Raspberry Pi 4B Stress Tests Including High Performance Linpack
Roy Longbottom
Roy Longbottom
Contents
These stress tests are a continuation of activity also covered in
Raspberry Pi 4B 32 Bit Benchmarks.htm
|
MP-Integer-Test 32 Bit v1.0 Fri Jun 21 15:39:57 2019
Benchmark 1, 2, 4, 8, 16 and 32 Threads
MB/second
KB KB MB Same All
Secs Thrds 16 160 16 Sumcheck Tests
4.9 1 5956 5754 3977 00000000 Yes
3.6 2 11861 11429 3763 FFFFFFFF Yes
3.1 4 22998 21799 3464 5A5A5A5A Yes
3.1 8 22695 21128 3490 AAAAAAAA Yes
3.1 16 22835 23491 3485 CCCCCCCC Yes
3.0 32 22593 23485 3591 0F0F0F0F Yes
|
Stress Testing Mode
The following shows the run time command and available parameters.
./MP_IntStress Threads tt, Minutes mm, KB kk, Log ll tt = 1, 2, 4, 8, 16, 32 mm = greater than 0 kk = between 12 and 15624 ll = number added to log file name between 0 and 99
Floating Point Stress Tests - MP-FPUStress, MP-FPUStressDP
The floating point programs use functions containing 2, 8 or 32 multiply and add operations, to exploit the availability of instructions that can fuse them together for increased performance. The benchmark uses data sizes of 12.8 KB, 128 KB and 12.8 MB with calculations via 1, 2, 4 and 8 threads. Each word is initialised with the same value of 0.99999 that calculations slowly reduce, the final one being multiplied by 100000 for a sumcheck. Each word is then checked to confirm that all results are identical.
Results are provided below, showing that sumchecks vary by data size and operations per word, due to variations in the number of calculations, but are constant when the thread count is different through executing the same calculations.
Disassembly shows that Double Precision (DP) compilation produced instructions such as vfma.f64 d16, d25, fused multiply and add, operating in one DP word registers. Information available indicates that this is the best possible performance option, producing two operation results per clock cycle, 3.0 GFLOPS per core, in this case. Single Precision (SP) code was vfma.f32 q8, q2, q13 with 4 words in quad registers, where eight results per cycle, might be expected, or 12 GFLOPS per core. Actual maximum SP speeds look as though they could be about half of that.
MP-Threaded-MFLOPS 32 Bit v1.0 Sun May 26 21:23:49 2019
Benchmark 1, 2, 4 and 8 Threads
MFLOPS Numeric Results
Ops/ KB KB MB KB KB MB
Secs Thrd Word 12.8 128 12.8 12.8 128 12.8
1.6 T1 2 2134 2607 656 40392 76406 99700
2.9 T2 2 5048 5156 621 40392 76406 99700
4.0 T4 2 7536 9939 681 40392 76406 99700
5.2 T8 2 7934 9839 639 40392 76406 99700
7.2 T1 8 5535 5420 2569 54756 85091 99820
8.7 T2 8 10757 10732 2454 54756 85091 99820
10.1 T4 8 18108 20703 2444 54756 85091 99820
11.5 T8 8 19236 20286 2245 54756 85091 99820
17.4 T1 32 5309 5270 5262 35296 66020 99519
20.4 T2 32 10551 10528 9753 35296 66020 99519
22.4 T4 32 20120 20886 11064 35296 66020 99519
24.5 T8 32 19415 20464 9929 35296 66020 99519
MP-Threaded-MFLOPS 32 Bit v1.0 Sun May 26 21:26:37 2019
Double Precision Benchmark 1, 2, 4 and 8 Threads
MFLOPS Numeric Results
Ops/ KB KB MB KB KB MB
Secs Thrd Word 12.8 128 12.8 12.8 128 12.8
3.4 T1 2 921 998 326 40395 76384 99700
6.1 T2 2 1968 1995 308 40395 76384 99700
8.4 T4 2 3465 3925 342 40395 76384 99700
10.9 T8 2 3646 3702 301 40395 76384 99700
15.1 T1 8 2377 2446 1283 54805 85108 99820
18.1 T2 8 4916 4860 1326 54805 85108 99820
20.5 T4 8 9202 9510 1391 54805 85108 99820
23.1 T8 8 9090 9006 1298 54805 85108 99820
34.5 T1 32 2695 2725 2707 35159 66065 99521
40.3 T2 32 5416 5441 5121 35159 66065 99521
44.1 T4 32 10666 10831 5275 35159 66065 99521
48.3 T8 32 10427 10602 4832 35159 66065 99521
|
Stress Testing Mode
The following shows the run time command and available parameters.
./MP_FPUStress Threads tt, Minutes mm, KB kk, Ops 00, Log ll or MP_FPUStressDP tt = 1, 2, 4, 8, 16, 32, 64 mm = greater than 0 kk = between 12 and 15624 ll = number added to log file name between 0 and 99 oo = 2, 8 or 32 operations per word
Environment Monitors - RPiHeatMHzVolts2 vmstat, sar
A new version of RPiHeatMHzVolts2 was produced to incorporate temperature of the Power Measurement Integrated Circuit (PMIC). The following shows the run time command and available parameters for the program and an example of logged output.
Note that the details are instantaneous samples. This is fine for temperature measurements, that change relatively slowly, but when CPU temperature reaches a critical level, 80°C in this case, MHz throttling comes into play, and this can be down and up quite rapidly. My CPU stress test programs repetitively report average performance over a number of seconds, carrying out the same calculations, providing a better indication of the amount of throttling.
