
 Roy Longbottom's Android NEON
Roy Longbottom's Android NEON
Benchmark Apps
For latest results see
Android Benchmarks For 32 Bit and 64 Bit CPUs from ARM, Intel and MIPS.
|
|
For latest results see
Android Benchmarks For 32 Bit and 64 Bit CPUs from ARM, Intel and MIPS.
|
|
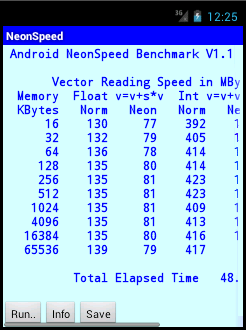
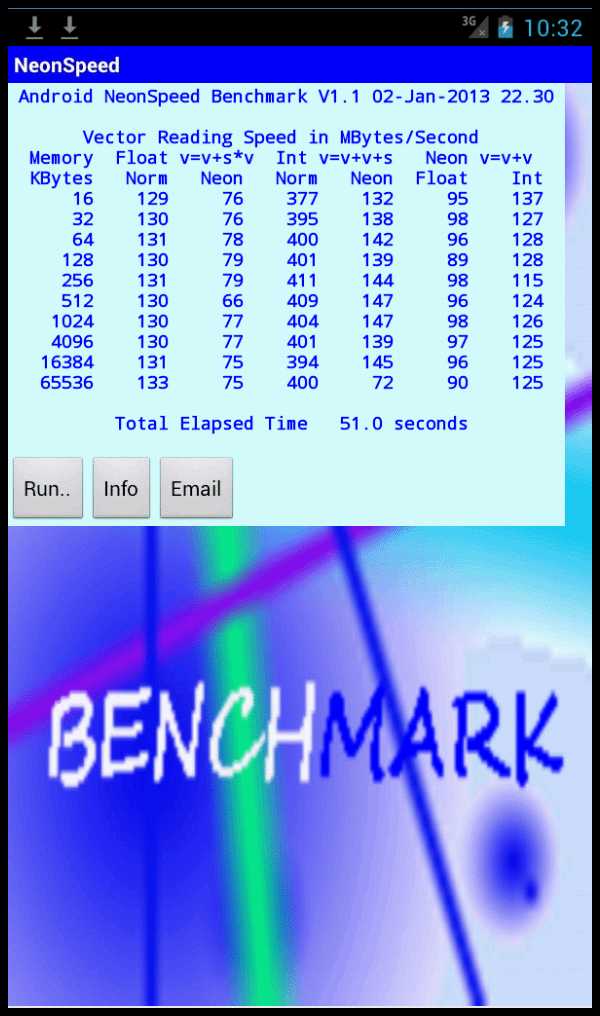
NeonSpeed ResultsUsing the particular instruction sequences, NEON can provide a floating point performance gain approaching three times, using data from L1 cache, and twice via L2. Integer performance using NEON provides a lesser gain and few gains are identified using data from RAM. The v=v+s*v calculations are the same that determine the Linpack Benchmark single precision score. For example, the Nexus 7 SP result was 201 MFLOPS. Maximum L1 cache results here, without/with NEON, are 238 and 644 MFLOPS (950/4 and 2575/4) but Linpack can be influenced by the lower L2 cache speeds. As with other benchmarks tablet T7 and T4 cache speeds are similar and, compared with P11, lower than might be expected. Results can be compared with Sngl (Normal Float) and SSE columns in SSE3DNow Benchmark Results On PCs. August 2013 - Comparing the new Cortex-A15 in Tablet T11 results with those for the older Cortex-A9 in Phone P11, shows that the new processor is much faster executing normal and NEON floating point instructions. Adjusting for the same CPU MHz, the A15 is at least three times faster, using cached based data. Similar ratios apply to NEON integer tests. T11 was also run with Power Saving option On, when the CPU runs at 1000 MHz. Note the full speed version appears to kick off at 1000 MHz. February 2015 - Atom system A1 is much faster than Cortex-A9 based devices, taking into account CPU MHz, but the Cortex-A15 averages 85% faster from cached based data. The Atom has a 64 bits memory bus width, compared with 32 bits for ARM processors. This leads to the Atom being over 70% faster, using calculations with RAM data. The native Intel code, on the Atom, produced some performance gains, mainly using L1 cache based data, but speed in other areas is probably limited by data flow. The later compiler produced some slower speeds on ARM base tablet T11 and better/worse variations on T21. August 2015 - Results provided for T22 with Cortex-A53 64 bit CPU and 64 bit Android 5.0. As with NEON-Linpack, many results from 32 bit and 64 bit compilations, via NEON intrinsic functions, were similar. With normal code, the 64 bit compilations were up to near four times faster than those at 32 bits. October 2015 - T7 Nexus 7, Android 5.0.2 upgrade, slightly slower but back to normal with 5.1.1, also ARM/Intel version now same as older program (not shown).
