017
>>>>>>>>>>>>>>>>>>> Comparison with Short Version <<<<<<<<<<<<<<<<<<<<
Large Files > Similar speeds
Random > Writing speed similar, reading speed quite normal.
The file used is 128 MB, compared with 16 MB
Small Files > Writing and reading speed similar, latter still too fast
############### DriveSpeed64 & Long OpenSUSE & Gentoo ###############
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8
Error writing file <<<<<< Could not handle Direct I/O
Segmentation fault <<<<<< See next, same program normal cached I/O
############## LanSpeed64 Example Running On Main Drive #############
To demonstrate caching effects
LanSpeed RasPi 64 Bit 1.0 Tue Apr 4 12:21:50 2017
Current Directory Path: /home/driveLANOSUSE48
Total MB 14210, Free MB 10766, Used MB 3444
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 219.04 239.01 192.05 382.28 380.89 380.13
16 217.11 210.56 179.51 359.47 278.78 372.17
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.004 0.005 0.004 156.99 32.99 16.36
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 49.40 66.06 106.01 194.50 377.95 537.56
ms/file 0.08 0.12 0.15 0.02 0.02 0.03 0.012
End of test Tue Apr 4 12:22:22 2017
######################### LanSpeed64 Example #######################
LanSpeed RasPi 64 Bit 1.0 Tue Apr 4 13:04:06 2017
Selected File Path:
/root/Desktop/sharepc/
Total MB 266240, Free MB 134653, Used MB 131587
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 11.23 11.40 11.40 8.10 11.62 11.64
16 11.27 11.42 11.44 11.66 11.66 11.64
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.724 0.886 1.333 1.58 1.50 1.37
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.99 1.81 2.73 1.77 3.02 4.50
ms/file 4.13 4.54 6.01 2.32 2.71 3.64 0.201
End of test Tue Apr 4 13:04:43 2017
>>>>>>>>>>>>> Comparison with 32 Bit Version Rpi 3 Ph Win <<<<<<<<<<<<<
Large Files > Similar speeds reflecting 100 Mbps
Random > Similar but writing faster, no apparent caching
Small Files > Similar speeds
################### DriveSpeed64 USB Flash Drive ###################
DriveSpeed RasPi 64 Bit 1.1 Tue Apr 4 10:41:03 2017
Gentoo USB 3 Stick
Selected File Path:
/run/media/demouser/8EDA-9C1C/gentoo//
Total MB 59665, Free MB 59663, Used MB 2
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 12.16 11.78 11.65
Error reading file
Gentoo USB 2 Stick
8 3.10 3.50 2.78
Error reading file
OPenSUSE USB 3 Stick
8 5.30 14.01 14.27
Error reading file
>>>>>>>>> Direct I/O to USB Flash Drives, cannot read
>>>>>>>>> See later LAN test, same program, normal cached I/O
################## DriveSpeed64 External SD Card ###################
Gentoo via USB, btrfs format
DriveSpeed RasPi 64 Bit 1.1 Tue Apr 4 10:28:11 2017
Selected File Path:
/run/media/demouser/ROOT/home/roy/benchmarks//
Total MB 29465, Free MB 27511, Used MB 1953
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 5.53 10.64 12.23 29.99 31.88 33.25
16 6.88 6.82 8.53 31.21 26.41 28.64
Cached
8 159.30 175.77 158.98 235.45 229.22 266.71
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.016 0.006 0.006 20.67 50.55 22.84
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.25 0.40 0.97 58.44 160.18 150.07
ms/file 16.09 20.66 16.87 0.07 0.05 0.11 0.160
>>>>>>>> Similar pattern to DriveSpeed64 SUSE SLES main drive above
>>>>>>>> But slower due to USB data transfer speed
################ LanSpeed64 Gentoo USB 3 Flash Drive ###############
LanSpeed RasPi 64 Bit 1.0 Tue Apr 4 10:57:15 2017
Selected File Path:
/run/media/demouser/8EDA-9C1C/gentoo/
Total MB 59665, Free MB 59639, Used MB 26
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 29.84 32.89 36.14 619.40 644.11 423.39
16 53.39 18.56 17.62 675.52 337.83 380.98
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.003 0.003 0.003 5.71 5.26 4.07
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.97 0.93 3.24 163.54 268.83 430.68
ms/file 4.21 8.83 5.06 0.03 0.03 0.04 0.066
End of test Tue Apr 4 10:57:43 2017
>>>>>>>> Similar pattern to LanSpeed64 Running On Main Drive above
>>>>>>>> But slower due to USB data transfer speed