./RPiHeatMHzVolts2 Passes pp, Seconds ss, Log ll
pp = number of passes at ss intervals
ss = sampling intervals
ll = number added to log file name between 0 and 99
Temperature and CPU MHz Measurement
Temperature and CPU MHz Measurement
Start at Sun Jun 30 14:53:16 2019
Using 11 samples at 30 second intervals
Seconds
0.0 ARM MHz=1500, core volt=0.8912V, CPU temp=60.0'C, pmic temp=54.3'C
30.0 ARM MHz=1500, core volt=0.8859V, CPU temp=74.0'C, pmic temp=62.8'C
60.7 ARM MHz=1500, core volt=0.8859V, CPU temp=78.0'C, pmic temp=68.4'C
91.3 ARM MHz=1500, core volt=0.8859V, CPU temp=82.0'C, pmic temp=70.3'C
122.0 ARM MHz=1500, core volt=0.8859V, CPU temp=81.0'C, pmic temp=70.3'C
152.8 ARM MHz=1000, core volt=0.8859V, CPU temp=82.0'C, pmic temp=70.3'C
183.5 ARM MHz=1000, core volt=0.8859V, CPU temp=82.0'C, pmic temp=70.3'C
214.4 ARM MHz=1000, core volt=0.8859V, CPU temp=82.0'C, pmic temp=72.2'C
245.1 ARM MHz=1000, core volt=0.8859V, CPU temp=82.0'C, pmic temp=72.2'C
276.0 ARM MHz=1000, core volt=0.8859V, CPU temp=82.0'C, pmic temp=72.2'C
306.9 ARM MHz=1000, core volt=0.8859V, CPU temp=81.0'C, pmic temp=71.2'C
337.6 ARM MHz=1500, core volt=0.8859V, CPU temp=71.0'C, pmic temp=65.6'C
End at Sun Jun 30 14:58:54 2019
vmstat - This is used when running stress tests, to indicate system utilisation and to confirm speeds measured by tests. Main columns used are free memory, I/O bytes in and out and user plus system CPU utilisation, where 25% equals equivalent of 100% of one core.
pi@raspberrypi:~ $ vmstat 10 6 - for 6 measurements at 10 second intervals procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 3654628 20884 196956 0 0 26 1 136 223 3 1 96 0 0 1 0 0 3613900 20888 213328 0 0 0 6 1249 2143 13 2 85 0 0 1 0 0 3612044 20904 214660 0 0 0 12 991 1650 24 3 73 0 0 1 0 0 3609776 20904 216944 0 0 0 3 935 1556 25 2 73 0 0 1 0 0 3604040 20912 222448 0 0 0 12 1025 1653 25 3 73 0 0 1 0 0 3602588 20920 224852 0 0 0 6 946 1548 25 2 73 0 0sar -n DEV - This utility can be used to measure network traffic after installing Sysstat. sar -n DEV 30 25 > sar.txt - for 25 measurements over 30 second periods IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil Example Write wlan0 1190.20 2527.47 65.99 3744.17 0.00 0.00 2.93 0.00 Example Read wlan0 2340.90 1059.03 3378.11 98.89 0.00 0.00 1.60 0.00 |
OpenGL Stress Tests - videogl32
The OpenGL benchmark can also be run as a stress test. As a benchmark, it has six tests, the first four portraying moving up and down a tunnel including various independently moving objects, with and without texturing. The last two tests, represent a real application for designing kitchens. The first is in wireframe format, drawn with 23,000 straight lines, the second having colours and textures applied to the surfaces.
The program has options to specify window sizes and to avoid excessive logging for use in a script file, as in the example below. Starting with export vblank_mode=0, turns off VSYNC, identifying where FPS speeds greater than 60 FPS are possible. Following is a script file and sample Pi 4 log. Default running time is 5 seconds each test and full screen, where no sizes are specified. The time can be changes by adding such as Seconds 20 to the commands.
export vblank_mode=0
./videogl32 Width 320, Height 240, NoEnd
./videogl32 Width 640, Height 480, NoHeading, NoEnd
./videogl32 Width 1024, Height 768, NoHeading, NoEnd
./videogl32 NoHeading
###################################################################
GLUT OpenGL Benchmark 32 Bit Version 1, Thu May 2 19:01:05 2019
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
320 240 766.7 371.4 230.6 130.2 32.5 22.7
640 480 427.3 276.5 206.0 121.8 31.7 22.2
1024 768 193.1 178.8 150.5 110.4 31.9 21.5
1920 1080 81.4 79.4 74.6 68.3 30.8 20.0
Stress Tests
Below is an indication of CPU utilisation during the six tests. This is followed by results of a short stress test, where average speed over each 30 seconds is reported.
GLUT OpenGL Benchmark 32 Bit Version 1, Mon Jul 1 16:10:02 2019
Running Time Approximately 5 Seconds Each Test
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
1920 1080 57.3 56.2 53.4 49.9 30.7 19.9
1 core CP UT 20 28 40 68 104 100
###################################################################
Run Commands - export vblank_mode=0
./videogl32 Test 4, Mins 1, Log 7
OpenGL Reliability Test 32 Bit Version 1, Wed Jul 3 17:28:02 2019
Display 1920 x 1080 All Objects, With Textures, Test for 1 minutes
Test 4 All Objects, With Textures, 30 seconds, 47 FPS
Test 4 All Objects, With Textures, 30 seconds, 46 FPS
End at Wed Jul 3 17:29:03 2019
|
Livermore Loops Stress Test - liverloopsPiA7R
The Livermore Loops benchmark was converted to act as a stress test, following wrong numeric results being produced on an overclocked, PC using a Pentium Pro CPU. The Loops comprise 24 double precision floating point kernels, with performance measurements in terms of Millions of Floating Point Operations Per Second or MFLOPS. The kernel tests are repeated three times, with different data sizes. By including the running time of each loop converts the benchmark into a stress test, whereby numeric results of calculations are checked for correctness after each of the numerous passes, with errors errors being logged, along with performance details. Detailed results are displayed continuously, as the tests are running. There is too much detail for logging. So, as shown below, the start times of each section are reported.
Below an example command to run each test for approximately 12 seconds and save results in LoopsLog1.txt. Total time should be around 24 x 3 x 12 = 864 seconds, or longer with CPU MHz throttling. This is followed by an example of results for a short run.
Run command - ./liverloopsPiA7R Seconds 12 Log 1
#####################################################
Livermore Loops Benchmark vfpv4 32 Bit via C/C++ Wed Jul 3 15:11:50 2019
Reliability test 2 seconds each loop x 24 x 3
Part 1 of 3 start at Wed Jul 3 15:11:50 2019
Part 2 of 3 start at Wed Jul 3 15:12:38 2019
Part 3 of 3 start at Wed Jul 3 15:13:27 2019
Numeric results were as expected
MFLOPS for 24 loops
745.8 955.8 988.7 942.6 209.0 769.8 1194.1 1792.5 1254.6 447.9 213.2 186.3
150.7 349.9 778.3 623.3 734.2 1035.4 322.9 350.0 435.8 352.9 746.1 187.3
Overall Ratings
Maximum Average Geomean Harmean Minimum
1793.5 641.2 520.2 412.7 140.3
End of test Wed Jul 3 15:14:16 2019
|
Input/Output Stress Test - burnindrive2
This is essentially the same as my program used during hundreds of UK Government and University computer acceptance trials during the 1970s and 1980s, with some significant achievements. Burnindrive writes four files, using 164 blocks of 64 KB, repeated 16 times (164.0 MB), with each block containing a unique data pattern. The files are then read for two minutes, on a sort of random sequence, with data and file ID checked for correct values. Then each block (unique pattern) is read numerous times, over one second, again with checking for correct values. Total time is normally about 5 minutes for all tests, with default parameters. The data patterns are shown below, followed by run time parameters, then examples of results provided (see later detailed results).