T22 Android 5.0.2 to 5.1 (ARM-v8 CPU) produced performance gains of around 3%, on the 32 bit benchmark and on most cache based tests at 64 bits, with no gain using RAM data (see below).
|
Android NEON-MFLOPS-MP Benchmark V1.0 20-Dec-2012 16.57
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 532 402 124 1135 1044 960
2T 1255 798 213 2041 1987 1916
4T 2441 1553 229 4185 4034 3450
8T 1922 2403 226 3774 3996 3346
Results x 100000, 12345 indicates ERRORS
1T 86735 98519 99984 79897 97638 99975
2T 86735 98519 99984 79897 97638 99975
4T 86735 98519 99984 79897 97638 99975
8T 86735 98519 99984 79897 97638 99975
Total Elapsed Time 4.5 seconds
System Information - as NeonSpeed
|
Using 2 operations per word from 12.8 KB and 128 KB (L1 and L2 caches), performance can increase in line with the number of cores, but from 12.8 MB, is more limited by RAM speed. With 32 operations per word, performance is limited by CPU speed, with throughput increasing in line with the number of cores for all input data sizes.
Maximum 32 Ops/Word speeds from the original compiled version of MP-MFLOPS have been added to the results below. NEON performance gains are up to 80%. As with other multitasking benchmarks, P11 seems to be reluctant to use all cores with four threads. The first T1 test on this system was also slower than could be expected (should be >700).
August 2013 - Again for new Cortex-A15 versus Cortex-A9 shows that the former has a much better MFLOPS/MHz ratio. This benchmark was also run using the 1000 MHz Power saving mode, where many of the results were similar to the original. The benchmark was modified to run each test ten times longer. This produced some faster speeds (see below) but CPU clock frequency measurements indicated that it was still running at 1000 MHz for a lot of the time. Behaviour was similar to the non-NEON version .
February 2015 - Results for Atom system A1 suffer from the Intel to ARM instruction mapping, on the CPU speed limited tests at 32 operations per word. The native Intel code produced limited gains at two operations per word but was more than twice as fast on the CPU speed limited tests.
A revised version, with extended running time, is available via Android Long MP Benchmarks.htm.
To maintain compatibility with other versions of these tests, NEON intrinsic functions vaddq_f32, vmulq_f32 and vsubq_f32 were used. These operate on four floating point numbers at a time but are potentially not as fast as using vmlaq_f32, the linked add and multiply function (used in NeonSpeed). The 32 Ops tests also resort to repetitively loading the same constants from memory (L1 cache?), probably due to an insufficient number of registers and this might reduce data flow speed.
August 2015 - T22 NEON 64 bit compilation produced a small performance gain over 32 bit results, at 2 operations per word, but near double speed at 32 operations, the former suffering from fewer registers for the variables. Using one core, maximum speed was 2.77 GFLOPS, rising to 10.8 GFLOPS via four cores (best so far relative to CPU GHz).
September 2015 - New best score from P33, with 2 GHz Qualcomm Snapdragon 810, (Cortex-A57) and Android 5.0.2, at 64 bits. Performance, with 8 threads, is up to 23.6 GFLOPS, and up to nearly 3.5 results per clock cycle, using one core.
October 2015 - T7 Nexus 7, Android 5.0.2 then up tp 5.1.1 upgrades produced similar speeds (not shown).
Except with 8 threads using the 64 bit version, T22 Android 5.0.2 to 5.1 (ARM-v8 CPU) produced performance gains, mainly of more than 3% (see below).
*****************************************************
A1 Quad Core 1.86 GHz Intel Atom Z3745, Android 4.4
Dual Channel LPDDR3-1066 Bandwidth 17.1 GB/s
Android NEON-MFLOPS-MP Benchmark V1.1 07-Feb-2015 18.37
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 1110 1319 878 1188 1139 1226
2T 2470 2114 996 2406 2427 2390
4T 3159 2211 988 4148 3487 4006
8T 2066 2486 1003 4144 3944 4077
Total Elapsed Time 3.6 seconds
Longer Tests
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 1796 1520 1025 1231 1228 1227 573
2T 3354 2959 1047 2427 2445 2445 1115
4T 4627 5508 978 4690 4791 4733 2258
8T 3861 6307 1030 4611 4869 4742 2217
Total Elapsed Time 88.3 seconds
#################### A1 ARM-Intel ######################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.1 13-May-2015 12.17
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 2151 1962 1064 2619 2694 2650 1055
2T 4421 3849 1048 5296 5463 5343 2102
4T 5886 6652 982 9592 10735 10362 4145
8T 3744 7284 1018 9085 10791 9493 4110
Total Elapsed Time 13.8 seconds
*****************************************************
T11 Samsung EXYNOS 5250 2.0 GHz Cortex-A15, Android 4.2.2
Android NEON-MFLOPS-MP Benchmark V1.1 13-Sep-2013 13.44
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 1878 1433 616 2556 3078 2893 1481
2T 3672 2720 673 5789 5903 6451 2992
4T 4833 4606 690 6578 7680 5135 3134
8T 4019 4474 676 6607 7685 7256 2796
Total Elapsed Time 1.9 seconds
Measured CPU MHz - 1700
Power Saving Mode - 1000 MHz
