OpenSUSE and SUSE Raspberry Pi 3 64 Bit Stress Tests
OpenSUSE and SUSE Raspberry Pi 3 64 Bit Stress Tests
Contents
GeneralRaspberry Pi 3 has a 64 bit ARM Cortex-A53 CPU, but available operating systems have been 32 bit versions. The first reference I have seen, for a 64 bit variety, was for OpenSuse. There are different distros available, one for SUSE Linux Enterprise Server. The intention is to recompile existing benchmarks to work at 64 bits. On running the first conversions, it was found that performance could be disappointingly slow and inconsistent. This problem is due to the system booting with a parameter that sets the CPU frequency to operate on demand, varying between 600 and 1200 MHz. and that caused the speed performance changes. The SD card drive booting partition, config.txt, has a parameter force_turbo=0 that sets on demand. Changing this to force_turbo=1 implies performance mode, with the clock running continuously at 1200 MHz, so it seemed. Then, the benchmarks ran at full speed. A second temporary workaround was suggested in the OpenSUSE forum, indicating that “performance” or “on demand” can be set via the cpupower terminal command (see below). Given the ability to demonstrate maximum performance of a single threaded benchmark, at a fixed 1200 MHz, raises the question of what will happen when all cores are run at maximum speeds, such as demonstrated in Raspberry Pi 2 and 3 Stress Tests, where the CPU clock gradually reduces in speed to avoid overheating. The most important floating point and integer stress tests have been compiled to run at 64 bits, both having parameters that can be used to run with data from caches or RAM. The first results below, for single core tests, further demonstrate variable speeds using on demand CPU frequency settings, consistent speeds with the performance option, and example results via caches and RAM. This is followed by multi-thread test results, using all four cores. in this case, CPU speed is reduced in small increments as temperature increases, in the same way as running earlier tests via Raspbian OS. It could be concluded that OpenSuse behaves as might be expected, using multiple cores, and it would seem to be more appropriate to boot the system using “performance” CPU frequency setting. The stress test progams and source code can be downloaded from SuseRpi3Stress.tar.gz Other results for 64 bit benchmark conversions will be included in the report on
Raspberry Pi, Pi 2 and Pi 3 Benchmarks.
Maximum MFLOPS - burninfpuPi64Arithmetic operations executed are of the form x[i] = (x[i] + a) * b - (x[i] + c) * d + (x[i] + e) * f with 2, 8 or 32 operations per input data word. The same variables are used for each word and final results are checked for consistency, any errors being reported. The benchmark has input parameters for KWords, Section 1, 2 or 3 (for 2, 8 or 32 operations per word) and log number (0 to 99). Following are results from running one copy of the program, demonstrating that, in this case, average MFLOPS speed, using on demand frequency setting, is 52% of that with the performance option. The latter is also 31% faster than the Original 32 Bit scores. Different Parameters - Results provided below show that maximum speeds are produced with data from caches, using eight operations per word. Speeds using 32 calculations are particularly disappointing. see
Assembly Code
for an explanation.
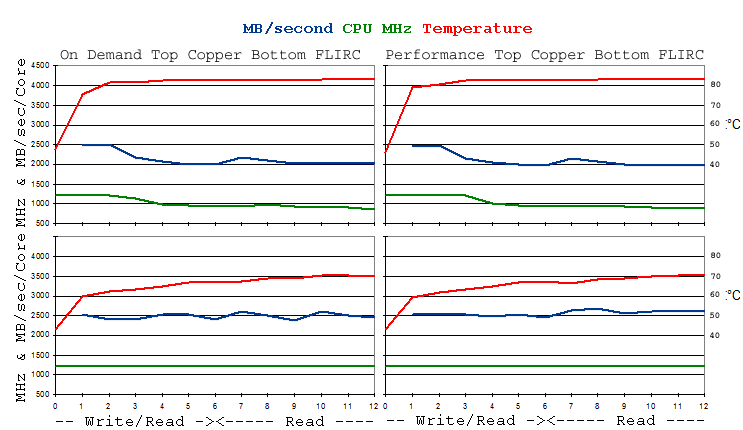
Maximum Integer MB/Second - stressintPi64This has six tests that alternately write and read data and six tests using write once and read many times, each test using two data patterns out of 24 variations. Some are shown in the results. The read phase comprises an equal number of additions and subtractions, with the data being unchanged afterwards. This is checked for correctness, at the end of each test, and any errors reported. Run time parameters are provided for KBytes memory used, seconds for each of the twelve tests and log number for use in multitasking. Default parameters are shown below. Again are results of on demand and performance settings, using default run time parameters, demonstrating the wide performance variation in the former, worst case being around half speed. Different Parameters - Speeds via L1 cache and L2 cache are similar, but the latter could be much slower using multiple tests, where data from all copies overfills the shared cache.