Patterns
No. Hex No. Hex No. Hex No. Hex No. Hex No. Hex No. Hex
1 0 25 800000 49 3 73 FF 97 FFFFDFFF 121 FFFFEAAA 145 FFFFF0F0
2 1 26 1000000 50 33 74 FF00FF 98 FFFFBFFF 122 FFFFAAAA 146 FFF0F0F0
3 2 27 2000000 51 333 75 1FF 99 FFFF7FFF 123 FFFEAAAA 147 F0F0F0F0
4 4 28 4000000 52 3333 76 3FF 100 FFFEFFFF 124 FFFAAAAA 148 FFFFFFE0
5 8 29 8000000 53 33333 77 7FF 101 FFFDFFFF 125 FFEAAAAA 149 FFFF83E0
6 10 30 10000000 54 333333 78 FFF 102 FFFBFFFF 126 FFAAAAAA 150 FE0F83E0
7 20 31 20000000 55 3333333 79 1FFF 103 FFF7FFFF 127 FEAAAAAA 151 FFFFFFC0
8 40 32 40000000 56 33333333 80 3FFF 104 FFEFFFFF 128 FAAAAAAA 152 FFFC0FC0
9 80 33 1 57 7 81 7FFF 105 FFDFFFFF 129 EAAAAAAA 153 FFFFFF80
10 100 34 5 58 1C7 82 FFFF 106 FFBFFFFF 130 AAAAAAAA 154 FFE03F80
11 200 35 15 59 71C7 83 FFFFFFFF 107 FF7FFFFF 131 FFFFFFFC 155 FFFFFF00
12 400 36 55 60 1C71C7 84 FFFFFFFE 108 FEFFFFFF 132 FFFFFFCC 156 FF00FF00
13 800 37 155 61 71C71C7 85 FFFFFFFD 109 FDFFFFFF 133 FFFFFCCC 157 FFFFFE00
14 1000 38 555 62 F 86 FFFFFFFB 110 FBFFFFFF 134 FFFFCCCC 158 FFFFFC00
15 2000 39 1555 63 F0F 87 FFFFFFF7 111 F7FFFFFF 135 FFFCCCCC 159 FFFFF800
16 4000 40 5555 64 F0F0F 88 FFFFFFEF 112 EFFFFFFF 136 FFCCCCCC 160 FFFFF000
17 8000 41 15555 65 F0F0F0F 89 FFFFFFDF 113 DFFFFFFF 137 FCCCCCCC 161 FFFFE000
18 10000 42 55555 66 1F 90 FFFFFFBF 114 BFFFFFFF 138 CCCCCCCC 162 FFFFC000
19 20000 43 155555 67 7C1F 91 FFFFFF7F 115 FFFFFFFE 139 FFFFFFF8 163 FFFF8000
20 40000 44 555555 68 1F07C1F 92 FFFFFEFF 116 FFFFFFFA 140 FFFFFE38 164 FFFF0000
21 80000 45 1555555 69 3F 93 FFFFFDFF 117 FFFFFFEA 141 FFFF8E38
22 100000 46 5555555 70 3F03F 94 FFFFFBFF 118 FFFFFFAA 142 FFE38E38
23 200000 47 15555555 71 7F 95 FFFFF7FF 119 FFFFFEAA 143 F8E38E38
24 400000 48 55555555 72 1FC07F 96 FFFFEFFF 120 FFFFFAAA 144 FFFFFFF0
Sequences - First 16
No. File No. File No. File No. File
1 0 1 2 3 5 0 2 1 3 9 0 3 1 2 13 0 1 2 3
2 1 2 3 0 6 1 3 2 0 10 1 0 3 2 14 1 2 3 0
3 2 3 0 1 7 2 0 1 3 11 2 1 0 3 15 2 3 0 1
4 3 0 2 1 8 3 1 2 0 12 3 2 1 0 16 3 0 2 1
###########################################################################
Run Time Parameters - Upper or Lower Case
Default
R or Repeats Data size, multiplier of 10.25 MB, more or less 16
P or Patterns Number of patterns for smaller files < 164 164
M or Minutes Large file reading time 2
L or Log Log file name extension 0 to 99 0
S or Seconds Time to read each block, last section 1
F or FilePath For other than SD card or SD card directory
C or CacheData Omit O_DIRECT on opening files to allow caching No
O or OutputPatterns Log patterns and file sequences used as above No
D or DontRunReadTests Or only run write tests No
Format ./burnindrive2 Repeats 16, Minutes 2, Log 0, Seconds 1
or ./burnindrive2 R 16, M 2, L 0, S 1
###########################################################################
Examples of Results
File 1 164.00 MB written in 12.79 seconds
File 2 164.00 MB written in 11.93 seconds
Read passes 1 x 4 Files x 164.00 MB in 0.31 minutes
Read passes 2 x 4 Files x 164.00 MB in 0.63 minutes
Passes in 1 second(s) for each of 164 blocks of 64KB:
580 580 580 580 580 580 580 580 580 580 580
580 580 580 580 580 580 580 580 580 580 580
|
High Performance Linpack Benchmark - xhpl
In 1993, it was found that a precompiled version of High Performance Linpack (HPL) could produce the wrong and inconsistent numeric calculations, also system crashes. For more information see this
Raspberry Pi 3B and 3B+ High Performance Linpack and Error Tests.htm.
This report includes behaviour of another version, compiled to use ATLAS, using alternative Basic Linear Algebra Subprograms. This took 14 hours to build, and was slower than the earlier one, but still produced the same failures. As indicated in the report, my stress tests could be arranged to produce similar problems. There were no sumcheck failures or system crashes, using the Pi 3B+.