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 1907 1024 619 2484 2326 2357
2T 3664 2734 652 4871 4769 4609
4T 3342 3125 656 4768 4855 4482
8T 3121 3228 667 4763 4902 4582
Total Elapsed Time 2.4 seconds
Longer Tests - 10 Times
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 1847 1415 597 3772 4096 3545
2T 3649 3309 664 8065 7966 7505
4T 3670 3922 658 7753 8148 7490
8T 5664 5570 681 8092 8355 7672
Total Elapsed Time 13.0 seconds
#################### T11 ARM-Intel ####################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.1 13-May-2015 12.07
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 1965 1630 582 3792 4077 3521 1537
2T 3789 2690 663 8497 8133 7297 3151
4T 5714 4883 654 8364 8192 7554 3095
8T 5414 6316 673 7976 8437 6635 3125
Total Elapsed Time 13.0 seconds
*****************************************************
T21 Qualcomm Snapdragon 800 2150 MHz, Android 4.4.4
Dual Channel 32 Bit LPDDR3-1866 RAM 14.9 GB/s
Android NEON-MFLOPS-MP Benchmark V1.1 27-Jul-2015 11.45
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 556 1224 784 2695 2567 2872 1245
2T 3655 3655 1361 5563 5590 5560 2426
4T 5731 5107 1252 5357 6045 6350 4165
8T 6757 5485 1419 7220 7846 8601 4885
Total Elapsed Time 1.8 seconds
Longer Tests
Android NEON-MFLOPS2-MP Benchmark V2.1 25-Jul-2015 18.44
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 2757 2576 771 2808 2825 2800
2T 5662 5525 1516 5631 5664 5570
4T 6550 7846 1945 11167 11281 10939
8T 10273 10928 1981 10851 11211 11350
Total Elapsed Time 40.0 seconds
##################### P33 64 Bit #####################
P33 Quad-core 2 GHz Qualcomm Snapdragon 810, Android 5.0.2
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.2 16-Sep-2015 17.59
Compiled for 64 bit ARM v8a
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 2811 3126 1089 6943 6589 6342
2T 2488 4114 1541 12084 10559 8809
4T 4759 5480 2038 16516 14826 11960
8T 4840 8985 2452 22082 23563 12461
Total Elapsed Time 7.6 seconds
#################### T21 ARM-Intel ####################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.1 28-Jun-2015 16.32
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 3049 2857 622 2923 2874 2098 1232
2T 5508 4887 1009 5477 5736 4349 2463
4T 5643 5282 1410 11244 11601 8564 4900
8T 9294 11156 1681 11288 11605 8946 4880
Total Elapsed Time 14.0 seconds
###################### T22 32 Bit ######################
T22, Quad Core ARM Cortex-A53 1300 MHz, Android 5.0.2
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.2 13-Aug-2015 16.35
Compiled for 32 bit ARM v7a
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 619 613 575 1444 1446 1426 672
2T 1174 1206 889 2894 2902 2839 1345
4T 1585 1616 901 5679 5726 5596 2669
8T 2075 2130 944 5400 5585 5519 2672
Total Elapsed Time 25.8 seconds
################ T22 Android 5.1 32 Bit ################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.2 28-Sep-2015 21.22
Compiled for 32 bit ARM v7a
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 638 628 593 1501 1498 1475
2T 1256 1257 901 2957 2998 2953
4T 1670 2246 941 5676 5837 5853
8T 2221 2275 1019 5718 5699 5710
Total Elapsed Time 24.9 seconds
###################### T22 64 Bit ######################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.2 13-Aug-2015 16.38
Compiled for 64 bit ARM v8a
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 726 745 647 2766 2774 2639 1398
2T 1397 1402 903 5523 5552 5371 2797
4T 1871 1930 898 10780 10479 10439 5546
8T 2496 2876 1011 9736 10679 9900 5500
Total Elapsed Time 15.1 seconds
################ T22 Android 5.1 64 Bit ################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.2 28-Sep-2015 22.26
Compiled for 64 bit ARM v8a
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 786 780 702 2849 2868 2742
2T 1496 1542 943 5693 5682 5629
4T 1919 2065 995 10622 10687 10122
8T 2494 2691 997 10187 10793 10123
Total Elapsed Time 14.6 seconds
*****************************************************
T23 Dual Core 1.6 GHz Intel Atom Z2560, Android 4.2
Android NEON-MFLOPS-MP Benchmark V1.1 11-Aug-2015 22.06
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 268 286 293 868 800 893
2T 432 459 546 1398 1708 1354
4T 619 678 542 1779 2183 2117
8T 600 583 567 2108 2515 2185
Total Elapsed Time 6.4 seconds
*****************************************************
P30 Quad Core 1.9 GHz Qualcomm Snapdragon 600, Android 4.4.2
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 1237 1096 514 1885 2223 2434
2T 3679 2304 1151 3344 2890 4159
4T 4599 3898 1205 5475 6692 6702
8T 3187 4877 1081 5626 5909 5805
Total Elapsed Time 2,6 seconds
*****************************************************
P11 Galaxy SIII, Quad Cortex-A9 1.4 GHz, Android 4.0.4
Android NEON-MFLOPS-MP Benchmark V1.0 23-Dec-2012 14.33
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 343 404 312 1194 1125 1172 675
2T 1456 939 357 2317 2387 2151 1342
4T 1899 1712 304 2946 3042 2828 1824
8T 2037 2158 513 3517 3395 3420 2666
Total Elapsed Time 4.0 seconds