################ LanSpeed64 Gentoo USB 2 Flash Drive ###############
LanSpeed RasPi 64 Bit 1.0 Tue Apr 4 10:22:24 2017
Current Directory Path: /home/demouser/driveLANGENTOO
Total MB 14118, Free MB 7431, Used MB 6688
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 83.67 114.47 122.94 372.52 369.38 238.50
16 113.20 152.20 114.87 332.33 237.96 392.18
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.003 0.003 0.003 5.08 8.85 4.28
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 27.93 13.34 30.62 133.59 394.21 372.22
ms/file 0.15 0.61 0.53 0.03 0.02 0.04 0.021
End of test Tue Apr 4 10:22:42 2017
>>>>>>>> Faster writing than USB 3, cached vs writing to drive
>>>>>>>> Possibly because USB 3 drive is 64 GB vs 16 GB
################ 32 Bit DriveSpeed Reference Results ################
#################### DriveSpeed USB 3 Flash Drive ###################
DriveSpeed RasPi 1.1 Tue Apr 18 13:45:16 2017
Selected File Path:
/media/pi/8EDA-9C1C/
Total MB 59665, Free MB 59638, Used MB 27
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 17.30 16.31 15.95 34.91 35.87 34.29
16 8.96 11.45 13.55 35.26 35.58 35.73
Cached
8 51.79 59.95 3.80 524.88 497.86 594.12
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.762 0.818 0.826 5.27 4.96 4.51
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.54 0.69 1.26 4.00 5.29 14.04
ms/file 7.64 11.94 13.01 1.02 1.55 1.17 0.013
End of test Tue Apr 18 13:45:53 2017
>>>>>>>> Unlike the 64 bit version, this runs as expected
################# External MicroSD Ultra card via USB ###############
DriveSpeed RasPi 1.1 Tue Apr 18 10:50:17 2017
Selected File Path:
/media/pi/ROOT/home/benchmarks/test/
Total MB 14210, Free MB 10860, Used MB 3350
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 6.75 7.55 8.33 10.86 10.90 10.81
16 7.94 6.38 7.11 10.82 10.80 10.81
Cached
8 160.69 173.57 296.09 719.21 742.73 713.39
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.804 0.827 0.809 2.90 2.55 2.55
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 3.34 5.25 3.87 4.11 6.10 5.42
ms/file 1.23 1.56 4.23 1.00 1.34 3.02 0.022
End of test Tue Apr 18 10:50:55 2017
>>>>>>>> Unlike here, the 64 bit version unexpectedly produced
fast (cached?) reading and slow writing speeds
################# 32 Bit LanSpeed Reference Results #################
##################### LanSpeed USB 3 Flash Drive ####################
LanSpeed RasPi 1.0 Tue Apr 18 13:49:04 2017
Selected File Path:
/media/pi/8EDA-9C1C/
Total MB 59665, Free MB 59662, Used MB 3
MBytes/Second
MB Write1 Write2 Write3 Read1 Read2 Read3
8 46.32 59.94 20.98 703.69 716.66 694.25
16 90.11 20.46 15.68 700.87 703.35 692.30
Random Read Write
From MB 4 8 16 4 8 16
msecs 0.003 0.003 0.003 3.83 4.92 8.12
200 Files Write Read Delete
File KB 4 8 16 4 8 16 secs
MB/sec 0.58 2.09 1.97 254.55 213.75 318.84
ms/file 7.04 3.91 8.32 0.02 0.04 0.05 0.028
End of test Tue Apr 18 13:49:30 2017
>>>>>>>> Accepting wide variations, 32 bit and 64 bit results are the same
|
Temperature Recorder - RPiTemperature - Later RPiHeatMHz For RPi 2
RPiTemperature has been replaced by RPiHeatMHz, to measure and log CPU MHz besides CPU temperature. The program is included in Raspberry_Pi_Benchmarks.zip. This uses data from the following to display and log results (see RPiHeatMHz.c in zip file):
/sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
/opt/vc/bin/vcgencmd measure_temp
Run time parameters specify number of samples and interval - see below. Default is 10 samples with 1 second delay between samples.
System settings on booting are also included. These are different on the Raspberry Pi 3, where overclocking is not provided.
2016 - the original MHz was measured using function scaling_cur_freq. Now, it is apparent that this does not show dynamic variations. The latest version of RPiHeatMHz now includes results from the measure_clock arm command. Below are example reports from the revised program running on a Raspberry Pi 3, showing that the two measures can be the same when nearly idling.