The original precompiled version would not run on the Pi 4 but I rebuilt ATLAS on the new system, this time taking 8 hours. an example of the output for a quick test is shown below:
HPLinpack 2.2 -- High-Performance Linpack benchmark -- February 24, 2016
Written by A. Petitet and R. Clint Whaley, Innovative Computing Laboratory, UTK
Modified by Piotr Luszczek, Innovative Computing Laboratory, UTK
Modified by Julien Langou, University of Colorado Denver
================================================================================
An explanation of the input/output parameters follows:
T/V : Wall time / encoded variant.
N : The order of the coefficient matrix A.
NB : The partitioning blocking factor.
P : The number of process rows.
Q : The number of process columns.
Time : Time in seconds to solve the linear system.
Gflops : Rate of execution for solving the linear system.
The following parameter values will be used:
N : 1000
NB : 128
PMAP : Row-major process mapping
P : 2
Q : 2
PFACT : Right
NBMIN : 4
NDIV : 2
RFACT : Crout
BCAST : 1ringM
DEPTH : 1
SWAP : Mix (threshold = 64)
L1 : transposed form
U : transposed form
EQUIL : yes
ALIGN : 8 double precision words
--------------------------------------------------------------------------------
- The matrix A is randomly generated for each test.
- The following scaled residual check will be computed:
||Ax-b||_oo / ( eps * ( || x ||_oo * || A ||_oo + || b ||_oo ) * N )
- The relative machine precision (eps) is taken to be 1.110223e-16
- Computational tests pass if scaled residuals are less than 16.0
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR11C2R4 1000 128 2 2 0.17 4.048e+00
HPL_pdgesv() start time Sun May 26 08:44:56 2019
HPL_pdgesv() end time Sun May 26 08:44:56 2019
------------------------------------------------------------------------========
|
Unstressed Tests
It is quite easy to produce programs that run at high speeds on all cores of a modern computer, be it a PC, tablet, phone or a small board system like the Raspberry Pi. These programs are likely to lead to increased CPU temperatures. Given insufficient cooling arrangements, the systems are likely to continuously reduce CPU MHz (throttling) in order to continue operation, and eventually power down.
Before examining the results of stress testing, it is useful to consider what can be run without throttling occurring, in this case, on a Raspberry Pi 4, without any cooling.
Single Core and Multi-Core CPU Tests
Below are various results from running five minute MP-Integer-Tests on a Raspberry Pi 4B, out of the case, with no cooling attachment. As indicated earlier, ongoing speed measurements by a benchmark provides a better understanding of behaviour, than samples of CPU MHz, that can vary rapidly.
Starting and ending recorded temperatures are shown, along with time when and if 80°C was reached, when throttling will start. The first column is for a run using a single thread, where CPU MHz, and effectively measured speeds, were constant over the whole period. The second column provides details when using four threads, with data in L1 caches. The next two made use of data in L2 cache, starting throttling after one minute, worse than the L1 results, but starting at a higher temperature. The last column provides results when data was in RAM and running at full speed for over four aand a half minutes.
MB/second
Cache/RAM L2 L1 L2 L2 RAM
KB 512 64 640 1536 15624
Threads 1 4 4 8 4
Start 62 60 62 64 61
10 5718 23631 22628 20177 3445
20 5717 23603 22634 18329 3443
30 5640 23416 22670 18756 3405
40 5735 23613 22045 17737 3440
50 5740 23618 22636 18456 3444
60 5652 23244 22069 19059 3410
70 5707 23483 19864 17648 3437
80 5736 23360 18639 16017 3445
90 5683 21552 17986 16654 3447
100 5695 20867 17383 14864 3395
110 5719 20218 16475 14805 3437
120 5672 19017 16207 15128 3443
130 5727 18871 15165 13328 3401
140 5735 18888 14773 12638 3437
150 5732 18460 14979 12780 3443
160 5677 17799 14780 13086 3440
170 5719 17976 14313 13221 3404
180 5711 18005 14391 12618 3443
190 5650 17745 14018 12185 3440
200 5738 17312 14120 13267 3397
210 5709 17241 14062 11916 3442
220 5678 17124 14004 11866 3441
230 5719 17392 13467 12018 3397
240 5720 16990 13728 11825 3440
250 5651 17289 13372 12011 3434
260 5714 17135 13683 11596 3442
270 5717 16891 13584 11481 3398
280 5657 16505 13055 11781 3442
290 5725 17049 13396 11550 3445
300 5713 16578 12957 11666 3402
Max 5740 23631 22670 20177 3447
Min 5640 16505 12957 11481 3395
% 98 70 57 57 98
Max C 72 82 84 85 80
Time 80°C N/A 90 60 60 280
|
OpenGL Test No Cooling
Earlier, I connected the Pi 4 system to BBC iPlayer, via WiFi, and displayed programmes for more than two hours on a full screen 1920x1080 display (not a hot day). With CPU utilisation around 100% of one core, maximum temperature was 70°C, with CPU at 1500 MHz all the time.
For this exercise, I ran the OpenGL Textured Kitchen test for an hour, with a full screen display (hotter day than above). Following is a summary of recorded results by the program, the environmental monitor and vmstat. The program ran at 22 FPS over the whole period, with CPU at a constant 1500 MHz, recording slightly more than 100% utilisation of one core, with maximum temperature reaching 73°C.
=------ Monitors ------ --------- vmstat --------- Video
gl32
°C °C
Seconds MHz Volts CPU PMIC free User System Idle FPS
0 1500 0.8894 61 54 3589900 0 0 100
120 1500 0.8841 69 59 3523336 25 2 73 22
240 1500 0.8841 71 62 3520464 25 2 73 22
360 1500 0.8841 71 63 3522848 25 2 73 22
480 1500 0.8841 73 63 3522292 25 2 73 22
600 1500 0.8841 72 63 3522284 25 2 73 22
720 1500 0.8841 72 63 3521780 24 2 74 22
840 1500 0.8841 73 63 3520640 25 2 73 22
960 1500 0.8841 72 63 3520884 25 2 73 22
1080 1500 0.8841 72 63 3520140 25 2 73 22
1200 1500 0.8841 73 63 3519864 24 2 73 22
1320 1500 0.8841 73 63 3519892 25 2 73 22
1440 1500 0.8841 73 63 3519892 25 2 73 22
1560 1500 0.8841 73 63 3518880 25 2 73 22
1680 1500 0.8841 72 63 3519264 25 2 73 22
1800 1500 0.8841 73 63 3517976 25 2 73 22
1920 1500 0.8841 73 63 3518616 25 2 73 22
2040 1500 0.8841 72 63 3517984 25 2 73 22
2160 1500 0.8841 72 63 3518604 24 2 73 22
2280 1500 0.8841 73 63 3518496 25 2 73 22
2400 1500 0.8841 73 63 3518868 25 2 73 22
2520 1500 0.8841 72 63 3518488 25 2 73 22
2640 1500 0.8841 73 63 3518212 25 2 73 22
2760 1500 0.8841 73 63 3520008 25 2 73 22
2880 1500 0.8841 73 63 3519756 25 2 73 22
3000 1500 0.8841 73 63 3516752 25 3 72 22
3120 1500 0.8841 73 63 3518132 25 2 73 22
3240 1500 0.8841 73 63 3518132 25 2 73 22
3360 1500 0.8841 73 63 3517620 24 2 73 22
3480 1500 0.8841 73 63 3517428 25 2 73 22
3600 1500 0.8841 73 63 3517656 25 2 73 22
|
Integer Stress Tests - MP-IntStress
The following are results of 15 minute stress tests, using 1280 KB data and 8 threads. The data is greater than L2 cache, but was in cache as only four threads were executed at a time. This then ran at full speed, with additional swapping of cached data.