*****************************************************
T7 Nexus 7 Quad 1300 MHz Cortex-A9, Android 4.1.2
Android NEON-MFLOPS-MP Benchmark V1.0 20-Dec-2012 16.57
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 532 402 124 1135 1044 960 643
2T 1255 798 213 2041 1987 1916 1193
4T 2441 1553 229 4185 4034 3450 2374
8T 1922 2403 226 3774 3996 3346 2385
Total Elapsed Time 4.5 seconds
Measured CPU MHz - 1200
#################### T7 ARM-Intel #####################
ARM/Intel NEON-MFLOPS2-MP Benchmark V2.1 13-May-2015 12.24
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 657 407 132 1077 1074 1053
2T 1265 817 222 2147 2150 2078
4T 2024 1695 234 4214 4276 3555
8T 2435 2495 234 4196 4100 3523
Total Elapsed Time 39.0 seconds
*****************************************************
T10 Samsung Galaxy Note GT-N7000 Dual core 1.4 GHz Cortex-A9
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 267 317 253 1111 1194 1111
2T 726 580 227 1550 2313 2154
4T 1437 1312 312 2322 2369 2171
8T 1403 1352 330 2393 2320 2037
Total Elapsed Time 5,0 seconds
*****************************************************
T4 Miumiu w17 Pro 7 inch tablet, dual 1500 MHz Cortex-A9
Android NEON-MFLOPS-MP Benchmark V1.0 20-Dec-2012 17.03
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 596 390 115 1045 1057 931 588
2T 1145 787 161 2009 1878 1858 1117
4T 1130 1033 165 2016 2036 1902 1144
8T 1171 1189 165 2018 2049 1879 1141
Total Elapsed Time 5.8 seconds
Measured CPU MHz - 1200
*****************************************************
T2 WayTeq xTAB-70 7 inch tablet, 800 MHz Cortex-A9
Android NEON-MFLOPS-MP Benchmark V1.0 20-Dec-2012 17.03
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800 Original
MFLOPS
1T 367 172 57 643 640 622 393
2T 405 290 64 643 648 643 395
4T 399 380 66 657 671 653 390
8T 390 399 62 650 679 646 392
Total Elapsed Time 13.2 seconds
*****************************************************
ET1 Device ARM Emulator 2.4 GHz Core 2 Duo
FPU Add & Multiply using 1, 2, 4 and 8 Threads
2 Ops/Word 32 Ops/Word
KB 12.8 128 12800 12.8 128 12800
MFLOPS
1T 24 24 24 38 38 37
2T 24 24 24 36 37 37
4T 24 21 24 37 38 37
8T 24 24 24 37 37 37
Total Elapsed Time 179.6 seconds
|
 NEON-Linpack
NEON-LinpackThe Linpack Benchmark was produced from the "LINPACK" package of linear algebra routines. It became the primary benchmark for scientific applications, particularly under Unix, from the mid 1980's, with a slant towards supercomputer performance. The benchmark operates on 100x100 matrices. Performance is governed by an inner loop in function daxpy() with a linked triad dy[i] = dy[i] + da * dx[i], and is measured in Millions of Floating Point Operations Per Second (MFLOPS). Various double precision versions and a single precision variety are available from Android Benchmarks.htm.
This version replaces the the main daxpy calculations with NEON functions. See Program Code Used below. This has a NEON define, besides UNROLL, that it replaces. Two other UNROLL areas were duplicated with NEON defines. The numeric results, as shown below, are identical to those for the non-NEON single precision version.
As indicated above,
the benchmarks were recompiled to use both Intel and ARM processors. The ARM variety produced the same numeric results as the first below, but the Intel answers, now included, are different, probably a rounding complication. It was a complete surprise to discover that ARM intrinsic functions were converted to Intel SIMD SSE instructions, with significant performance improvement on an Atom based tablet
(see #I below and assembly code here).
Android NEON Linpack Benchmark 15-Jan-2013 12.24 Speed 382.46 MFLOPS norm. resid 1.6 resid 3.80277634e-05 machep 1.19209290e-07 x[0]-1 -1.38282776e-05 x[n-1]-1 -7.51018524e-06 System Information - as NeonSpeed ######################################################## ARM/Intel NEON Linpack Benchmark V 1.003-May-2015 11.50 Speed 900.17 MFLOPS norm. resid 1.7 resid 4.00543213e-05 machep 1.19209290e-07 x[0]-1 -1.38282776e-05 x[n-1]-1 -7.51018524e-06 |
Results from other versions are included below. Performance gains through using NEON functions is between 87% and 98%. See also Linpack Results.htm.
August 2013 - Tablet T11, with the Cortex-A15 CPU, runs at 2.5 times the speed of an A9 processor of the same MHz (if one existed).
February 2015 - Tablet A1 with Intel Atom, ARM code being converted via an Android compatibility layer, called Houdini, that maps ARM instructions into X86 instructions, but not Java that is fast.
May 2015 - The new ARM/Intel version produced significantly improved performance on the Intel Atom based tablet, surprisingly using native SSE instructions, but tablets with ARM processors produced little change see #I. Further details can be found in Android Native ARM-Intel Benchmarks.htm).
July 2015 - T21, with the 2150 MHz Qualcomm Snapdragon 800, is not quite as fast as T11, with a Cortex-A15 running at 1700 MHz.
August 2015 - T22 NEON Linpackresults from 32 bit and 64 bit compilations were similar, as the programs use a limited number of identical intrinsic functions.