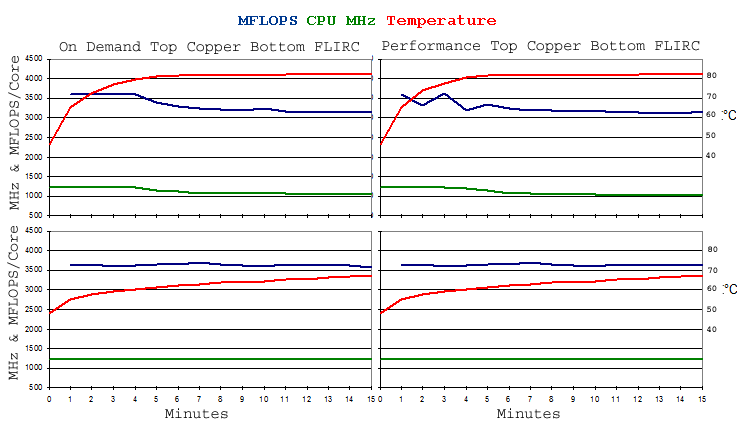
Monitoring and Tests RunCPU temperatures and MHz need to be measured, on running these stress tests, in order to help to identify reasons for performance variations. The main issue is the CPU clock speed being reduced (throttling) if temperature becomes too high. Under Raspbian, the controlling frequency is identified via the measure_clock arm command, which is not available via SUSE. Instead, data from the normal cpuinfo_cur_freq storage location appears to be used. Also, CPU temperature measurement is via a different procedure, where then sensors application needs to be installed. In this case, MHz and temperature were noted manually, using the watch command, with 1 second sampling delay, as shown below. This updates the measurements on the screen, without scrolling. The stress tests were also run starting four copies of the program, each in its own Terminal window. Originally, the procedures were kicked of using a script file. The last RPi 3 tests were run with the system board fitted in a FLIRC enclosure, where the whole aluminium case becomes the heatsink, considerably reducing CPU temperature. This was also used on these tests, where performance remained constant, over the test periods. Further tests were run using a copper heatsink. See
Earlier stress test report.
These were repeated using on demand and performance CPU frequency options.
FPU Stress TestsUnlike the single core tests, essentially the same performance was demonstrated, using on demand and performance CPU frequency options. With the FLIRC case, performance was also effectively constant, over the 15 minute tests runs, temperatures still rising but still containable. On using the copper heatsink, performance degraded as the temperature reached to 80°C, with CPU MHz reductions being displayed. Note that these and the temperature displays were then constantly flickering with slight variations in readings. The on demand results confirm that the system did not appear to perform correctly, running the single core tests, where these 4 core tests appear to be at least six times faster.
Integer Stress TestsAs for the floating point tests, the same performance was demonstrated, using on demand and performance CPU frequency options and performance was constant (within 8%) using the FLIRC case. Surprisingly, the integer tests produced lower CPU throttling MHz than the floating point program, with associated higher temperatures and slower performance.
SUSE Linux Enterprise Server (SLES)The stress tests were repeated using SLES, to see if the same on demand and performance settings were provided. They were, with default again being on demand, and measured speed variations no different. Following are average speeds of stressintPi64, running 6 minute tests at 8 KB, using 1, 2 and 4 cores. With the performance setting, except for a little degradation due to heat effects, with 4 threads, MB/second results were the same. On the other hand, default on demand option produced better performance per core as the load increased. That seems to be the wrong way round.
Assembly Code or Meanderings of an Octogenarian Ancient GEEKBelow are the assembly instructions used for the floating point stress tests. The source code has inner loops with 2, 8 or 32 arithmetic operations, but the compiler unrolls the loops to fully use quad word registers. The first two are unrolled another four times, resulting in four (x 4 way) loads at the start, four (x 4 way) stores at the end, with calculations in between. It seems that there are insufficient register for the 32 operations test, where it ends up with alternate load and arithmetic instructions. The result is that the fastest code is via 8 operations per word. Of particular interest are vector fmla and fmls instructions, or fused multiply and add or subtract, with the potential of producing 8 operations per CPU clock cycle. Best case here was 3.19 MFLOPS/MHz, for 1 core and 12.16 with 4 cores. The integer stress test, read only section, has an inner loop that loads 32 four byte words at a maximum speed of 2937 MB/second or 734 MW/second. With 32 arithmetic adds or subtracts, MOPS (Million Operations Per Second) is also 734. With 32 arithmetic operations, 32 data loads, indexing and loop overheads. A total of 99 instructions are used, or 3 per word loaded, leading to an execution speed of 2202 MIPS (Million Instructions Per Second) at 1.835 MIPS/MHz.
|