64 Bit Temperature Measurements - Two versions were produced with RPiHeatMHz64G using the same functions as the latest 32 bit versions, then RPiHeatMHz64S for the SUSE Operating Systems, where the vcgencmd command was not available, scaling_cur_freq was used for CPU throttling MHz and sensors function had to be installed to obtain CPU temperature (see log below)..
Command - ./RPiTemperature passes 5, seconds 2
Temperature Measurement - Start at Tue Jun 18 11:57:19 2013
Using 5 samples at 2 second intervals
Seconds
0.0 temp=50.8°C
2.0 temp=50.8°C
4.1 temp=50.8°C
6.1 temp=51.4°C
8.2 temp=50.8°C
10.2 temp=50.8°C
Temperature Measurement - End at Tue Jun 18 11:57:29 2013
##########################################################
New Command - ./RPiHeatMHz passes 5, seconds 2
Switches to 900 MHz whilst running CPU benchmark
Temperature and CPU MHz Measurement
Start at Sun Mar 1 07:14:19 2015
Using 5 samples at 2 second intervals
Boot Settings
arm_freq=900
hdmi_force_hotplug=1
config_hdmi_boost=4
overscan_left=24
overscan_right=24
overscan_top=16
overscan_bottom=16
disable_overscan=0
core_freq=250
sdram_freq=450
over_voltage=0
Seconds
0.0 600 MHz temp=44.4°C
2.0 600 MHz temp=44.4°C
4.1 600 MHz temp=44.4°C
6.1 600 MHz temp=44.4°C
8.2 600 MHz temp=43.9°C
10.3 600 MHz temp=44.4°C
End at Sun Mar 1 07:14:30 2015
#################### New RPiHeatMHz ####################
#################### & RPiHeatMHz64G ###################
From
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
vcgencmd measure_clock arm
vcgencmd measure_temp
Seconds
0.0 1200 scaling MHz, 1200 ARM MHz, temp=58.0°C
15.0 1200 scaling MHz, 1200 ARM MHz, temp=67.1°C
30.1 1200 scaling MHz, 1200 ARM MHz, temp=70.9°C
45.1 1200 scaling MHz, 1200 ARM MHz, temp=73.6°C
60.2 1200 scaling MHz, 1200 ARM MHz, temp=75.8°C
75.3 1200 scaling MHz, 1200 ARM MHz, temp=78.4°C
90.5 1200 scaling MHz, 1200 ARM MHz, temp=79.5°C
105.6 1200 scaling MHz, 1160 ARM MHz, temp=80.6°C
120.7 1200 scaling MHz, 1075 ARM MHz, temp=81.1°C
135.8 1200 scaling MHz, 1051 ARM MHz, temp=81.7°C
150.9 1200 scaling MHz, 1023 ARM MHz, temp=81.7°C
166.0 1200 scaling MHz, 1020 ARM MHz, temp=82.2°C
181.1 1200 scaling MHz, 1006 ARM MHz, temp=82.2°C
Seconds
0.0 600 scaling MHz, 600 ARM MHz, temp=55.8°C
1.0 1200 scaling MHz, 1200 ARM MHz, temp=56.4°C
2.0 1200 scaling MHz, 1200 ARM MHz, temp=56.4°C
3.1 1200 scaling MHz, 1200 ARM MHz, temp=56.9°C
4.1 1200 scaling MHz, 1200 ARM MHz, temp=56.9°C
5.2 600 scaling MHz, 600 ARM MHz, temp=56.4°C
##################### RPiHeatMHz64S ####################
From
cat /sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cur_freq
sensors -A
Seconds
0.0 1200 scaling MHz, bcm2835_thermal-virtual-0
Adapter: Virtual device
temp1: +60.7°C
10.0 1200 scaling MHz, bcm2835_thermal-virtual-0
Adapter: Virtual device
temp1: +63.4°C
|
Reliability Tests
Following are example results from running the modified OpenGL ES Benchmark and Livermore Loops Stability Test in reliability testing mode. The tests comprised running the OpenGL functions, then these plus the Loops program, both at normal (700 MHz) and overclocked CPU settings (CPU 1000 MHz, Core 500 MHz, SDRAM 600 MHz, 6 volts), measuring temperatures with RPiTemperature. The temperature recordings were at 30 second intervals with 36 samples, started first. With both test programs, the Livermore Loops were started next, at 10 seconds per test (24 x 3 x 10 = 720 seconds) but runs for longer due to early calibration. Finally, a full screen OpenGL test was started with a 15 minute setting (approximate, adjusted to 16 tests at 57 seconds).