September 2015 - New best score from P33, with 2 GHz Qualcomm Snapdragon 810, (Cortex-A57) and Android 5.0.2, with SP speed of 1277 MFLOPS at 64 bits.
October 2015 - T7 Nexus 7, Android 5.0.2, then up to 5.1.1, upgrades produced similar speeds (not shown).
T22 Android 5.0.2 to 5.1 (ARM-v8 CPU), as with the other Linpack benchmark speeds, NEON version results were a little faster, average around 3% (see below).
System ARM MHz Android Linpackv5 Linpackv7 LinpackSP NEONLinpack LinpackJava See MFLOPS MFLOPS MFLOPS MFLOPS MFLOPS T2 v7-A9 800 2.3.4 10.56 101.39 129.05 255.77 33.36 T4 v7-A9 1500a 4.0.3 16.86 155.52 204.61 382.46 56.89 T7 v7-A9 1300a 4.1.2 17.08 151.05 201.30 376.00 56.44 T7 #I v7-A9 1300a 4.1.2 159.34 199.84 346.78 P11 v7-A9 1400 4.0.4 19.89 184.44 235.54 454.21 56.99 P30 QU-600 1900 4.4.2 1027.49 T11 v7-A15 2000b 4.2.2 28.82 459.17 803.04 1334.90 143.06 T11#I v7-A15 2000b 4.2.2 826.36 952.88 1411.86 A1 Z3745 1866 4.4.2 59.39 168.16 296.63 443.42 252.49 A1 #I Z3745 1866 4.4.2 362.63 408.87 900.17 T21 QU-800 2150 4.4.3 35.39 389.52 751.95 1250.14 340.44 T21#I QU-800 2150 4.4.3 629.92 790.83 1325.00 P33 QU-810 2000 5.0.2 1446.42 T22#I v8-A53 1300 5.0.2 21.44 172.28 180.64 407.08 86.09 T22#I v8-A53 1300 5.1 178.04 187.03 421.86 91.28 64 Bit Version T22#I v8-A53 1300 5.0.2 338.00 479.69 505.12 T22#I v8-A53 1300 5.1 347.55 492.78 520.79 P33 QU-810 2000 5.0.2 1277.76 Measured MHz a 1200, b 1700, Z3745 = Intel Atom, QU = Qualcomm CPU, #I ARM/Intel Version |
 NEON-Linpack-MP
NEON-Linpack-MPThis version uses mainly the same C programming code as the single precision floating point NEON compilation above. It is run run on 100x100, 500x500 and 1000x1000 matrices using 0, 1, 2 and 4 separate threads. The 0 thread procedures are identical to above and MFLOPS speeds should be the same, subject to reasonable variations.
The code differences were slight changes to allow a higher level of parallelism. The initial 100x100 Linpack benchmark is only of use for measuring performance of single processor systems. The one for shared memory multiple processor systems is a 1000x1000 variety. The programming code for this is the same as 100x100, except users are allowed to use their own linear equation solver.
Unlike the NEON MP MFLOPS benchmark, that carries out the same multiply/add calculations, this program can run much slower using multiple threads. This is due to the overhead of creating and closing threads too frequently. At 100x100, around 0.67 million floating point calculations are executed in daxpy, the critical function. With the present equations, threads have to be created 99 times (unless someone can do better and change more things). At 100x100, data size is 40 KB, with L2 cache coming into play. With larger matrices, performance becomes more dependent on RAM, but multi-threading overheads have less influence.
This benchmark can execute the required functions multiple times and the last pass is used to determine numerical results. Those displayed are for the unthreaded pass but these are compared with threaded results to show that the same instructions are calculated. A message is displayed in the event of comparison failures.
Android Linpack NEON SP MP Benchmark 31-Jan-2013 12.14
MFLOPS 0 to 4 Threads, N 100, 500, 1000
Threads None 1 2 4
N 100 413.47 45.95 48.22 48.34
N 500 253.08 187.51 189.69 189.94
N 1000 148.76 135.49 136.08 136.17
NR=norm resid RE=resid MA=machep X0=x[0]-1 XN=x[n-1]-1
N 100 500 1000
NR 1.60 3.96 11.32
RE 3.80277634e-05 4.72068787e-04 2.70068645e-03
MA 1.19209290e-07 1.19209290e-07 1.19209290e-07
X0 -1.38282776e-05 5.26905060e-05 1.62243843e-04
XN -7.51018524e-06 3.26633453e-05 -6.65783882e-05
Thread
0 - 4 Same Results Same Results Same Results
Total Elapsed Time 54.196 seconds
System Information - as NeonSpeed
|
Below are additional timing details, in terms of microseconds per pass, for tests on Tablet T7. The number of floating point operations per pass, as specified, is 2 x (n x n x n) / 3 + 2 x (n x n) and the timings can be derived from MFLOPs, using this constant. A surprise is that the overheads are fairly constant and not influenced by the number of threads used. Thread processing is used approximately n times and microseconds per pass is sometimes proportional to n, but can increase due to using a slower higher level cache or RAM.
With these high overheads, there can be no improvements in performance using multiple cores. With faster hardware and lower overheads, the benchmark can produce gains, as shown below for the same program compiled to run on 64-Bit Linux. This uses Intel SSE instructions where four adds or multiplies can be executed simultaneously.