Four tests were carried out with no added cooling on a bare board, fitted with a copper heatsink, then with the official, and expensive, Power Over Ethernet fan and, finally, using an inexpensive case with a fitted fan (GeeekPi Acrylic Case). The changing CPU MHz measurements show that throttling is occurring but, with coarse sampling, they do not reflect real performance, unlike the MB/second details.
With no cooling, throttling started after a minute, reaching 85°C to 86°C, slowly reducing performance to almost half speed. The copper heatsink produced a small improvement. During the two tests where fans were used, the processor ran continuously at 1500 MHz and throughput effectively at a constant MB/second. The POE fan appeared to be slightly more efficient.
No Cooling Copper Heatsink Official POE Hat Case With Fan
Seconds MB/sec MHz °C MB/sec MHz °C MB/sec MHz °C MB/sec MHz °C
0 1500 60 1500 60 1500 47 1500 41
20 21651 1500 73 21381 1500 71 21770 1500 56 22018 1500 54
40 21892 1500 79 20517 1500 74 21767 1500 57 21979 1500 56
60 20919 1500 81 21407 1500 77 22234 1500 57 22076 1500 58
80 17174 1000 81 21153 1500 79 22035 1500 58 22248 1500 60
100 15643 1000 81 20960 1500 81 21920 1500 59 22153 1500 61
120 15163 1000 82 18967 1500 82 22184 1500 60 22239 1500 63
140 14756 1000 81 16828 1000 81 21941 1500 60 22037 1500 64
160 14491 1000 83 15892 1500 83 21863 1500 60 22231 1500 65
180 14492 1000 83 16157 1000 82 21753 1500 60 22130 1500 64
200 14283 1000 84 15039 1000 82 21921 1500 60 22050 1500 65
220 14386 1000 83 15438 1000 82 21656 1500 60 22210 1500 66
240 14101 1000 83 14905 1000 82 21908 1500 60 22132 1500 65
260 13574 1000 84 14597 1000 83 21983 1500 60 22298 1500 65
280 13763 1000 83 14703 1000 83 21701 1500 60 22031 1500 66
300 13179 1000 84 14519 1000 82 21857 1500 60 22285 1500 65
320 13566 1000 84 14204 1000 84 21791 1500 60 22009 1500 65
340 13368 750 84 14139 750 83 21468 1500 60 22101 1500 65
360 13530 1000 84 14249 1000 84 22162 1500 60 22166 1500 65
380 13190 1000 85 14457 1000 82 21819 1500 61 22163 1500 66
400 13215 1000 84 14395 1000 83 21800 1500 60 22243 1500 65
420 13021 750 85 14365 1000 83 22083 1500 61 22115 1500 64
440 13127 1000 84 14214 1000 83 21780 1500 60 22172 1500 64
460 12933 1000 85 14152 1000 83 21902 1500 60 22138 1500 64
480 12658 1000 85 14090 1000 84 21964 1500 60 22220 1500 64
500 12981 750 83 14199 1000 84 22026 1500 61 22061 1500 65
520 12699 1000 85 14005 1000 83 21661 1500 61 22027 1500 64
540 12622 1000 84 13987 1000 84 21684 1500 60 22281 1500 65
560 12761 1000 84 14222 1000 84 22071 1500 59 22097 1500 64
580 13408 1000 84 13845 1000 84 21728 1500 58 22225 1500 64
600 13878 1000 85 13945 1000 84 21981 1500 59 22091 1500 62
620 13893 1000 83 13877 1000 84 21704 1500 58 22203 1500 62
640 13717 1000 86 13844 1000 84 21935 1500 58 22133 1500 62
660 13321 1000 85 13774 1000 83 21816 1500 61 22075 1500 62
680 13154 1000 85 13500 1000 83 21827 1500 61 22229 1500 63
700 12663 1000 85 13926 1000 83 21995 1500 60 22007 1500 63
720 12504 1000 85 13722 1000 83 22004 1500 60 22279 1500 64
740 12501 750 85 13778 750 84 21954 1500 60 22020 1500 65
760 12227 1000 85 13564 1000 83 21848 1500 60 22270 1500 65
780 12199 750 85 13755 1000 82 21840 1500 61 22129 1500 65
800 12505 1000 85 13451 1500 82 22137 1500 59 22175 1500 64
820 12268 750 85 13587 1000 83 21876 1500 60 22210 1500 64
840 12322 1500 85 13610 1000 82 21685 1500 61 22041 1500 65
860 12312 1500 85 14411 1500 82 22077 1500 61 22192 1500 65
880 12306 1500 85 14380 1500 83 21842 1500 61 22109 1500 65
900 12305 1500 85 14345 1500 83 21883 1500 61 22199 1500 65
Max 21892 86 21407 84 22234 61 22298 66
Min 12199 750 13451 750 21468 1500 21979 1500
%Min/Max 56 63 97 99
|
Single Precision Floating Point Stress Tests - MP-FPUStress
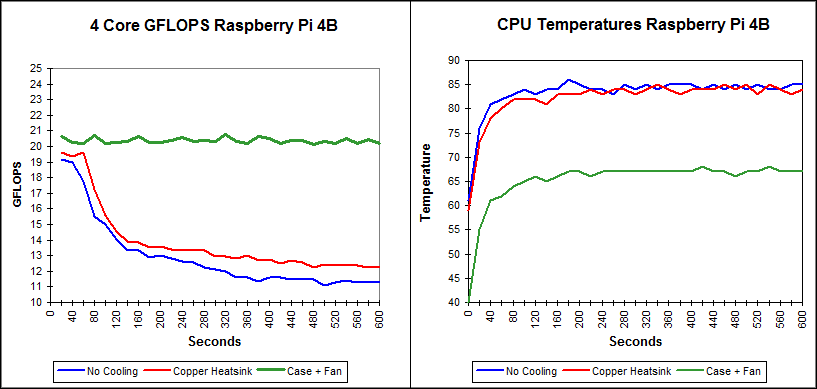
The table below covers the first 10 minutes of tests on the three cooling configurations. This time, the rather meaningless variations in recorded CPU MHz are not included. Again they used 1280 KB data (320K words) and 8 threads, with 8 floating point operations per word. Maximum temperatures and associated performance degradations were similar to those during the integer tests.