On running just the OpenGL tests, FPS speed was virtually the same at 700 and 1000 MHz and only 7.5% slower running the Livermore Loops at the same time, at 700 MHz. As indicated earlier, OpenGL CPU utilisation was about 50%, leading to the Loops recording around half speed, when run at the same time.
Recorded temperatures for all tests are shown below, where room temperature was 23°C and the CPU allowed to cool down between tests. At 700 MHz, adding the Loops lead to a slightly faster temperature increase, but ending only about 3°C higher at 69.7°C. At 1000 MHz, and just OpenGL, maximum temperature was 69.1°C.
Repeating earlier observations, with hotter room temperature, the overclocked tests failed on running OpenGL and Livermore Loops tests at the same time. This time, the OpenGL program terminated with an “Illegal Instruction?after 75 seconds and the display froze on restarting, after a short delay. Temperatures were recorded at 15 second intervals, reaching 72.9°C.
Further reliability test programs have been produced. See
Raspberry Pi Stress Tests.htm
and
Raspberry Pi 2 and 3 Stress Tests.htm.
The latter includes some using the new
OpenGL GLUT Benchmark.
This required installation of a new experimental OpenGL GLUT driver to demonstrate much faster speeds. Unfortunately, this was found to cause the monitor to fail occasionally, displaying the multi-coloured square seen on booting. This occurred on Raspberry Pi 2, when overclocked, but more frequently using the Raspberry Pi 3. The solution was to install the new driver in a later version of the Raspbian Operating System. However, the stress tests showed that the Raspberry Pi 3 was getting too hot and it automatically reduced clock MHz (throttling) to lighten the load and decrease measured performance.
Later, the RPi 3 was fitted into a FLIRC Case, where the whole aluminium case becomes the heatsink. Then, CPU MHz and all the stress tests ran at maximum speeds, due to temperatures being lower than the point where clock throttling occurs.
See detailed reports on multitasking tests.
######################################################################
Command - ./OpenGL1Pi.bin Wide 1920, High 1080, RunMinutes 15
Raspberry Pi OpenGL ES Benchmark 1.1, Fri Jun 21 10:41:01 2013
Reliability Mode 16 Tests of 57 Seconds
--------- Frames Per Second --------
Triangles All Textured
36000+ 5.28 5.30 5.01 5.37
36000+ 5.37 5.51 5.78 5.80
36000+ 5.75 5.47 5.54 5.32
36000+ 5.29 5.30 5.42 5.91
Screen Pixels 1920 Wide 1080 High
End Time Fri Jun 21 10:56:17 2013
######################################################################
Command - ./liverloopsPiA6 Seconds 10
Livermore Loops Benchmark Opt 3 32 Bit via C/C++ Fri Jun 21 10:40:49 2013
Reliability test 10 seconds each loop x 24 x 3
Part 1 of 3 start at Fri Jun 21 10:40:49 2013
Part 2 of 3 start at Fri Jun 21 10:48:21 2013
Part 3 of 3 start at Fri Jun 21 10:52:31 2013
Numeric results were as expected
MFLOPS for 24 loops
59.4 65.6 97.1 81.5 9.0 13.7 55.2 72.0 41.9 19.9 17.0 12.3
10.1 6.9 26.6 34.4 55.1 19.9 44.6 18.9 11.3 13.6 30.1 14.2
Overall Ratings
Maximum Average Geomean Harmean Minimum
97.1 35.2 28.9 23.7 6.9
######################################################################
Command - ./RPiTemperature Passes 36, Seconds 30
O/C2 - ./RPiTemperature Passes 72, Seconds 15
Normal Overclocked
Seconds OGL OG+LPs OGL OG+LPs
0 50.3 49.8 50.8 51.4
15 59.5
30 56.2 56.2 56.2 67.0
45 70.2
60 60.0 60.5 61.1 71.8
75 72.9 Illegal
90 61.1 62.7 63.8 70.2 Instruction
115 65.9
120 62.1 63.8 63.8 64.3 Restart OGL
135 62.7 Screen Froze
150 62.1 64.3 64.8
180 63.2 65.4 64.8
210 63.8 65.4 65.9
240 64.3 65.9 65.9
270 64.3 66.4 65.9
300 64.3 66.4 65.9
330 64.8 66.4 66.4
360 64.8 67.0 66.4
390 65.4 67.0 67.0
420 64.8 68.1 67.0
450 65.4 67.0 67.5
480 64.8 68.6 67.0
510 65.4 68.1 67.0
540 65.9 68.1 68.1
570 65.9 68.1 67.5
600 65.9 68.6 68.1
630 66.4 68.6 68.6
660 66.4 69.1 68.1
690 66.4 68.6 68.1
720 66.4 69.1 68.1
750 65.9 69.1 68.1
780 66.4 69.1 68.1
810 67.0 69.1 68.1
840 66.4 69.7 68.1
870 67.0 69.1 68.6
900 67.0 69.1 69.1
930 60.0 64.3 65.4
960 56.8 59.5 59.5
990 55.1 57.3 57.3
1020 53.5 56.8 55.7
1050 53.0 55.7 55.7
|
Livermore Loops Stability Test
A long time ago, the Livermore Loops Benchmark produced wrong numeric results on an overclocked Pentium Pro CPU. A revised benchmark included a run time option to specify the nominal running time of each loop, an example of the 5 seconds per test parameter used here is shown below. With this, the start time of each section is logged and the results of every pass checked for correctness. Run time displays and reported performance are the same as before.