Minimum overheads for processing threads for this ARM CPU, at N=100, are (592 - 6)/100 = 56.6 microseconds. That for the two desktop processors is around 20 microseconds.
1.3 GHz Quad Core ARM Cortex-A9
Threads None 1 2 4 None 1 2 4
------------ MFLOPS ----------- ----- Microseconds Per Pass ----
N
10 145.30 0.87 0.84 0.92 6 992 1025 937
20 224.08 2.88 2.85 3.03 27 2132 2152 2025
40 316.61 10.64 10.38 11.21 145 4310 4417 4093
50 350.79 17.76 16.75 17.82 252 4972 5273 4957
100 413.47 45.95 48.22 48.34 1661 14944 14240 14205
500 253.08 187.51 189.69 189.94 331252 447087 441949 441367
1000 148.76 135.49 136.08 136.17 4494936 4935174 4913776 4910529
2.4 GHz Core 2 Duo
100 1666.02 287.94 200.82 134.17 412 2385 3419 5118
500 1908.89 1422.59 1902.42 1507.04 43917 58930 44067 55628
1000 1921.33 1624.31 2606.09 2306.14 348023 411662 256579 289951
3.0 GHz Quad Core Phenom II
100 1924.69 279.90 206.19 141.13 357 2453 3330 4865
500 2059.73 1333.07 1510.81 1247.76 40701 62887 55489 67187
1000 2074.59 1682.34 2314.57 2478.78 322313 397462 288895 269756
|
P11 is said to have a revised version of the Cortex-A9 CPU, with wider internal busses and dual channel memory. This is probably responsible for better performance at N = 500 and 1000.
August 2013 - Tablet T11, with the Cortex-A15 CPU, continues to show significant performance gains, compared with an A9 processor of the same MHz, when multiple threads are not used and the data array size is increased. As with other MP-NEON benchmarks, the program was run using the 1000 MHz Power Saving setting, confirming that the original was running at this frequency for the multithreading tests.
February 2015 - Best results, at this time, were for T15, with the Qualcomm Snapdragon S4. Atom system A1 is not that good, except memory based speed, at threadless N=1000, is better than the other ARM results. The new ARM/Intel version again demonstrated a doubling of measured MFLOPS on the Atom, using the smaller matrices.
July 2015 - T21, with the Qualcomm Snapdragon 800, obtains significantly fastest results, at unthreaded N = 500.
August 2015 - T22 results from 32 bit and 64 bit compilations were again similar, due to the programs use a limited number of identical intrinsic functions.
October 2015 - T7 Nexus 7, Android 5.0.2, then up to 5.1.1 upgrades produced similar speeds (not shown).
T22 Android 5.0.2 to 5.1 (ARM-v8 CPU) is shown to produce performance gains on all tests.
-------------------------------------------------------
MFLOPS 0 to 4 Threads, N 100, 500, 1000
A1 Quad Core 1.86 GHz Intel Atom Z3745, Android 4.4
Dual Channel LPDDR3-1066 Bandwidth 17.1 GB/s
Threads None 1 2 4
N 100 452.39 21.00 23.48 17.48
N 500 663.38 275.56 88.66 312.71
N 1000 617.04 380.60 191.26 195.61
Total Elapsed Time 63.747 seconds
#################### A1 ARM-Intel ######################
ARM/Intel Linpack NEON SP MP Benchmark 14-May-2015 13.58
Threads None 1 2 4
N 100 971.71 37.72 36.36 39.66
N 500 1311.37 488.73 487.85 488.98
N 1000 945.97 727.85 737.95 742.34
Total Elapsed Time 59.966 seconds
-------------------------------------------------------
T15 Qualcomm Snapdragon S4 2265 MHz?, Android 4.4
Threads None 1 2 4
N 100 1478.99 85.77 87.02 85.55
N 500 1426.67 730.69 726.84 731.90
N 1000 754.87 640.59 641.40 629.42
Total Elapsed Time 35.982 seconds
-------------------------------------------------------
T11 Samsung EXYNOS 5250 2.0 GHz Cortex-A15, Android 4.2.2
Threads None 1 2 4
N 100 1399.82 54.86 55.31 54.66
N 500 1154.21 434.16 434.06 436.97
N 1000 571.26 482.57 487.25 485.80
Total Elapsed Time 46.226 seconds
Expected CPU MHz - 1700
|
Android.mk file details to include NEON Intrinsics is shown below, on the right, and under that is the main loop in the function that uses the intrinsics to calculate x[i] = x[i] + c * y[i] (for NeonSpeed). In this case, starting with vld1q_f32 to load four single precision floating point numbers to 2 x 64 bit vector registers (four words as Intel SSE). The vmla vector multiply accumulate instruction executes the linked multiply and add function. The non-NEON test includes four loop increments (i to i+3) for 4 loads from each array and increasing this for more loads made little difference in performance. With NEON, four increments means one vld1q for each array. To provide somewhat better performance, four loads are used with 16 word increments.
Slight changes of the Android.mk file are required to produce an assembly instruction listing, as on the left below. The listing shows a one for one conversion of the intrinsics, with one of each extra add, compare and branch instructions for loop control. The compiler also appears to attempt optimisation by overlapping scalar adds with vector instructions.
Numerous intrinsics are available and identified in Summary of NEON intrinsics.