The following graphs provide a more meaningful indication of the effects of adequate cooling that is needed for this kind CPU utilisation (confirmed during running by vmstat as 100% of four cores).
No Cooling Copper HS Case+Fan
Seconds °C GFLOPS °C GFLOPS °C GFLOPS
0 61 59 40
20 76 19.2 73 19.6 55 20.7
40 81 19.0 78 19.4 61 20.3
60 82 17.8 80 19.6 62 20.2
80 83 15.5 82 17.2 64 20.7
100 84 15.0 82 15.6 65 20.2
120 83 14.0 82 14.5 66 20.3
140 84 13.3 81 13.9 65 20.3
160 84 13.3 83 13.9 66 20.7
180 86 12.9 83 13.5 67 20.3
200 85 13.0 83 13.6 67 20.3
220 84 12.8 84 13.4 66 20.4
240 84 12.6 83 13.3 67 20.6
260 83 12.6 84 13.3 67 20.3
280 85 12.2 84 13.3 67 20.4
300 84 12.1 83 13.0 67 20.3
320 85 12.0 84 13.0 67 20.8
340 84 11.6 85 12.8 67 20.3
360 85 11.6 84 13.0 67 20.2
380 85 11.3 83 12.7 67 20.7
400 85 11.6 84 12.8 67 20.5
420 84 11.6 84 12.5 68 20.2
440 85 11.5 84 12.7 67 20.4
460 84 11.5 85 12.6 67 20.4
480 85 11.5 84 12.3 66 20.2
500 84 11.1 85 12.4 67 20.3
520 85 11.3 83 12.4 67 20.2
540 84 11.4 85 12.4 68 20.5
560 84 11.3 84 12.3 67 20.2
580 85 11.3 83 12.3 67 20.4
600 85 11.3 84 12.3 67 20.2
900 85 10.9 84 12.2 67 20.3
Max 19.2 19.6 20.8
Min 10.9 12.2 20.3
%Min/Max 57
|
Double Precision Floating Point Stress Tests - MP-FPUStressDP
Four sets of results are below, again excluding those CPU MHz figures, but including PMIC temperatures. They are without and with the case/fan, using 8 threads, one with 1280 KB data size at 8 operations per word, and the other 128 KB with 32 operations per word.
The second one runs at a higher speed and lower temperature, using data in L1 caches, compared with the other via L2 cache. Maximum temperature and performance degradation of the latter were similar to the earlier examples.
1280 KB, 8 Threads, 8 Ops/Word 128 KB, 8 Threads, 32 Ops/Word
No Fan CPU PMIC Fan CPU PMIC No Fan CPU PMIC Fan CPU PMIC
Second GFLOPS °C °C GFLOPS °C °C GFLOPS °C °C GFLOPS °C °C
0 48 42.0 45 42.0 54 47.7 39 35.4
20 9.3 64 55.2 9.1 61 55.2 10.7 70 57.1 10.7 39 35.4
40 9.2 73 62.8 9.0 65 59.0 10.6 73 61.8 10.7 53 43.9
60 9.2 79 68.4 9.1 67 61.8 10.7 75 64.6 10.6 56 48.6
80 8.8 80 70.3 9.3 66 62.8 10.7 78 67.5 10.6 57 50.5
100 7.8 81 70.3 9.1 67 62.8 10.7 80 69.4 10.7 58 51.4
120 7.2 82 70.3 9.2 67 62.8 10.1 82 70.3 10.7 59 53.3
140 6.8 82 70.3 9.3 67 62.8 9.5 81 70.3 10.7 59 53.3
160 6.5 82 70.3 9.1 68 62.8 9.1 80 70.3 10.6 59 53.3
180 6.3 82 70.3 9.1 68 62.8 8.7 82 70.3 10.7 60 53.3
200 6.1 81 70.3 9.3 68 64.6 8.5 81 70.3 10.7 59 54.3
220 6.2 82 70.3 9.1 69 62.8 8.5 82 70.3 10.7 59 54.3
240 6.2 83 72.2 9.1 68 62.8 8.3 81 70.3 10.6 60 54.3
260 6.1 83 72.2 9.3 68 62.8 8.3 81 70.3 10.7 59 54.3
280 6.1 84 72.2 9.1 67 64.6 8.0 83 70.3 10.7 61 54.3
300 6.1 83 70.3 9.1 68 64.6 8.0 81 70.3 10.6 60 54.3
320 6.0 84 72.2 9.1 68 64.6 7.9 82 70.3 10.7 61 54.3
340 5.9 85 72.2 9.2 68 64.6 7.6 82 71.2 10.8 61 53.3
360 5.8 85 72.2 9.1 68 62.8 7.7 82 70.3 10.7 60 54.3
380 5.8 84 72.2 9.2 68 64.6 7.8 83 70.3 10.6 60 54.3
400 5.7 84 72.2 9.1 68 62.8 7.7 83 70.3 10.6 61 54.3
420 5.7 84 72.2 9.2 68 62.8 7.7 82 70.3 10.6 60 54.3
440 5.6 84 72.2 9.1 68 64.6 7.6 82 70.3 10.7 60 54.3
460 5.7 84 72.2 9.1 68 62.8 7.6 83 70.3 10.6 61 54.3
480 5.6 84 72.2 9.1 69 64.6 7.5 82 70.3 10.7 60 54.3
500 5.6 84 72.2 9.1 69 62.8 7.5 82 71.2 10.6 60 54.3
520 5.5 85 72.2 9.1 68 62.8 7.4 81 70.3 10.7 60 54.3
540 5.5 84 74.1 9.3 67 64.6 7.4 82 70.3 10.7 60 54.3
560 5.5 84 72.2 9.1 69 62.8 7.4 82 70.3 10.8 59 54.3
580 5.4 84 74.1 9.1 67 64.6 7.3 82 70.3 10.7 60 55.2
600 5.5 84 74.1 9.2 68 62.8 7.3 81 70.3 10.7 60 54.3
620 5.4 85 74.1 9.2 68 62.8 7.3 82 70.3 10.6 61 54.3
640 5.4 84 74.1 9.2 69 62.8 7.3 83 70.3 10.6 62 55.2
660 5.4 85 74.1 9.3 68 62.8 7.3 83 70.3 10.7 60 54.3
680 5.5 85 72.2 9.0 67 62.8 7.3 83 70.3 10.7 60 54.3
700 5.4 85 74.1 9.1 69 62.8 7.3 81 70.3 10.7 60 54.3
720 5.4 85 72.2 9.2 68 64.6 7.3 84 70.3 10.7 60 54.3
740 5.4 84 72.2 9.1 68 62.8 7.3 82 70.3 10.7 60 55.2