The stability test was run on the Pi at 700 MHz and overclocked 1000 MHz, at 5 seconds per test (see command format), or a total time of 6 minutes. CPU temperature was measured (see measure_temp command) at 30 second intervals. Results are provided below. Room temperature was 22.6°C. At 700 MHz temperature increased from 48.7 to 53.0°C and, higher at 1000 MHz, from 50.3 to 60.5°C.
See also Reliability Tests and
Raspberry Pi 2 Stress Tests.htm,
describing stress tests using multiple copies of this benchmark, along with graphics programs.
These include demontrations of failures and slow performance caused by overheating, using Raspberry Pi 2 and 3.
Command ./liverloopsPiA6 Secs 5 ##################################################### Livermore Loops Benchmark Opt 3 32 Bit via C/C++ Fri May 17 15:52:01 2013 Reliability test 5 seconds each loop x 24 x 3 Part 1 of 3 start at Fri May 17 15:52:01 2013 Part 2 of 3 start at Fri May 17 15:54:09 2013 Part 3 of 3 start at Fri May 17 15:56:24 2013 Numeric results were as expected ##################################################### |
64 Bit Reliability Tests
The two main CPU stress tests have been recompiled as stressintPi64 and burninfpuPi64 and are now included in Rpi3-64-Bit-Benchmarks.tar.gz, along with RPiHeatMHz64S and RPiHeatMHz64G , besides videogl64 and liverloopsPi64, the other appropriate programs.
The new CPU tests have already been run via OpenSUSE and SUSE LES, reported in SUSE RPi3 Stress Tests.htm. The purpose here is to demonstrate test results running via Gentoo and, at least with CPU stress tests, have been confirmed as producing similar effects via OpenSUSE. In this case, except for one example, the Raspberry Pi 3 was tested outside the case, showing far more CPU MHz throttling than when enclosed in the FLIRC case - see above. Rather than using a script file to run the programs, it was found more convenient to open four or five different terminal windows, initially copying the execution commands without starting the tests. Below are results for the following tests. All include the new RPiHeatMHz program, with a test duration of around 15 minutes.
Integer Arithmetic Stress Test - comprising four runs of stressintPi64 using 40 KB of data, aimed at all using L2 cache, with 12 tests each running for 80 seconds. Performance on all cores was essentially the same, with CPU throttling starting after 30 seconds, eventually reducing CPU MHz by nearly 32%, with maximum recorded sample CPU temperature of 84.4 °C. Compared with stand alone results, CPU performance was degraded to a greater extent due to MP overheads.
Reminder - This has six write/read and six read only tests, with different variations of data patterns. The read phase comprises an equal number of additions and subtractions, with the data being unchanged afterwards and checked for correctness. Speed is measured in MB/second. Results are displayed at 10 second intervals. Run time parameters are provided for KBytes memory used, seconds for each of the twelve tests and log number for use in multitasking.
Floating Point Arithmetic Stress Test - having four burninfpuPi64 test procedures, using L2 cache with 8 operations per data word. Again performance was effectively constant from all cores, with maximum total throughput of 13.7 GFLOPS, reducing by nearly 4 GFLOPS due to CPU throttling down to 843 MHz, again with a maximum temperature of 84.4 °C.
Reminder - This is based on MP-MFLOPS but to use a single CPU core, with the code rearranged to obtain a higher throughput. The arithmetic operations executed are of the form x[i] = (x[i] + a) * b - (x[i] + c) * d + (x[i] + e) * f with 2, 8 or 32 operations per input data word. The same variables are used for each word and final results are checked for consistency, any errors being reported. The benchmark has input parameters for KWords, Section 1, 2 or 3 (for 2, 8 or 32 operations per word) and log number (0 to 99).