The compiler used with Eclipse does not carry out automatic vectorisation, but the powerful assembly level intrinsics might mean that this is not very important. Automatic vectorisation is available in the GNU ARM toolchain under Linux package, but it does not appear possible to (easily?) convert the compiled code to run under Android. This was installed and the test functions compiled with the arm-linux-gnueabi-gcc command, shown below (-S for assembly listing). In this case, the code was compiled to operate on two words at a time, instead of four, and would probably be much slower.
Critical assembly code for ARM/Intel NEON-Linpack benchmark is shown below.
|
T2 Device WayTeq xTAB-70 7 inch tablet, 800 MHz Cortex-A9
Screen pixels w x h 600 x 800
Android Build Version 2.3.4
Processor : ARMv7 Processor rev 1 (v7l)
BogoMIPS : 2035.71
Features : swp half thumb fastmult vfp edsp neon vfpv3
CPU part : 0xc09 - Cortex-A9
Linux version 2.6.34
T4 Device Miumiu w17 Pro 7 inch tablet, dual 1500 MHz Cortex-A9
Screen pixels w x h 600 x 976
Android Build Version 4.0.3 - Ice Cream Sandwich
Processor : ARMv7 Processor rev 0 (v7l)
processor : 0 BogoMIPS : 2393.70
processor : 1 BogoMIPS : 2393.70
Features : swp half thumb fastmult vfp edsp neon vfpv3
CPU part : 0xc09 - Cortex-A9
Hardware : Amlogic Meson6 g04 customer platform
Linux version 3.0.8
T7 Device Google Nexus 7 quad core CPU 1.3, GHz 1.2 GHz > 1 core
RAM 1 GB DDR3L-1333 Bandwidth 5.3 GB/sec
Screen pixels w x h 1280 x 736 MHz
Twelve-core Nvidia GeForce ULP graphics 416 MHz
Android Build Version 4.1.2
Processor : ARMv7 Processor rev 9 (v7l)
processor : 0 BogoMIPS : 1993.93
processor : 1 BogoMIPS : 1993.93
processor : 2 BogoMIPS : 1993.93
processor : 3 BogoMIPS : 1993.93
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x2
CPU part : 0xc09 - Cortex-A9
CPU revision : 9
Hardware : grouper - nVidia Tegra 3 T30L
Revision : 0000
Linux version 3.1.10
T10 Samsung Galaxy Note GT-N7000 Dual core 1.4 GHz Cortex-A9
Screen pixels w x h 800 x 1280
Android Build Version 4.1.2
Processor : ARMv7 Processor rev 1 (v7l)
processor : 0
BogoMIPS : 1592.52
processor : 1
BogoMIPS : 2786.91
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x2
CPU part : 0xc09
CPU revision : 1
Hardware : SMDK4210
Revision : 0008
Linux version 3.0.31
T11 Voyo A15, Samsung EXYNOS 5250 Dual core 2.0 GHz Cortex-A15,
Mali-T604 GPU, 2 GB DDR3-1600 RAM, dual channel, 12.8 GB/s
Screen pixels w x h 1920 x 1032
Android Build Version 4.2.2 - Jelly Bean
Processor : ARMv7 Processor rev 4 (v7l)
processor : 0
BogoMIPS : 992.87
processor : 1
BogoMIPS : 997.78
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x0
CPU part : 0xc0f
CPU revision : 4
Hardware : SMDK5250
Linux version 3.4.35Ut
T15 Qualcomm Snapdragon S4 2265 MHz?
Screen pixels w x h 1080 x 1776
Android Build Version 4.4
Processor : ARMv7 Processor rev 0 (v7l)
processor : 0 to 3
BogoMIPS : 38.40
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt
CPU implementer : 0x51
CPU architecture: 7
CPU variant : 0x2
CPU part : 0x06f
CPU revision : 0
Hardware : Qualcomm MSM 8974 HAMMERHEAD (Flattened Device Tree)
Revision : 000b
Linux version 3.4.0-
T16 Iconbit Nettab Skat RX, Quad Core Cortex-A9, 1.8 GHz
Screen pixels w x h 1024 x 720
Android Build Version 4.1.1
Processor : ARMv7 Processor rev 0 (v7l)
processor : 0, 1, 2, 3
BogoMIPS : 2015.34
Features : swp half thumb fastmult vfp edsp neon vfpv3
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x3
CPU part : 0xc09
CPU revision : 0
Hardware : RK30board
Revision : 0000
Linux version 3.0.36
T21 Kindle Fire HDX 7, 2.2 GHz Quad Core Qualcomm Snapdragon 800 (Krait 400)
2 x 32 Bit LPDDR3-1866 Memory, 14.9 GB/s, GPU Qualcomm Adreno 330, 578 MHz
Device Amazon KFTHWI
Screen pixels w x h 1200 x 1803
Android Build Version 4.4.3
Processor : ARMv7 Processor rev 0 (v7l)
processor : 0, 1, 2, 3
BogoMIPS : 38.40
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt
CPU implementer : 0x51
CPU architecture: 7
CPU variant : 0x2
CPU part : 0x06f
CPU revision : 0
Hardware : Qualcomm MSM8974
Revision : 0000