760 5.3 85 74.1 9.1 68 62.8 7.3 81 70.3 10.7 60 54.3
780 5.4 85 74.1 9.3 67 62.8 7.3 83 70.3 10.7 59 54.3
800 5.4 84 74.1 9.1 69 64.6 7.3 81 70.3 10.7 60 54.3
820 5.3 85 72.2 9.1 68 62.8 7.3 82 70.3 10.7 60 54.3
840 5.3 84 72.2 9.2 68 62.8 7.2 82 70.3 10.7 60 54.3
860 5.2 85 74.1 9.1 69 64.6 7.2 81 70.3 10.6 60 54.3
880 5.2 85 74.1 9.1 68 62.8 7.2 82 70.3 10.6 60 54.3
900 5.3 84 74.1 9.1 68 62.8 7.2 81 70.3 10.6 60 54.3
Max 9.3 85 74.1 9.3 69 64.6 10.7 84 71.2 10.8 62 55.2
Min 5.2 9.0 7.2 10.6
%Min/Ma 57 97 67 98
|
High Performance Linpack Tests - xhpl
Parameter sizes (as set in HPL.dat) were the same as in the introductory description, except for the one for data size (N). The programs were run on a bare board Pi 4 and one in the inexpensive case with a fan. No data errors or system freezes/crashes were encountered over these and many more runs.
Following is a summary of four tests on each of the test beds. The the bare board arrangement performs relatively well for short duration tests, but the long ones are needed to demonstrate maximum performance. The latter was 10.8 Double Precision GFLOPS, similar to my MP-FPUStressDP program, where, at 58%, that also applied to efficiency of the uncooled processor. As it should be, the sumchecks of hot and cold systems were identical, at a given data size.
Assuming similarity with the original scalar Linpack benchmark, data size would be N x N x 8 for double precision operation or 3.2 GB at N = 20000, as approximately confirmed by the vmstat memory details provided below. The latter also indicate that the four core CPU utilisation was 100%.
Below the table is a graph, of the worst case uncooled scenario, to demonstrate CPU MHz throttling and temperature (°C times 10), based on samples every 10 seconds.
Cooling N Seconds GFLOPS SumCheck Max °C Av MHz None 4000 5.7 7.4 0.002398 71 1500 Fan 4000 5.2 8.2 0.002398 54 1500 None 8000 39.9 8.6 0.001675 81 1500 Fan 8000 36.7 9.3 0.001675 61 1500 None 16000 404.3 6.8 0.001126 86 919 Fan 16000 263.0 10.4 0.001126 70 1500 None 20000 856.0 6.2 0.001019 87 828 Fan 20000 494.3 10.8 0.001019 71 1500 %None/Fan 20000 58 58 Same 55 procs -----------memory---------- ---swap-- -----io---- -system- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 3510712 30172 276440 0 0 17 1 90 111 16 1 83 0 0 4 0 0 3097880 30180 277088 0 0 0 6 526 515 52 3 45 0 0 4 0 0 2357404 30188 276492 0 0 0 6 620 344 95 5 0 0 0 4 0 0 1615192 30196 276976 0 0 0 11 586 289 95 5 0 0 0 5 0 0 871872 30204 271032 0 0 0 5 490 75 96 4 0 0 0 4 0 768 282692 26828 241092 0 34 20 40 604 307 95 4 0 0 0 4 0 768 276088 26968 250344 6 0 118 12 591 288 99 1 0 0 0 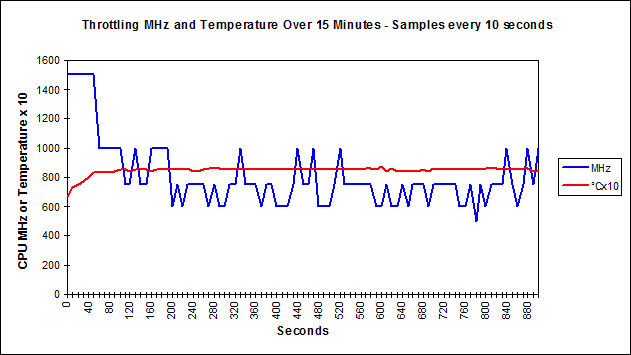
|
Livermore Loops/OpenGL Tests
Three copies of Livermore Loops stress tests were run along with the OpenGL Tiled Kitchen section, on a Pi 4 without any cooling, then in the case with a fan. The former program was arranged to have a nominal durations of 864 seconds (72 x 12). When running, the CPU load is continuously changing and that can be reflected in ongoing temperature and OpenGL Frames Per Second. The tests make use of six terminal windows and a full screen display, run by the commands shown below. This is followed by the results.
With no cooling, there were the usual increases in temperature and performance degradation, but not as severe as some of the earlier tests. With cooling performance was effectively constant. Averages at the end reflect the differences. There were no reports of errors or any sign of system failures.
Dual Monitors - The benchmarks, with no cooling, were repeated using two monitors, providing a screen area of 3840 x 1080 pixels, the results being included below. Performance was only between 7% and 15% slower than the single monitor example. Benchmark results of all OpenGL tests and provided at the end of the table, showing those more dependent on graphics speed were affected by the number of pixels displayed.