Livermore Loops Stress Test - This uses four copies of the Livermore Loops Benchmark, running in the stress testing mode, with each of the 72 test kernels set to run for 12 seconds. Summary performance MfLOPS speeds are measured over all the tests but short term variations can be seen in RPiHeatMHz64 results, including inconsistent effects of different arithmetic functions. Maximum temperature recoded was 84.9 °C with a CPU MHz of 744.
Integer and OpenGL Stress Tests - The most complicated OpenGL kitchen test was run for 15 minutes, along with three Integer Stress Tests, the former being at a window size of 1024 x 768 pixels, to allow space to display other test’s ongoing results. The tests were run using on demand and performance MHz settings with the system board out of case. Then, performance was quite similar, with OpenGL FPS and integer MB/second reduced to around 60% of initial speeds. A maximum of 85.4 °C was recorded, with many more at 84.9 °C, when CPU MHz temporarily dropped to half speed at 600 MHz (at both on demand and performance settings). The tests were repeated with the system in the FLIRC case, producing consistent performance, whilst nearly reaching the temperature where CPU throttling would occur.
###########################################################
Integer Stress Test RPi 64
Commands from different terminals
./RPiHeatMHz64G passes 100 seconds 10
./stressintPi64 KB 40 Secs 80 Log 11
./stressintPi64 KB 40 Secs 80 Log 12
./stressintPi64 KB 40 Secs 80 Log 13
./stressintPi64 KB 40 Secs 80 Log 14
Log MB/Second
Secs 11 12 13 14 Av MHz °C MB/sec
/MHz
0 1200 54.8
10 1199 63.4
20 1199 74.1
30 1200 79.5
40 1074 81.7
50 1019 82.2
60 993 82.7
70 972 82.7
Wr/Rd 80 2225 2182 2167 2106 2170 946 82.7 2.29
160 1800 1806 1786 1791 1796 881 84.4 2.04
240 1704 1709 1704 1686 1701 828 84.4 2.05
320 1682 1684 1658 1676 1675 826 83.8 2.03
400 1672 1671 1655 1662 1665 826 84.4 2.02
480 1665 1666 1666 1656 1663 820 84.4 2.03
Read 560 1799 1831 1802 1816 1812 843 83.8 2.15
640 1761 1763 1748 1740 1753 852 83.8 2.06
720 1697 1698 1701 1694 1698 823 83.8 2.06
800 1688 1703 1683 1683 1689 830 83.8 2.04
880 1702 1705 1677 1690 1694 836 84.4 2.03
960 1695 1706 1720 1770 1723 824 84.4 2.09
1040 1197 60.1
Stand alone Write/Read 2530 1200 2.11
Stand alone Read 2870 1200 2.39
Min or Max 820 84.4
% of Max 68.3
###########################################################
Burn-In-FPU RPi 64 Using 40 KBytes, 8 Operations Per Word
Commands from different terminals
./RPiHeatMHz64G passes 100 seconds 10
./burninfpuPi64 Kwds 10 Sect 2 Mins 15 Log 51
./burninfpuPi64 Kwds 10 Sect 2 Mins 15 Log 52
./burninfpuPi64 Kwds 10 Sect 2 Mins 15 Log 53
./burninfpuPi64 Kwds 10 Sect 2 Mins 15 Log 54
Log MFLOPS
Secs 51 52 53 54 Av MHz °C MFLOPS
/MHz
0 1200 54.8
30 3416 3397 3462 3397 3418 1200 76.3 2.85
60 3154 3142 3042 3025 3091 1072 81.7 2.88
90 2917 2878 2862 2827 2871 982 82.7 2.92
120 2816 2765 2737 2753 2768 954 83.8 2.90
150 2615 2663 2605 2633 2629 934 83.8 2.81
180 2630 2583 2583 2616 2603 905 82.7 2.88
210 2613 2585 2607 2524 2582 901 83.8 2.87
240 2548 2566 2590 2506 2553 885 83.8 2.88
270 2586 2541 2508 2528 2541 874 83.8 2.91
300 2518 2496 2515 2517 2512 886 83.8 2.83
330 2545 2510 2515 2494 2516 867 83.8 2.90
360 2523 2490 2520 2513 2512 877 83.8 2.86
390 2444 2461 2512 2537 2489 869 83.8 2.86
420 2449 2482 2484 2535 2488 872 83.8 2.85