Linux version 3.4.0-perf (gcc version 4.7)
T22 Lenovo Tab 2 A8-50, 1.3 GHz quad core 64 bit MediaTek ARM Cortex-A53
1 GB LPDDR3, GPU Mali T720 MP2
Device LENOVO Lenovo TAB 2 A8-50F
Screen pixels w x h 800 x 1216
Android Build Version 5.0.2
Processor : AArch64 Processor rev 3 (aarch64)
processor : 0, 1, 2
BogoMIPS : 26.0
Features : fp asimd aes pmull sha1 sha2 crc32
CPU implementer : 0x41
CPU architecture: AArch64
CPU variant : 0x0
CPU part : 0xd03
CPU revision : 3
Hardware : MT8161
Linux version 3.10.65
T23 Samsung Galaxy Tab 3 10.1 P5220, 1.6 GHz Dual Core Atom Z2560
ARM Emulator Mode
Screen pixels w x h 1280 x 800
Android Build Version 4.2.2
Processor : ARMv7 processor rev 1 (v7l)
BogoMIPS : 1500
Features : neon vfp swp half thumb fastmult edsp vfpv3
CPU implementer : 0x69
CPU architecture: 7
CPU variant : 0x1
CPU part : 0x001
CPU revision : 1
Hardware : placeholder
Revision : 0001
Linux version 3.4.34
P11 Samsung Galaxy SIII, Quad Core 1.4 GHz Cortex-A9
Dual Channel DDR2 RAM
Screen pixels w x h 720 x 1280
Android Build Version 4.0.4
Processor : ARMv7 Processor rev 0 (v7l)
processor : 0 BogoMIPS : 1592.52
processor : 1 BogoMIPS : 2786.91
processor : 3 BogoMIPS : 398.13
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x3
CPU part : 0xc09
CPU revision : 0
Hardware : SMDK4x12
Revision : 000c
Serial : 3b065f3d4df1bb2d
Linux version 3.0.15
P18 Huawei Y300, Dual-core 1 GHz Cortex-A5
Screen pixels w x h 800 x 480
Android Build Version 4.1.1
Processor : ARMv7 Processor rev 1 (v7l)
processor : 0
BogoMIPS : 668.86
processor : 1
BogoMIPS : 398.13
Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3 tls vfpv4
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x0
CPU part : 0xc05
CPU revision : 1
Hardware : MSM8x25 U8833 BOARD
Linux version 3.4
P24 LG Volt, Quad Core 1.2 GHz Snapdragon Cortex-A7
Screen pixels w x h 540 x 960
Android Build Version 4.4.2
Processor : ARMv7 Processor rev 3 (v7l)
processor : 0, 1, 2, 3
BogoMIPS : 38.40
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls vfpv4 idiva idivt
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x0
CPU part : 0xc07
CPU revision : 3
Hardware : Qualcomm MSM 8226 (Flattened Device Tree)
Revision : 0006
Linux version 3.4.0
P30 Galaxy S4 i9505, Quad Core 1.9 GHz Snapdragon 600
Screen pixels w x h 1080 x 1920
Android Build Version 4.4.2
Processor : ARMv7 Processor rev 0 (v7l)
processor : 0, 1, 2, 3
BogoMIPS : 13.53
Features : swp half thumb fastmult vfp edsp neon vfpv3 tls vfpv4
CPU implementer : 0x51
CPU architecture: 7
CPU variant : 0x1
CPU part : 0x06f
CPU revision : 0
Hardware : SAMSUNG JF
Revision : 000b
Linux version 3.4.0 (gcc version 4.7)
P33 Sony Xperia Z3+ E6533, Quad-core 1.5 GHz & Quad-core 2 GHz Qualcomm
Snapdragon 810 64-bit CPU
Screen pixels w x h 1080 x 1776
Android Build Version 5.0.2
Processor : AArch64 Processor rev 1 (aarch64)
processor : 0 to 7
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x1
CPU part : 0xd07
CPU revision : 1
Hardware : Qualcomm Technologies, Inc MSM8994
Linux version 3.?10.?49
A1 Asus MemoPad 7 ME176CEX, 1.86 GHz Atom Intel Atom Z3745
Screen pixels w x h 800 x 1216
Android Build Version 4.4.2
Processor : ARMv7 processor rev 1 (v7l)
BogoMIPS : 1500.0
Features : neon vfp swp half thumb fastmult edsp vfpv3
CPU implementer : 0x69
CPU architecture: 7
CPU variant : 0x1
CPU part : 0x001
CPU revision : 1
Hardware : placeholder
Revision : 0001
Linux version 3.10.20
ET1 Device Emulator 2.4 GHz Core 2 Duo
Screen pixels w x h 600 x 1024
Android Build Version 4.0.4
Processor : ARMv7 Processor rev 0 (v7l)
BogoMIPS : 292.45
Features : swp half thumb fastmult vfp edsp neon vfpv3
CPU implementer : 0x41
CPU part : 0xc08
Linux version 2.6.29
BS1 BlueStacks Emulator on 3 GHz Phenom
Screen pixels w x h 1024 x 600
Android Build Version 2.3.4
processor : 0
vendor_id : AuthenticAMD
cpu family : 16
model : 4
model name : AMD Phenom(tm) II X4 945 Processor
stepping : 2
cpu MHz : 3013.000
cache size : 512 KB
-
-
bogomips : 26686.25
Linux version 2.6.38
|
Roy Longbottom January 2016




{kind=link}