Run Commands
Terminal 1
vmstat 10 100
Terminal 2 script file
lxterminal -e ./RPiHeatMHzVolts2 Passes 120 Seconds 10 Log 20
lxterminal -e ./liverloopsPiA7R Seconds 12 Log 20
lxterminal -e ./liverloopsPiA7R Seconds 12 Log 21
lxterminal -e ./liverloopsPiA7R Seconds 12 Log 22
Terminal 3
./videogl32 Test 6, Mins 16, Log 20
Dual Monitors
No Cooling Case + Fan No Cooling
Seconds MHz °C FPS MHz °C FPS MHz °C FPS
0 1500 64 1500 42 1500 69
30 1000 82 19 1500 57 20 1000 82 13
60 1000 82 16 1500 62 21 750 84 13
90 1500 83 15 1500 66 20 1000 83 12
120 750 85 13 1500 64 21 1000 85 11
150 1000 84 13 1500 62 20 600 84 10
180 1000 83 14 1500 60 22 750 85 10
210 1000 84 15 1500 62 21 1000 85 12
240 1000 83 14 1500 61 19 750 84 12
270 1000 84 14 1500 63 21 1000 85 11
300 1000 84 14 1500 61 21 750 84 12
330 750 84 14 1500 64 21 1000 85 12
360 1000 82 14 1500 64 21 750 84 11
390 1000 83 12 1500 66 21 750 84 12
420 1000 84 13 1500 63 21 750 84 12
450 1000 84 14 1500 62 20 750 85 11
480 750 84 12 1500 63 21 750 85 12
510 750 85 13 1500 61 21 1000 84 12
540 750 84 11 1500 59 21 750 84 11
570 1000 84 12 1500 62 21 1000 85 11
600 1000 84 14 1500 62 22 750 83 10
630 1000 84 13 1500 66 19 750 84 11
660 750 84 14 1500 60 21 750 85 12
690 750 86 13 1500 65 21 1000 85 12
720 1000 84 13 1500 63 21 600 83 11
750 1000 83 13 1500 62 21 1000 84 12
780 750 84 12 1500 61 21 1000 85 11
810 750 85 12 1500 62 21 1000 84 11
840 1000 85 12 1500 58 21 750 86 10
870 750 85 12 1500 58 21 750 85 11
900 1000 84 13 1500 54 21 1000 85 10
930 1000 85 13 1500 50 21 1000 85 11
960 1000 84 13 1500 49 21 750 85 11
990 1000 85 14 1500 45 21 750 85 12
Average 956 83 13 1500 60 21 866 84 11
%Fan 64 139 64
MFLOPS 916 1502 854
%Fan 61
OpenGL Benchmark Single and Dual Monitors
Window Size Coloured Objects Textured Objects WireFrm Texture
Pixels Few All Few All Kitchen Kitchen
Wide High FPS FPS FPS FPS FPS FPS
1920 1080 58.2 56.7 54.5 49.9 31.0 20.7
3840 1080 27.9 26.5 26.0 25.2 25.7 16.3
|
Input/Output Stress Tests - burnindrive2
For this test, three copies of burnindrive2 were run, accessing the main drive, a USB 3 stick and a remote PC via a 1 Gbps LAN, along with MP-IntStress using four threads. The environment was monitored using RPiHeatMHzVolts2, vmstat for drive activity and CPU MHz, and sar -n for network traffic. Commands used and results are provided below. Stress tests are generally based on executing a fixed set of activities, where completion times can vary. Hence, the provided results are extrapolated approximations, with drive speeds the average for a particular activity.
All stress tests ran to completion without detecting any errors. CPU utilisation was around 90% of four cores but CPU throttling still occurred, with temperatures up to 86°C (and possibly not enough throttling). Performance measured by the stress tests was broadly in line with the system vmstat and sar measurements. In order to indicate which activity suffered from the most degradation, performance of standalone runs are also provided. It seems that LAN traffic was given a higher priority, with no speed reduction, followed by the main SD drive. Worst was the CPU bound program, probably suffering from a lower priority besides throttling.
------ MB/second ------
Secs Main USB 3 1Gbps MP-Int MHz °C
Drive Drive LAN Stress
0 1500 55
30 11.9 38.0 42.3 13116 1500 66
60 11.9 44.1 32.8 13063 1500 73
90 28.1 44.1 32.8 13615 1500 75
120 28.1 44.1 32.8 13734 1500 81
150 28.1 44.1 32.8 13370 1500 83
180 28.1 44.1 32.8 13555 1000 82
210 28.1 44.1 32.8 13285 1000 82
240 28.1 44.1 32.8 13194 1000 82
270 28.1 44.1 32.8 13022 1000 83
300 28.1 44.1 32.8 13316 1000 82
330 28.1 44.1 32.8 13615 1000 82
360 28.1 44.1 32.8 13677 1000 84
390 28.1 44.1 32.8 13315 1000 83
420 28.1 44.1 32.8 13273 1000 82
450 28.1 44.1 32.8 13117 1000 83
480 28.1 44.1 32.8 12860 1000 83
510 28.1 44.1 32.8 12370 1000 83
540 28.1 44.1 32.8 11863 1000 84
570 28.1 44.1 32.8 11550 1000 84
600 28.1 44.1 32.8 11312 1000 82
630 28.1 44.1 32.7 10895 1000 83
660 28.1 54.0 32.7 10696 1000 83
690 29.7 54.0 32.7 10479 1000 84
720 29.7 54.0 32.7 10223 750 84
750 29.7 54.0 32.7 10227 1000 85
780 29.7 54.0 32.7 10413 750 84
810 29.7 54.0 10090 750 86
840 29.7 9952 1000 84
Stand Alone
Max 33.4 68.6 32.3 22664
vmstat
procs -----------memory---------- --swap-- -----io---- -system- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
Start
6 2 0 3499820 45700 271552 0 0 12409 32193 16450 13425 54 24 20 2 0
2 2 0 3503956 45776 264632 0 0 46811 12381 27174 16714 68 23 3 5 0
4 2 0 3506080 45816 264348 0 0 76271 248 25885 16188 64 22 7 7 0
Read 1
5 2 0 3502984 45992 264844 0 0 75473 5 18777 14118 67 24 3 6 0
5 2 0 3504888 46032 264884 0 0 74726 7 18907 14631 66 25 4 5 0
Read 2
6 2 0 3503236 46544 265452 0 0 86628 7 17180 15114 62 28 4 6 0
4 2 0 3501964 46592 265452 0 0 80815 6 15395 14321 68 28 2 2 0
Ethernet Read sar -n DEV
rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
24841.37 6883.90 36206.23 505.50 0.00 0.00 0.03 29.66
|