450 2526 2499 2470 2479 2494 885 83.8 2.82
480 2405 2378 2477 2360 2405 865 83.8 2.78
510 2474 2458 2510 2470 2478 884 83.8 2.80
540 2475 2435 2484 2484 2470 887 83.8 2.78
570 2506 2437 2434 2501 2470 877 83.8 2.82
600 2465 2494 2449 2479 2472 870 83.8 2.84
630 2487 2447 2500 2455 2472 877 83.8 2.82
660 2496 2479 2434 2442 2463 859 83.8 2.87
690 2480 2448 2435 2499 2466 882 84.4 2.80
720 2472 2471 2494 2412 2462 863 83.8 2.85
750 2462 2461 2516 2429 2467 871 83.8 2.83
780 2472 2467 2464 2427 2458 859 84.4 2.86
810 2472 2483 2471 2430 2464 845 83.8 2.92
840 2479 2444 2456 2494 2468 850 83.8 2.90
870 2471 2483 2469 2445 2467 860 83.8 2.87
900 2427 2490 2489 2450 2464 861 84.4 2.86
930 2460 2491 2434 2475 2465 850 83.8 2.90
960 2477 2494 2429 2486 2472 862 83.8 2.87
990 2490 2458 2455 2450 2463 843 83.8 2.92
1020 2433 2474 2458 2468 2458 888 84.4 2.77
1050 2522 2500 2526 2540 2522 864 83.8 2.92
Stand Alone 3570 1200 2.98
Min or Max 843 84.4
% of Max 70.3
###########################################################
Livermore Loops Stress Test 64 Bit 24x3x12 = 864 seconds
Commands from different terminals
./RPiHeatMHz64G passes 100 seconds 10
./liverloopsPi64 Seconds 12
./liverloopsPi64 Seconds 12
./liverloopsPi64 Seconds 12
./liverloopsPi64 Seconds 12
Overall Ratings
Maximum Average Geomean Harmean Minimum
570.2 218.4 193.9 171.1 69.4
591.3 221.2 196.3 173.0 72.4
576.4 218.1 194.1 171.6 72.4
572.5 219.9 194.8 171.2 67.6
One Program - 72 seconds
623.9 275.9 246.1 217.8 98.6
83 measurements of 10+ seconds
MHz °C MHz °C MHz °C
1200 51.5 1011 82.7 931 83.3
1200 59.1 1019 82.7 828 83.8
1200 67.7 945 82.7 928 82.7
1200 72.0 1025 82.2 843 84.9
1199 79.5 913 83.8 744 84.9
967 82.7 842 83.8 800 84.4
1043 82.2 840 84.4 916 83.3
1195 80.6 891 82.7 896 83.8
1193 80.6 829 83.8 918 83.8
1117 81.7 818 83.8 951 82.2
1138 81.7 873 83.3 1024 81.7
1173 80.6 996 82.7 1023 82.2
1200 80.6 963 82.7 924 82.7
1148 81.7 994 82.7 892 83.8
1059 81.7 1001 83.3 883 83.8
1031 82.2 971 82.7 895 83.8
1002 82.7 947 83.8 1006 82.7
926 83.3 883 83.8 940 82.7
1022 82.7 976 82.7 931 82.7
973 82.7 936 83.3 949 83.3
1079 82.2 993 82.2 933 83.3
1028 82.7 943 83.3 995 82.7
998 82.7 941 83.8 1071 81.7
1019 82.2 927 83.3 941 83.3
995 82.7 1043 81.7 1145 81.1
1097 82.2 1058 82.2 1008 82.7
965 82.7 980 82.7 1193 75.2
1122 82.2 1016 82.7
Min Max Min Max Min Max
926 83.3 818 84.4 744 84.9
% of Max 62.0
###################################################################################
Integer and OpenGL Stress Tests
Commands from different terminals
1 ./RPiHeatMHz64G passes 100 seconds 10
2 export vblank_mode=0
./videogl64 Wide 1024, High 768, Minutes 15 Test 6
3 ./stressintPi64 KB 8 Secs 80 Log 31
4 ./stressintPi64 KB 8 Secs 80 Log 32
5 ./stressintPi64 KB 8 Secs 80 Log 33
On demand out of case Performance out of case Performance FLIRC case
Total Total Total
Secs MB/s FPS MHz °C MB/s FPS MHz °C MB/s FPS MHz °C
0 1200 52.1 1200 55.8 1200 44.0
30 13 1200 78.4 13 1107 80.6 13 1200 60.1
60 11 953 82.7 11 910 82.7 13 1199 63.4
80 6206 10 890 82.7 6064 9 850 83.8 7116 13 1200 65.0
160 4861 9 804 83.8 4656 9 744 84.9 7041 13 1199 68.8
240 4414 8 743 84.9 4305 8 600 82.7 7072 13 1200 70.9
320 4211 8 706 84.9 4217 8 600 82.7 7075 13 1200 72.0
400 4163 8 716 84.9 4209 8 738 84.9 7095 13 1200 74.1
480 4132 8 600 82.7 4209 8 600 82.7 7081 13 1200 75.8
560 4858 8 737 85.4 4802 8 738 84.9 8067 13 1200 74.7
640 4720 8 721 84.9 4768 8 722 84.9 8092 13 1200 76.8
720 4662 8 899 83.3 4730 8 743 84.9 7989 13 1200 77.4
800 4624 8 764 84.9 4664 8 823 84.9 8050 13 1200 78.4
880 4638 8 875 83.8 4712 8 719 84.9 7984 13 1200 79.5
960 5874 8 1015 82.7 5917 8 938 82.7 8344 13 1200 74.1
|
Performance Monitor
JavaDraw - following show JavaDraw benchmark speeds, at 10 seconds per test, and simultaneous vmstat performance monitor CPU utilisation, with 5 second samples. The normal tests were run, then again, with an affinity setting to use 1 CPU core.
When running a CPU benchmark, %user time is recorded as 25%, as most of the single core test, with a little system overhead. For some reason, JavaDraw seemed to use more than one core for the last two tests. Overall, the details show that Raspberry Pi 2 can use more than one CPU core to improve performance on drawing with a Java program.
Raspberry Pi 3 results are also shown. For full speed, the GLUT driver, required to run the new OpenGL GLUT benchmark, has to be disabled. Again two cores are used for best performance.
Normal Affinity 1 CPU
FPS %usr %sys FPS %usr %sys
Bitmap Twice Pass 1 45.0 43 9 22.1 22 4
43 8 23 6
Bitmap Twice Pass 2 56.8 42 9 35.8 23 6
41 10 24 6
Plus 2 Circles 57.8 41 9 35.4 24 6
44 8 25 5
Plus 200 Rand Circles 54.9 43 8 36.0 25 5
43 7 23 7
Plus 320 Long Lines 38.3 42 8 33.4 33 5
42 9 32 6
Plus 4000 Rand Circles 25.1 48 9 22.4 38 5
48 9
vmstat command for 20 5 second samples - vmstat 5 20 > vmstatlog1.txt
benchmark commands - java JavaDrawPC and taskset 0x00000001 java JavaDrawPC
########################### Raspberry Pi 3 ###########################
Bitmap Twice Pass 1 76.7 42 10 47.0 26 7
43 10 26 9
Bitmap Twice Pass 2 97.5 40 13 67.1 26 10
42 11 25 10
Plus 2 Circles 97.4 40 11 56.9 23 6
40 10 25 8
Plus 200 Rand Circles 90.8 40 10 58.6 26 8
40 10 27 8
Plus 320 Long Lines 62.4 39 10 60.0 30 8
40 10 32 7
Plus 4000 Rand Circles 42.8 46 11 36.4 24 8
44 10 24 6
|
Assembly Code
Linpack benchmark performance is completely dependent on the daxpy function with a linked triad dy[i] = dy[i] + da * dx[i], with an unrolled to loop containing four linked add and multiply statements. Compilers can produce a range of instruction combinations, to cover a number of different accesses to the function. The following seem to be the most likely frequent instructions executed. The linpackPiA7SP compilation has instructions the same as linpackPiA7, except using 32 bit registers, example vfma.f32 s14, s0, s13, maybe executing at the same speed as the 64 bit vfma instruction.
Instruction fmacd is double precision multiply-accumulate and vfma is fused floating-point multiply accumulate, where the result of the multiply is not rounded before the accumulation, and might be the reason for different numeric answers. If true to form, FMA can produce a maximum of two results per CPU clock cycle, doubling performance.
Next are details of assembly code for BusSpeed reading all data, where RAM speed from the original PiA6 benchmark is at half the expected speed, and slower than reading every other word. The benchmark test loop has 64 AND statements, read sequentially. The only difference appears to be that gcc 4.8, for PiA7, produces negative indexing.
|
Roy Longbottom May 2017
The Official Internet Home for my Benchmarks is via the link
Roy Longbottom's PC Benchmark Collection